「オンライン大規模な推薦のためのデュアル拡張二つのタワーモデル」
「デュアル拡張二つのタワーモデルを活用したオンライン大規模推薦システム」
美团的双塔检索模型深入解析
推荐系统是旨在为用户提供个性化建议的算法。这些系统在各个领域中被应用,帮助用户发现相关的物品,如产品(类似亚马逊的电子商务平台)、其他用户(类似X和LinkedIn的社交媒体)、内容(类似X、Instagram和Reddit的社交媒体)或信息(类似X、Reddit的新闻应用或社交媒体平台,如VoAGI和Quora),根据他们的偏好、行为或上下文。推荐系统旨在通过提供个性化和定向的建议来增强用户体验,最终促进决策和参与。一般来说,推荐系统由检索实体(物品、用户、信息)和对检索实体进行排名组成。

本文将讨论美团提出的“在线大规模推荐的双增容双塔模型”,这是一个增强版的常用双塔模型,用于推荐系统。
双塔模型
首先让我们讨论双塔模型。该术语“双塔”来源于架构中的两个独立的“塔”,每个实体一个。双塔模型旨在分别捕捉和学习两个不同实体的嵌入。这些实体可以是“用户”-“用户”、“用户”-“物品”或“搜索查询”-“物品”,具体根据使用情况而定。模型由两个带有嵌入层的塔组成,紧接着是一个交互层,用于捕捉它们之间的关系,最后是一个输出层用于生成推荐得分。
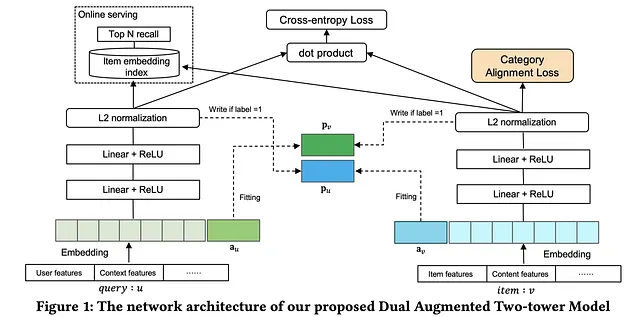
原始双塔模型的一个缺点是两个实体之间缺乏交互。除了最终的交互层,两个实体之间没有任何交互,其中它们各自的嵌入被用于计算余弦相似度等相似度度量。该论文通过引入一种新颖的自适应模仿机制解决了这个问题。该论文还提供了一种解决类别不平衡问题的解决方案。在许多使用情况下,如电子商务,某些类别可能有更多的物品,并且因此用户之间的互动也更多,而某些类别可能只有较少的物品和较少的用户互动。该论文引入了一种类别对齐损失以减轻类别不平衡对生成的推荐结果的影响。以下图示展示了网络架构。
|  |
问题陈述
让我们以“搜索查询”-“物品”为例来讨论。我们已经给定一组N个查询u_i (i = 1, 2, ..., N),一组M个物品v_j (j = 1, 2, ..., M),以及查询-物品反馈矩阵R。矩阵R是一个二进制矩阵,R_ij = 1表示对应查询u_i和物品v_j之间有正反馈,R_ij = 0表示没有反馈。目标是根据用户提供的查询,从一个庞大的物品语料库中检索出一定数量的候选物品。
双增容双塔模型
双增容双塔(DAT)模型由以下组件组成
- 嵌入层 – 与双塔模型类似,每个查询或物品特征都被转换为其嵌入表示(通常是稀疏的)。这些特征可以是用户/物品特征、上下文/内容特征等等。
- 双增容层 – 对于特定查询和候选物品,它们的增容向量
a_u和a_v被创建并连接到它们各自的特征嵌入中。当训练和学习后,我们期望增容向量不仅包含当前查询和物品的信息,还包含它们历史正反馈交互的信息。下图展示了连接后的输入嵌入的示例。

- フィードフォワード層 — 連結埋め込み
z_uとz_vは、フィードフォワード層を通過します。各タワーの出力は、クエリp_uとアイテムp_vの低次元表現です。L2正規化が行われ、その内積が続きます。モデルの出力はs(u, v) = <p_u, p_v>です。得られた出力は、与えられたクエリ-アイテムペアのスコアと見なされます。 - 適応的ミミックメカニズム(AMM) — 拡張ベクトル
a_uとa_vは、ミミック損失を使用して学習されます。ミミック損失は、拡張ベクトルを使用して他のタワーの対応するクエリまたはアイテムのすべての正の相互作用に適合させることを目指しています。ラベルがy = 1の場合、a_vはp_uに近づき、a_uはp_vに近づきます。この場合、損失関数はそれぞれa_vとp_u、a_uとp_vの間の距離を減らすことを目指します。ラベルがy = 0の場合、損失項は0となります。拡張ベクトルは1つのタワーで使用され、クエリ/アイテムの埋め込みは他のタワーから生成されます。つまり、拡張ベクトルは、クエリまたはアイテムが他のタワーから一致する可能性があるハイレベルの情報を要約します。ミミック損失はa_uとa_vを更新するため、p_uとp_vの値を固定する必要があります。

- カテゴリアラインメント — 著者によれば、2タワーモデルは異なるカテゴリに対して異なるパフォーマンスを発揮します。アイテム数が比較的少ないカテゴリでは、パフォーマンスが大幅に低下します。この問題に対処するために、彼らはカテゴリアラインメント損失(CAL)を導入しました。これにより、データ量の多いカテゴリで学習された知識を他のカテゴリに転送します。各バッチごとに、CALはそのバッチ内の多数のカテゴリアイテムの共分散行列
C(S^major)とそのバッチ内の他のカテゴリアイテムの共分散行列C(S^i)のフロベニウスノルムの総和として定義されます。この損失は、共分散(2次統計量)がすべてのカテゴリ間で一貫していることを保証します。なお、アイテムの埋め込みp_vを使用して共分散行列を計算します。

モデルの訓練
この問題はバイナリ分類タスクとしてモデル化されます。取得されたアイテムが関連するかどうかを判断します。トレーニング中に、タプル{u_i, v_j, R_ij=y}がモデルに供給されます。トレーニングでは、1つのバッチの入力は、クエリ-アイテムの正のペア(ラベルy = 1)とS個のランダムにサンプリングされたクエリ-アイテムの負のペア(ラベルy = 0)で構成されます。ここでクロスエントロピー損失が使用されます。

最終の損失関数は以下のようになります –

実装の詳細
埋め込みは、次元が256、128、32の3つの完全接続された順送り層を使用して32の次元に縮小されました。増強ベクトルの次元も32に設定されました。著者は自分たちのメイツアンデータセットと公開されているAmazon Booksデータセットで実験を行いました。

結果と評価
評価には、HitRate@KとMean Reciprocal Rank (MRR)が使用されました。Kは50と100に設定されました。大規模なテストインスタンスのため、著者はMRRを10の倍数でスケーリングしました。
- HitRate@K — 真の陽性の推薦がトップKの推薦内に見つかる割合を測定するメトリックです。
- Mean Reciprocal Rank (MRR) — 最初の正しい推薦の逆順位の平均を計算して得られるメトリックです。
次の表は、DATモデルと行列因子分解モデル、2塔モデル、およびYouTubeDNNなどの他のモデルの結果をまとめ、比較しています。DATはAMMとCALの有効性を示し、最も優れた性能を発揮しました。

著者は増強ベクトルの次元を調整し、パフォーマンスの変化を観察しました。以下のプロットで結果を観察できます。

上記の2つの結果はオフラインでの研究に基づいています。著者はモデルのパフォーマンスを以下のメトリックで観察しました。60万人のユーザーを1週間にわたり対象とした実際のトラフィックを処理するためにモデルを展開しました。
- クリックスルー率(CTR) — アイテムをクリックしたユーザーの割合を測定するメトリックで、魅力的なコンテンツの有効性を示します。
- 総商品価値(GMV) — プラットフォームを通じて販売された商品またはサービスの総価値を表すメトリックです。
ここでは、オリジナルの2塔モデルがベースラインとして選ばれました。両モデルとも100個の候補アイテムを取得します。候補の検索は近似最近傍探索を使用して行われます。取得したアイテムは公平な比較のため、同じランキングアルゴリズムに供給されます。DATモデルはベースラインよりも大幅に優れており、CTRおよびGMVの平均改善率はそれぞれ4.17%と3.46%です。

まとめると、Dual Augmented Two-towerモデルはクロスタワーディープインタラクションを容易にし、不均衡なカテゴリデータのためにより良い表現を生成することを目指しています。これにより、HitRate@KやMRRなどの検索メトリック、CTRやGMVなどのランキングメトリックの改善が図られます。
この記事が有益であると感じていただけることを願っています。オリジナルの論文へのリンクはこちらです — オンライン大規模推薦に対するDual Augmented Two-tower Model (dlp-kdd.github.io)。
お読みいただき、ありがとうございます!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
