「雨は雨を予測するのか?米国の気象データと今日と明日の雨の相関関係」
Does rain predict rain? Correlation between US weather data and today's and tomorrow's rainfall.
有用な気候データセットの紹介と地球温暖化予測の検証

概要
ボストンでの6月と7月の陰鬱な期間中、私たちの家族が楽しいことをする予定のたびに雨が降っているように思えました。私たちは自分たちが雨のパターンにはまっているのではないかと思い、次の日も雨が降る可能性が高いのかと尋ねました。私は、この質問は利用可能な天気データを使って簡単に答えることができると気づきました。
この記事では、私が使用した米国の気象データセット、データを分析するために書いたPython/pandasプログラム、そして結果を紹介します。要するに、長い雨の期間は次の日に雨が降りやすいことを強く予測します。そして驚くことに、雨の期間が長いほど、次の日に雨が降る可能性が高くなります。結果はまた、地球温暖化モデルの予測を証明しています-以前の年よりも雨が多く降っているのです。
データ
米国海洋大気庁(NOAA)からの降水に関する2つの主要なデータセットがあります。私はHourly Precipitation Data(HPD)を使用しました。説明ページは一般的に役立ちますが、データセットへのリンクが間違っており、古いバージョンを指しています。新しいデータセットはこちらで、1940年から2022年の期間をカバーしています(2023年のデータが追加されます)。HPDは、米国全土の2000以上の観測所から得られた時間ごとの降水量の詳細なデータを持っています。データファイルには、各CSVファイルに1つの観測所のすべての年が含まれています。私は日別の合計のみを使用しましたが、将来の分析には時間ごとの情報も役立つかもしれません。
雨ではなく雪が降る場合はどうでしょうか?雪の蓄積量は溶かして同等の雨量を求めるため、HPDのすべてのデータには液体の雨、溶けた雪、スラッシュ、ひょうなど、すべてが含まれています。
類似の分析に使用できるもう1つの貴重なデータセットとして、Local Climatological Data(LCD)があります。LCDには降水量だけでなく、気温、日の出/日の入り、気圧、視程、風速、霧、煙、月間のまとめなど、さまざまな情報が含まれています。LCDは毎日更新されるため、前日のデータが含まれています。使用するには、統合表面データセット(ISD)の観測所番号をデコードする必要があります。
分析プログラム
雨の分析プログラムはPython/pandasで書かれています。コードはそのまま読めるように書かれていますが、いくつかの特定の機能について探求する価値があります。
プログラムはHPDのすべての観測所のリスト全体を読み取るか、テキストファイルから特定の観測所のリストを読み取ることができます。この機能は、前回の実行とまったく同じ観測所を使用しながら、さまざまなパラメータでプログラムを再実行する際に使用されます。
from rain_helpers import ALL_STATION_FILESSTATION_LIST_INPUT = "/Users/chuck/Desktop/Articles/hpd_stations_used_list_1940-1950.txt"ALL_STATIONS = True # すべての観測所を使用するか、特定のリストを使用するか?# すべての観測所を知っているか、特定のリストの観測所(通常はこのプログラムの前回の実行から)を選択します。if (ALL_STATIONS): station_files = ALL_STATION_FILESelse: with open(STATION_LIST_INPUT, 'r') as fp: data = fp.read() station_files = data.split("\n") fp.close()もう1つの便利な機能は、観測所ファイルのサブセットを選択できることです。デバッグのためにステーションの1/100でコードを非常に高速に実行したり、結果の正確な近似値として1/3などを使用したりできます。大数の法則によれば、1/3(約600の観測所)でのテスト結果は完全なデータセットとほぼ同じです。
SKIP_COUNT = 3 # 1 = スキップしない.for i in range (0, len(station_files), SKIP_COUNT): station_url = HPD_LOCAL_DIR + station_files[i] stationDF = pd.read_csv(station_url, sep=',', header='infer', dtype=str)もう1つの高速化のための改善点は、すべての観測所ファイルをローカルマシンにダウンロードしておくことで、NOAAから毎回取得する必要がなくなることです。フルセットは約20GBです。この余分なスペースがない場合でも、クラウドから読み取りながらコードは問題なく実行されます。
HPD_CLOUD_DIR = "https://www.ncei.noaa.gov/data/coop-hourly-precipitation/v2/access/" # 毎時降水量データ(HPD)HPD_LOCAL_DIR = "/Users/chuck/Desktop/Articles/NOAA/HPD/"station_url = HPD_LOCAL_DIR + station_files[i] # ローカルとクラウドの切り替えコードの最も難しい部分は、各日付を遡って前の日々が雨だったかどうかを確認することです。問題は、調べるデータがまさに同じDataFrame内にあることです。自己結合です。DataFrameをループして、各行ごとに前の日付を調べるのは誘惑されますが、大規模なデータ構造のループはどのプログラミング言語でもスタイルが悪く、特にpandasではそうです。私のコードは、DataFrameのスナップショットを撮り、各行に前の9つの日付(および明日の日付)を含むフィールドを作成し、それらのフィールドをスナップショットと結合してこの問題を解決します。
# 自己結合のためにスナップショットを取得します。結合後の混乱を避けるためにフィールド名を調整します。
stationCopyDF = stationDF
stationCopyDF = stationCopyDF[["STATION","DATE","DlySumToday"]] # 必要なものだけを保持します
stationCopyDF = stationCopyDF.rename({"DlySumToday":"DlySumOther", "DATE":"DATEother"}, axis='columns')
# 降雨を取り込むためのいくつかの他の日付を追加します。
stationDF["DATE_minus9"] = stationDF["DATE"] - pd.offsets.Day(9)
stationDF["DATE_minus8"] = stationDF["DATE"] - pd.offsets.Day(8)
...
stationDF["DATE_minus1"] = stationDF["DATE"] - pd.offsets.Day(1)
stationDF["DATE_plus1"] = stationDF["DATE"] + pd.offsets.Day(1)
# ベースレコードに他の降雨を結合します。何をしたかを明確にするために列名を調整します。
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_minus9"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySum9DaysAgo"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_minus8"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySum8DaysAgo"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])
....
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_minus1"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySum1DayAgo"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])
stationDF = stationDF.merge(stationCopyDF, how='inner', left_on=["STATION","DATE_plus1"], right_on = ["STATION","DATEother"])
stationDF = stationDF.rename({"DlySumOther":"DlySumTomorrow"}, axis='columns')
stationDF = stationDF.drop(columns=["DATEother"])各行の前日の降雨量を取得した後、コードは各降雨期間の長さを簡単に見つけることができます。注意すべきは、何日間雨が降っているかを計算する際に、今日も1日としてカウントされることです。
stationDF["DaysOfRain"] = 0
stationDF.loc[(stationDF["DlySumToday"] >= RAINY), "DaysOfRain"] = 1
stationDF.loc[(stationDF['DlySumToday'] >= RAINY) & (stationDF['DlySum1DayAgo'] >= RAINY), 'DaysOfRain'] = 2
stationDF.loc[(stationDF['DlySumToday'] >= RAINY) & (stationDF['DlySum1DayAgo'] >= RAINY) & (stationDF['DlySum2DaysAgo'] >= RAINY), 'DaysOfRain'] = 3
... など結果
2000年から2021年までの年を含む期間において、有効なデータを持つ1808のステーションがあり、8,967,394のデータポイント(日付、場所、降水量)があります。
- 全てのデータポイントの平均降雨量は0.0983インチ、つまり約1/10インチでした。
- 雨の日(≥ 0.5インチ)の割合は6.2%でした。
- 乾燥した日(≤ 0.05インチ)の割合は78.0%でした。
このプロジェクトの元の質問に対する答えは、
はい、雨の降る日は明日の雨を予測します。雨が降り続いている時間(最大8日間)が長いほど、再び雨が降る可能性が高くなります。
関連する結果もあります…
雨の降る日が明日の予想される雨の量を予測します。雨が降り続いている時間(最大7日間)が長いほど、明日の雨の量が増える可能性が高くなります。
2つのグラフがこの結果を示しています。
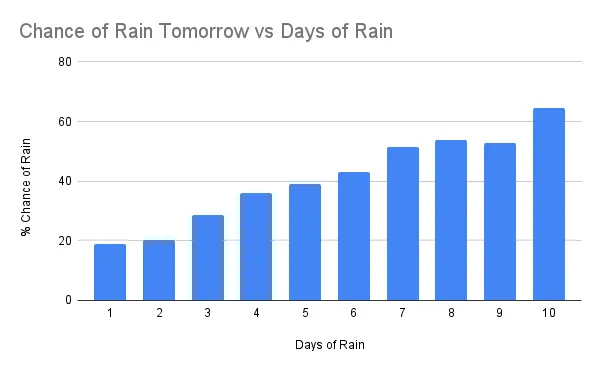

「雨の日」の異なる設定で実験しましたが、0.5インチから0.75インチ、1.0インチに変更しました。これらの変更により、雨の日がより多い雨を予測するという一般的な現象が示されますが、8日間を通じた完全な相関はありません。0.5インチという「雨の日」の定義が明日の雨を予測するための適切な基準のようです。
10日間連続で雨が降る可能性がある場所について疑問に思うかもしれません。全米で22年間にわたり、約900万のデータポイントがある中、そのような天候がわずか118回しかなかったです。その中には、ボカラトン、FL;サンファン、PR;カフナフォールズ、HI;カウマナ、HI;キハラニ、HI;パアケア、HI;パスカグーラ、MS;クイナルト、WA;クイルシーン、WAなどが含まれていました。
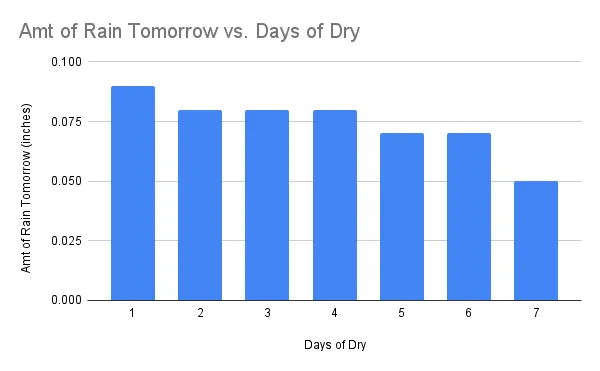
連続した乾燥した日(降雨量<0.05インチ)も次の日の乾燥によく関連していますが、予測は強くありません。なぜなら、明日の乾燥した日の可能性は非常に近いためです。明日の乾燥した日の確率は常に全体の平均である78%に近いです。

連続した乾燥した日は、次の日の予想される降雨量を比較的よく予測します。
気候変動
明らかな関連する質問は、ここで記述された結果が地球の気温上昇に伴って変化したかどうかです。私は1940年から1960年、1960年から1980年、1980年から2000年までの米国のデータについて同じ分析を行いました。
中心的な結果は同じです-雨の降る日がより多くの雨を予測します。各時間帯で数値はわずかに異なりますが、強い相関は変わりません。たとえば、1960年から1980年までの間には、有効なデータを持つ1388の観測所と6,807,917のデータポイントがあり、次の結果が得られました:
1日の雨の後に雨が降る割合= 17.3%2日の雨の後に雨が降る割合= 19.6%3日の雨の後に雨が降る割合= 27.4%4日の雨の後に雨が降る割合= 37.1%5日の雨の後に雨が降る割合= 43.8%6日の雨の後に雨が降る割合= 51.5%7日の雨の後に雨が降る割合= 52.4%
気候変動モデルによって予測されるより重要な帰結は、地球が温暖化するにつれて降雨量が増加することです。HPDデータセットは、少なくとも過去80年間にわたってこれを確認できます。
単純なアプローチは、現在の気候観測所(約2000箇所)すべてを取り上げ、各十年ごとの降雨データを調べることです。しかし、それを行う際に潜在的なバイアスがあります。過去80年間にわたり、気象観測所は徐々に追加されてきたため、現在は昔よりも気象観測所の数が多くなっています。新しい観測所が雨の多い場所に建設されている可能性があります。もしそれが事実なら、新しいデータはより多くの降雨を示すでしょうが、それは単に全体の観測所のセットが1940年のセットよりも雨の多い場所にあるためです。
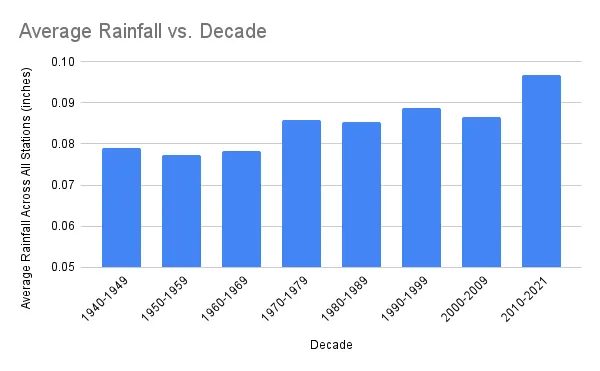
より正確なアプローチは、1940年代に降雨データのあった観測所のセットを見つけ、そのセットを各十年ごとに再利用することです。私のプログラムは各実行ごとに実際に使用された観測所のリストを生成できるため、これを行うことができます。まず、1940年から1950年までのデータを見つけ、次に生成された観測所リストを再利用して1950年から1960年、1960年から1970年などと続けます。これにより、各十年ごとに400Kから2.5Mのデータポイントを持つ約840の観測所が得られます。
各十年ごとの平均降雨量は非常に近いはずです。大数の法則によります。しかし、以下のグラフは、同じ集合の観測所で明らかに増加した降雨を示しています。これは、地球温暖化モデルの重要な予測を支持する注目すべき結果です。
詳細はこちら
https://www.weather.gov/rah/virtualtourlist — 米国国立気象局が予測を行う方法。
https://www.ncdc.noaa.gov/cdo-web/datasets — 米国海洋大気庁のデータセットの概要。
https://www.epa.gov/climate-indicators/climate-change-indicators-us-and-global-precipitation — 米国環境保護庁による気候変動による降水増加の報告書。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
