ドメイン適応:事前に学習済みのNLPモデルの微調整
Domain Adaptation Fine-tuning Pretrained NLP Models
ハンズオンチュートリアル
どのドメインにも適用可能な事前学習済みNLPモデルのファインチューニングのステップバイステップガイド
前書き: この記事は、与えられたトピックに関する情報の要約を提供します。オリジナルの研究とは考えられません。この記事に含まれる情報とコードは、過去に私がオンラインの記事、研究論文、書籍、オープンソースのコードから読んだり見たりしたものに影響を受けることがあります。
共著者: ビリー・ハインズ
目次
- はじめに
- 理論的なフレームワーク
- データの概要
- 出発点: ベースラインモデル
- モデルのファインチューニング
- 結果の評価
- まとめ
はじめに
現代の世界では、事前学習済みのNLPモデルの利用可能性により、深層学習技術を用いたテキストデータの解釈が大幅に簡素化されました。しかし、これらのモデルは一般的なタスクには優れていますが、特定のドメインに適応性が欠けることがしばしばあります。この包括的なガイドでは、特定のドメインでのパフォーマンス向上を実現するために、事前学習済みのNLPモデルのファインチューニングのプロセスを解説します。
動機
BERTやUniversal Sentence Encoder(USE)などの事前学習済みのNLPモデルは、言語の複雑さを捉えるのには効果的ですが、トレーニングに用いられるデータセットの多様性のため、特定のドメインにおける応用では限定的なパフォーマンスしか発揮できません。特定のドメイン内における関係の分析では、この制約が明確になります。
例えば、雇用データを扱う場合、モデルが「データサイエンティスト」と「機械学習エンジニア」の役割の近接性や、「Python」と「TensorFlow」の強い関連性を認識することを期待します。しかし、汎用モデルではこれらの微妙な関係を見逃すことが多いのです。
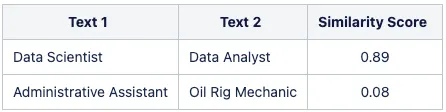
以下の表は、ベースのマルチリンガルUniversal Sentence Encoderモデルから得られる類似性の相違点を示しています:

この問題に対処するために、高品質な特定ドメインのデータセットを用いて事前学習済みモデルをファインチューニングすることができます。この適応プロセスにより、モデルのパフォーマンスと精度が大幅に向上し、NLPモデルの潜在能力を完全に引き出すことができます。
大規模な事前学習済みNLPモデルを扱う場合、まずベースモデルを展開し、具体的な問題に対してそのパフォーマンスが不十分である場合にのみファインチューニングを検討することをお勧めします。
このチュートリアルでは、容易にアクセス可能なオープンソースデータを使用して、Universal Sentence Encoder(USE)モデルのファインチューニングに焦点を当てています。
理論的な概要
MLモデルのファインチューニングは、教師あり学習や強化学習など、さまざまな戦略を用いて行うことができます。このチュートリアルでは、ファインチューニングプロセスにおけるワンショット学習アプローチとシャルコフアーキテクチャに焦点を当てます。
方法論
このチュートリアルでは、シャルコフニューラルネットワークを利用します。シャルコフニューラルネットワークは、特定のタイプの人工ニューラルネットワークです。このネットワークは、2つの異なる入力ベクトルを同時に処理し、比較可能な出力ベクトルを計算する際に共有される重みを活用します。ワンショット学習から着想を得たこのアプローチは、意味的な類似性を捉えるのに特に効果的であり、より長い訓練時間が必要な場合や確率的な出力が欠ける場合もあります。
シャルコフニューラルネットワークは、関連する概念が近くに配置される「埋め込み空間」を作成し、モデルが意味的な関係をよりよく識別できるようにします。
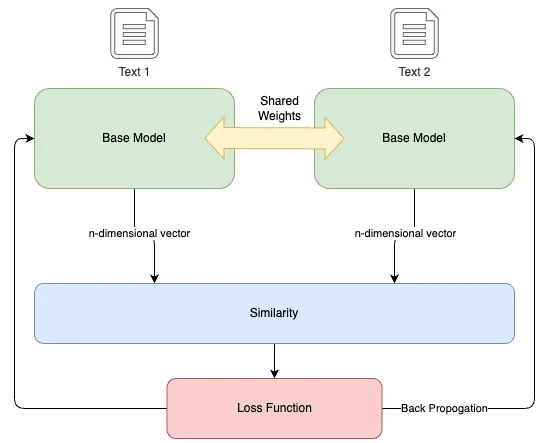
- ツインブランチと共有ウェイト:このアーキテクチャは、共有ウェイトを持つ埋め込み層を含む2つの同一のブランチで構成されています。これらのデュアルブランチは、類似または非類似の2つの入力を同時に処理します。
- 類似性と変換:入力は事前学習済みのNLPモデルを使用してベクトル埋め込みに変換されます。その後、アーキテクチャはベクトル間の類似性を計算します。類似性スコアは、-1から1の範囲で、2つのベクトル間の角度距離を定量化し、それらの意味的な類似性のメトリックとして機能します。
- コントラスティブロスと学習:モデルの学習は、「コントラスティブロス」と呼ばれるものによってガイドされます。これは、期待される出力(トレーニングデータからの類似性スコア)と計算された類似性との差です。このロスは、モデルのウェイトの調整をガイドし、ロスを最小化し学習された埋め込みの品質を向上させます。
ワンショット学習、シャーレンアーキテクチャ、およびコントラスティブロスについて詳しくは、以下のリソースを参照してください:
Siameseニューラルネットワークアーキテクチャのやさしい紹介
Siameseニューラルネットワークアーキテクチャ:概要と主要な概念の例による説明 | ProjectPro
www.projectpro.io
ワンショット学習とは? — TechTalks
ワンショット学習は、ディープラーニングアルゴリズムが2つの画像の類似性と差異を測定することを可能にします。
bdtechtalks.com
コントラスティブロスの説明
コントラスティブロスは、最近のいくつかの論文で使用され、教師なし学習における最先端の結果を示しています…
towardsdatascience.com
完全なコードはGitHubのJupyter Notebookとして利用できます
データの概要
この方法を使用して事前学習済みのNLPモデルを微調整するためのトレーニングデータは、テキスト文字列のペアとそれらの間の類似性スコアで構成される必要があります。
トレーニングデータの形式は以下のようになります:
このチュートリアルでは、ESCO分類データセットから取得したデータセットを使用し、さまざまなデータ要素間の関係に基づいて類似性スコアを生成するために変換されました。
トレーニングデータの準備は、微調整プロセスの重要なステップです。必要なデータとそれを指定された形式に変換する方法にアクセスできるものと想定されています。この記事の焦点は微調整プロセスをデモンストレーションすることですので、ESCOデータセットを使用してデータを生成した詳細は省略します。
ESCOデータセットは、自動補完、提案システム、求人検索アルゴリズム、求人マッチングアルゴリズムなどのさまざまなアプリケーションの基盤として開発者が自由に利用できるように提供されています。このチュートリアルで使用するデータセットは変換され、サンプルとして提供されており、目的に制約なく使用できます。
では、トレーニングデータを調べてみましょう:
import pandas as pd# CSVファイルをpandasのDataFrameに読み込むdata = pd.read_csv("./data/training_data.csv")# ヘッドを表示data.head()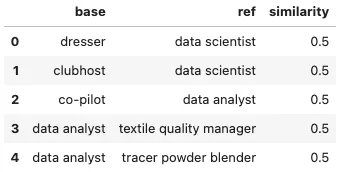
出発点:ベースラインモデル
まず、マルチリンガルユニバーサルセンテンスエンコーダをベースラインモデルとして確立します。微調整プロセスに進む前に、このベースラインを設定することが重要です。
このチュートリアルでは、STSベンチマークとサンプル類似度の視覚化を使用して、微調整プロセスを通じて達成された変更と改善を評価するためのメトリクスとして使用します。
STSベンチマークデータセットは、英語の文のペアで、それぞれが類似度スコアと関連付けられています。モデルのトレーニングプロセス中に、このベンチマークセットでモデルのパフォーマンスを評価します。各トレーニングランの持続スコアは、予測された類似度スコアとデータセット内の実際の類似度スコアのピアソン相関です。
これらのスコアは、モデルがコンテキスト固有のトレーニングデータで微調整されるにつれて、あるレベルの一般化を維持することを保証します。
# TensorFlow HubからUniversal Sentence Encoder Multilingualモジュールをロードします。base_model_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual/3"base_model = tf.keras.Sequential([ hub.KerasLayer(base_model_url, input_shape=[], dtype=tf.string, trainable=False)])# テスト文のリストを定義します。これらの文はさまざまな職種を表します。test_text = ['データサイエンティスト', 'データアナリスト', 'データエンジニア', 'ナースプラクティショナー', '登録看護師', '医療アシスタント', 'ソーシャルメディアマネージャー', 'マーケティングストラテジスト', '製品マーケティングマネージャー']# テスト文の埋め込みを作成します。# np.array()関数は結果をnumpy配列に変換するために使用されます。# .tolist()関数はnumpy配列をリストに変換するために使用されます。vectors = np.array(base_model.predict(test_text)).tolist()# plot_similarity関数を呼び出して類似度プロットを作成します。plot_similarity(test_text, vectors, 90, "base model")# ベースモデルのSTSベンチマークスコアを計算します。pearsonr = sts_benchmark(base_model)print("STSベンチマーク: " + str(pearsonr))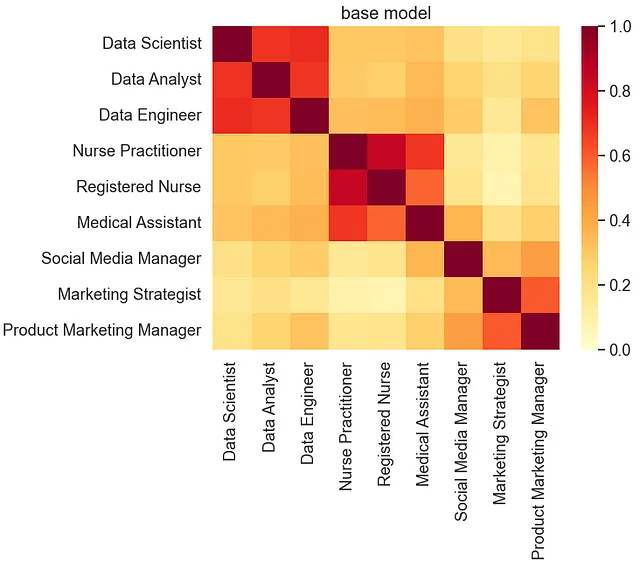
STSベンチマーク(dev):0.8325
モデルの微調整
次のステップでは、ベースラインモデルを使用してシャムモデルアーキテクチャを構築し、ドメイン固有のデータでモデルを微調整します。
# 事前学習済みのワード埋め込みモデルをロードします。embedding_layer = hub.load(base_model_url)# ロードした埋め込みモデルからKerasレイヤーを作成します。shared_embedding_layer = hub.KerasLayer(embedding_layer, trainable=True)# モデルへの入力を定義します。left_input = keras.Input(shape=(), dtype=tf.string)right_input = keras.Input(shape=(), dtype=tf.string)# 入力を共有の埋め込みレイヤーを通じて渡します。embedding_left_output = shared_embedding_layer(left_input)embedding_right_output = shared_embedding_layer(right_input)# 埋め込みベクトル間のコサイン類似度を計算します。cosine_similarity = tf.keras.layers.Dot(axes=-1, normalize=True)( [embedding_left_output, embedding_right_output])# コサイン類似度を角度距離に変換します。pi = tf.constant(math.pi, dtype=tf.float32)clip_cosine_similarities = tf.clip_by_value( cosine_similarity, -0.99999, 0.99999)acos_distance = 1.0 - (tf.acos(clip_cosine_similarities) / pi)# モデルをパッケージ化します。encoder = tf.keras.Model([left_input, right_input], acos_distance)# モデルをコンパイルします。encoder.compile( optimizer=tf.keras.optimizers.Adam( learning_rate=0.00001, beta_1=0.9, beta_2=0.9999, epsilon=0.0000001, amsgrad=False, clipnorm=1.0, name="Adam", ), loss=tf.keras.losses.MeanSquaredError( reduction=keras.losses.Reduction.AUTO, name="mean_squared_error" ), metrics=[ tf.keras.metrics.MeanAbsoluteError(), tf.keras.metrics.MeanAbsolutePercentageError(), ],)# モデルの概要を表示します。encoder.summary()
モデルの適合
# 早期停止コールバックを定義します。early_stop = keras.callbacks.EarlyStopping( monitor="loss", patience=3, min_delta=0.001)# TensorBoardコールバックを定義します。logdir = os.path.join(".", "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S"))tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)# モデルの入力を定義します。left_inputs, right_inputs, similarity = process_model_input(data)# エンコーダーモデルをトレーニングします。history = encoder.fit( [left_inputs, right_inputs], similarity, batch_size=8, epochs=20, validation_split=0.2, callbacks=[early_stop, tensorboard_callback],)# モデルの入力を定義します。inputs = keras.Input(shape=[], dtype=tf.string)# 入力を埋め込みレイヤーを通じて渡します。embedding = hub.KerasLayer(embedding_layer)(inputs)# チューニングされたモデルを作成します。tuned_model = keras.Model(inputs=inputs, outputs=embedding)評価
ファインチューニングされたモデルができたので、再評価を行い、結果をベースモデルと比較しましょう。
# テストテキストリストの文に埋め込みを作成します。 # np.array()関数は結果をnumpy配列に変換するために使用されます。 # .tolist()関数はnumpy配列をリストに変換するために使用されます。 # リストは扱いやすいかもしれません。vectors = np.array(tuned_model.predict(test_text)).tolist()# 類似性プロットを作成するためにplot_similarity関数を呼び出します。plot_similarity(test_text, vectors, 90, "調整済みモデル")# チューニングされたモデルのSTSベンチマークスコアを計算します。pearsonr = sts_benchmark(tuned_model)print("STSベンチマーク: " + str(pearsonr))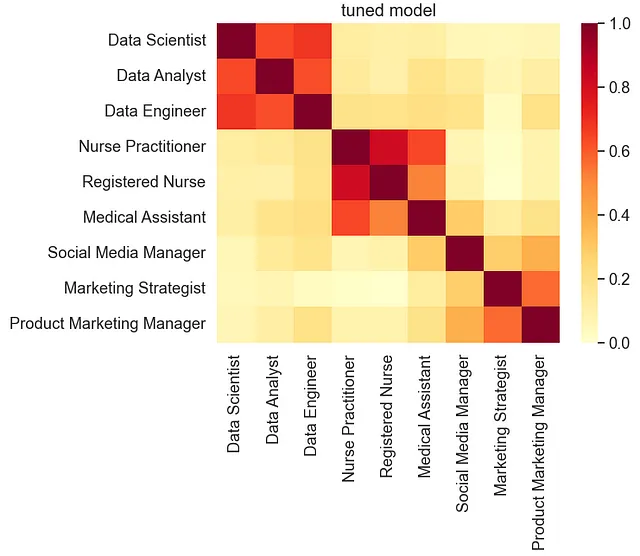
STSベンチマーク(dev):0.8349
比較的小さなデータセットでモデルをファインチューニングした結果、STSベンチマークスコアはベースモデルと同等であり、チューニングされたモデルは引き続き一般化された性能を持っていることを示しています。しかし、類似性の可視化は類似したタイトル間の類似性スコアの強化と、非類似なタイトルのスコアの低下を示しています。
まとめ
ドメイン適応のために事前学習されたNLPモデルをファインチューニングすることは、特定の文脈での性能と精度を向上させる強力な技術です。品質の高いドメイン固有のデータセットを活用し、シャムニューラルネットワークを活用することで、モデルの意味的な類似性の捕捉能力を向上させることができます。
このチュートリアルでは、Universal Sentence Encoder(USE)モデルを例に挙げ、ファインチューニングのプロセスをステップバイステップで説明しました。理論的なフレームワーク、データの準備、ベースモデルの評価、実際のファインチューニングプロセスについて探求しました。結果は、ドメイン内の類似性スコアを強化するファインチューニングの有効性を示しています。
このアプローチを参考にして、特定のドメインに適応させることで、事前学習されたNLPモデルのフルポテンシャルを引き出し、自然言語処理タスクでより良い結果を得ることができます。
お読みいただきありがとうございます。フィードバックがありましたら、この投稿にコメントするか、LinkedInでメッセージを送信するか、メールでご連絡ください(smhkapadia[at]gmail.com)
この記事がお気に召しましたら、他の記事もご覧ください
トピックモデルの評価:潜在ディリクレ配分(LDA)
解釈可能なトピックモデルの構築のステップバイステップガイド
towardsdatascience.com
自然言語処理の進化
言語モデルの発展の歴史的な視点
VoAGI.com
Pythonにおける推薦システム:LightFM
LightFMを使用したPythonでの推薦システムのステップバイステップガイド
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Stack Overflowで最もよく尋ねられるPythonリストの10の質問
- Pythonを使用したデータのスケーリング
- Metaphy LabsのAIエバンジェリストに会いましょう
- 今日、開発者の70%がAIを受け入れています:現在のテックの環境での大型言語モデル、LangChain、およびベクトルデータベースの台頭について探求する
- マイクロソフトの研究者たちは、ラベル付きトレーニングデータを使用せずにパレート最適な自己監督を用いたLLMキャリブレーションの新しいフレームワークを提案しています
- AI、デジタルツインが次世代の気候研究イノベーションを解き放つ
- HTMLの要約:IIoTデータのプライバシー保護のためのGANとDPのハイブリッドアプローチ
