期待されるキャリブレーションエラー(ECE)- ステップバイステップの視覚的な説明
ECEの視覚的な説明
シンプルな例とPythonコードで
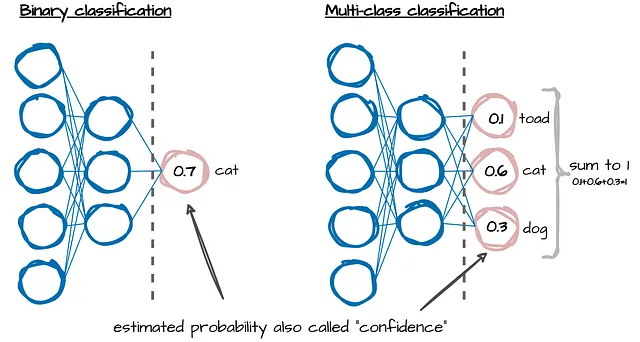
分類タスクでは、機械学習モデルは推定確率または信頼度(上記の画像参照)を出力します。これらは、モデルがラベル予測についてどれだけ確信を持っているかを示します。しかし、ほとんどのモデルでは、これらの信頼度は予測されるイベントの真の頻度とは一致していません。これらはキャリブレーションが必要です!
モデルのキャリブレーションは、モデルの予測を真の確率と一致させ、モデルの予測が信頼性と精度を持つことを確認することを目指しています(モデルのキャリブレーションの重要性については、このブログ記事を参照してください)。
では、モデルのキャリブレーションは重要ですが、どのように測定しますか?いくつかのオプションがありますが、この記事の目的と焦点は、モデルのキャリブレーションを評価するための単純なかつ十分な指標である「期待キャリブレーションエラー(ECE)」について説明し、実行することです。これにより、異なるモデルを比較するために使用できる単一の値が得られます。
この記事では、論文「On Calibration of Modern Neural Networks」で説明されているECEの式に従って解説します。簡単にするために、2値のターゲットを持つ9つのデータポイントの小さな例を見てみましょう。そして、この簡単な例をPythonでコーディングし、最後に、マルチクラス分類にも適用するためのコードの追加方法についても説明します。
定義
ECEは、モデルの推定された「確率」が真の(観測された)確率と一致しているかどうかを、正解率(acc)と信頼度(conf)の絶対差の重み付き平均で測定します:
この指標では、データをM個の等間隔のビンに分割します。ここで「ビン」を表すのにBを、ビン番号を表すのにmを使用します。後でB、|Bₘ|、acc(Bₘ)、およびconf(Bₘ)といったこの式の個々の部分についても詳しく説明します。まず、ステップバイステップで式を理解しやすくするために、例を見てみましょう。
例
ラベル1を予測するための推定された確率または「信頼度」(pᵢ)を持つ9つのサンプルがあります。もしも…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




