ドキュメント指向エージェント:ベクトルデータベース、LLMs、Langchain、FastAPI、およびDockerとの旅
Document-Oriented Agent Journey with Vector Databases, LLMs, Langchain, FastAPI, and Docker.
ChromaDB、Langchain、およびChatGPTの活用:大規模ドキュメントデータベースからの高度な応答と引用ソース
はじめに
ドキュメント指向エージェントは、ビジネスの世界で注目を集め始めています。企業はこれらのツールを活用して内部のドキュメントを活用し、ビジネスプロセスを強化しています。最近のマッキンゼーの報告書 [1] では、このトレンドを強調し、生成型AIが年間2.6-4.4兆ドルのグローバル経済を後押しし、現在の業務の70%を自動化できる可能性があると述べています。この調査では、顧客サービス、営業およびマーケティング、ソフトウェア開発が変革の影響を受ける主要なセクターとして特定されています。変化の大部分は、企業内でこれらの領域をパワーアップする情報が、ドキュメント指向エージェントなどのソリューションを介して従業員と顧客の両方によりアクセス可能になるという事実から生じています。
現在の技術では、まだいくつかの課題に直面しています。新しい大規模言語モデル(LLM)を考慮しても、100kトークンの制限があるため、モデルは依然として限られた文脈ウィンドウしか持っていません。100kトークンは高い数字のように思えますが、例えば顧客サービス部門をパワーアップしているデータベースのサイズを考えると、非常に少ない数字です。よくある問題の1つは、モデルの出力の不正確さです。本記事では、任意のサイズのドキュメントを処理し、検証可能な回答を提供できるドキュメント指向エージェントの構築手順をステップバイステップで説明します。
私たちはベクトルデータベースであるChromaDBを使用して、モデルのコンテキスト長の機能を強化し、Langchainを使用してアーキテクチャ内のさまざまなコンポーネントの統合を容易にします。 LLMとしては、OpenAIのchatGPTを使用しています。アプリケーションを提供したいので、ユーザーがエージェントと対話するためのエンドポイントを作成するためにFastAPIを使用しています。最後に、Dockerを使用してアプリケーションをコンテナ化し、さまざまな環境に簡単に展開できるようにしています。
いつものように、コードは私のGithubで利用できます。
- PythonのAsyncioをAiomultiprocessで強化しましょう:包括的なガイド
- 私が通常のRDBMSをベクトルデータベースに変換して埋め込みを保存する方法
- UCLAの研究者が、最新の気候データと機械学習モデルに簡単で標準化された方法でアクセスするためのPythonライブラリ「ClimateLearn」を開発しました
ベクトルデータベース:意味検索アプリケーションの重要なコア
ベクトルデータベースは、生成型AIの力を引き出すために不可欠です。この種のデータベースは、元のデータから豊富な意味情報を含むベクトル埋め込みを扱うために最適化されています。ベクトル埋め込みの複雑さに苦しむ従来のスカラーベースのデータベースとは異なり、ベクトルデータベースはこれらの埋め込みをインデックス化し、元のコンテンツと関連付けて、意味情報検索やAIアプリケーションにおける長期的なメモリなどの高度な機能を可能にします。
ベクトルデータベースは、FacebookのAI類似検索(FAISS)などのベクトルインデックスとは異なり、データの挿入、削除、および更新を許容し、関連するメタデータを保存し、完全な再インデックス化を必要とせずにリアルタイムのデータ更新をサポートします。再インデックス化は時間と計算リソースを消費するため、ベクトルデータベースとは異なります。
ベクトルデータベースは、クエリに最も近いベクトルを見つけるために類似性メトリックを使用します。最適化された検索のために、近似最近傍探索(ANN)アルゴリズムを使用します。このようなアルゴリズムの例としては、ランダムプロジェクション、プロダクト量子化、または階層的ナビゲーション可能なスモールワールドなどがあります。これらのアルゴリズムは元のベクトルを圧縮し、クエリ処理を高速化します。さらに、コサイン類似度、ユークリッド距離、および内積などの類似性測定を使用して、クエリに対して最も関連性の高い結果を比較および特定します。
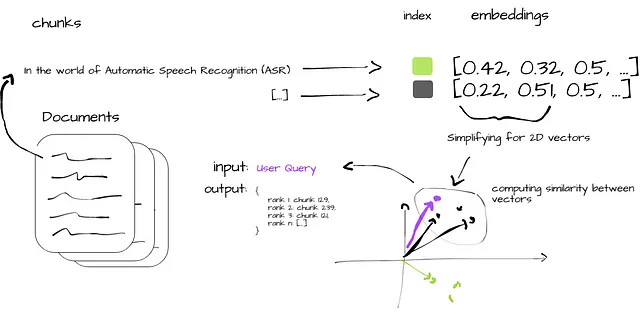
図2は、ベクトルデータベースにおける類似性検索プロセスを簡潔に示しています。生のドキュメントの取り込み(i)から始まり、データは管理可能なチャンク(ii)に分割され、ベクトル埋め込み(iii)に変換されます。これらの埋め込みは迅速な検索のためにインデックス化され(iv)、チャンクベクトルとユーザークエリの類似性メトリックが計算されます(v)。プロセスは、元のクエリに合わせてユーザーに洞察を提供する最も関連性の高いデータチャンクの出力によって終了します(vi)。
ドキュメント指向のエージェントの構築
まず、サーバーの起動時に必要なすべてのモデルとデータを読み込みます。
データは事前に定義されたディレクトリから読み込み、管理可能なチャンクに分割して処理します。これらのチャンクは、類似性検索手順から結果を取得したときにチャンクをLLMに渡すことができるように設計されています。このプロセスでは、DirectoryLoaderを使用してドキュメントをメモリにロードし、RecursiveCharacterTextSplitterを使用して管理可能なチャンクに分割します。デフォルトのチャンクサイズは1000文字で、チャンクの重複は20文字です。チャンクの重複により、チャンク間の文脈の連続性が確保され、チャンクの境界で意味のある文脈が失われるリスクが最小限に抑えられます。
def load_docs(directory: str): """ 指定されたディレクトリからドキュメントを読み込みます。 """ loader = DirectoryLoader(directory) documents = loader.load() return documentsdef split_docs(documents, chunk_size=1000, chunk_overlap=20): """ ドキュメントをチャンクに分割します。 """ text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) docs = text_splitter.split_documents(documents) return docs次に、SentenceTransformerEmbeddingsメソッドを使用してこれらのチャンクからベクトル埋め込みを生成し、ベクトルデータベースであるChromaDBにインデックスします。これらの埋め込みはデータベースに格納され、検索可能なデータとして機能します。データベースはメモリ上に存在せず、ディスク上に永続化されていることに注意してください。これにより、メモリのオーバーヘッドを削減することができます。次に、チャットモデルであるOpenAIのgpt-3.5-turboをロードします。これが私たちのLLMとして機能します。
@app.on_event("startup")async def startup_event(): """ サーバーが起動したら、必要なモデルとデータを一度に読み込みます。 """ app.directory = '/app/content/' app.documents = load_docs(app.directory) app.docs = split_docs(app.documents) app.embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2") app.persist_directory = "chroma_db" app.vectordb = Chroma.from_documents( documents=app.docs, embedding=app.embeddings, persist_directory=app.persist_directory ) app.vectordb.persist() app.model_name = "gpt-3.5-turbo" app.llm = ChatOpenAI(model_name=app.model_name) app.db = Chroma.from_documents(app.docs, app.embeddings) app.chain = load_qa_chain(app.llm, chain_type="stuff", verbose=True)最後に、「/query/{question}」エンドポイントはユーザーのクエリを受け取ります。質問を入力としてデータベース上で類似性検索を実行します。一致するドキュメントが存在する場合、それらはLLMに入力され、回答が生成されます。回答とソース(元のドキュメントとそのメタデータ)が返され、提供された情報が簡単に検証できるようになっています。
@app.get("/query/{question}")async def query_chain(question: str): """ 指定された質問でモデルにクエリを送信し、回答を返します。 """ matching_docs_score = app.db.similarity_search_with_score(question) if len(matching_docs_score) == 0: raise HTTPException(status_code=404, detail="一致するドキュメントが見つかりませんでした") matching_docs = [doc for doc, score in matching_docs_score] answer = app.chain.run(input_documents=matching_docs, question=question) # ソースを準備する sources = [{ "content": doc.page_content, "metadata": doc.metadata, "score": score } for doc, score in matching_docs_score] return {"answer": answer, "sources": sources}このアプリケーションはDockerを使用してコンテナ化されており、展開プラットフォームに関係なく、環境の統一性と分離を保証しています。以下のDockerfileにはセットアップの詳細が記載されています:
FROM python:3.9-busterWORKDIR /appCOPY . /appRUN pip install - no-cache-dir -r requirements.txtEXPOSE 1010CMD ["uvicorn", "main:app", " - host", "0.0.0.0", " - port", "1010"]アプリケーションはPython 3.9環境で実行されるため、必要なすべての依存関係をrequirements.txtファイルからインストールする必要があります:
langchain==0.0.221uvicorn==0.22.0fastapi==0.99.1unstructured==0.7.12sentence-transformers==2.2.2chromadb==0.3.26openai==0.27.8python-dotenv==1.0.0アプリケーションは、Uvicornを使用してポート1010で提供されます。
環境変数を設定する必要があることに注意してください。当社のアプリケーションは、ChatOpenAIモデルに対してOPENAI_API_KEYを必要とします。APIキーのような機密情報のベストプラクティスは、アプリケーションにハードコーディングするのではなく、環境変数として保存することです。python-dotenvパッケージを使用して、プロジェクトのルートにある.envファイルから環境変数を読み込みます。本番環境では、Dockerのシークレットやセキュアなボールトサービスなど、より安全な方法を使用することが望ましいです。
実験:ドキュメント指向エージェントの効果を理解する
実験の主な目標は、ドキュメント指向エージェントがユーザーのクエリに対して包括的かつ正確な応答を提供する能力を評価することでした。
私たちは、VoAGIの一連の記事を知識ベースとして使用しています。これらの記事は、さまざまなAIや機械学習のトピックをカバーしており、私たちのChromaベクトルデータベースに摂取され、インデックスされています。選択した記事は以下の通りです:
- 「Whisper JAX vs PyTorch:GPU上でのASRパフォーマンスの真実を明らかにする」
- 「1162の言語をサポートするMassively Multilingual Speech(MMS)モデルのテスト」
- 「最もパワフルなオープンソースLLMであるFalcon 40Bモデルの活用」
- 「言語学習モデルにおけるOpenAIの関数呼び出しの力:包括的なガイド」
これらの記事は管理可能なチャンクに分割され、ベクトル埋め込みに変換され、データベースにインデックスされ、エージェントの知識のバックボーンを形成しています。
ユーザーのクエリは、FastAPIを使用して実装され、Docker経由で展開されたアプリケーションのAPIエンドポイントを呼び出すことによって実行されました。実験に使用したクエリは次のとおりです:”Falcon-40bと商用利用はできますか?”。
curl --location 'http://0.0.0.0:1010/query/What is Falcon-40b and can I use it for commercial use'クエリに対する応答として、LLMはFalcon-40bの説明をし、商用利用が可能であることを確認しました。この情報は、記事「最もパワフルなオープンソースLLMであるFalcon 40Bモデルの活用」からの4つの異なるソースチャンクでバックアップされています。ソースチャンクは先述のように応答にも追加されており、ユーザーはLLMの回答を裏付ける元のテキストを確認することができます。また、ソースチャンクはクエリに対する関連性に基づいてスコア付けされており、エージェントの全体的な回答におけるそのセクションの重要性を示す別の視点を提供します。
{ "answer": "Falcon-40Bは、テクノロジーイノベーション研究所(TII)によって開発された最新の言語モデルです。これは、さまざまな言語理解タスクで優れたパフォーマンスを発揮するトランスフォーマーベースのモデルです。 Falcon-40Bの重要性は、TIIによって商用および研究利用のために無料で提供されていることです。これにより、開発者や研究者は特定のニーズに応じてモデルにアクセスして変更することができ、ロイヤルティなしで使用できます。ただし、Falcon-40Bは商用利用が可能ですが、Webデータでトレーニングされており、オンラインで一般的なバイアスやステレオタイプを持つ可能性があります。したがって、製品環境でFalcon-40Bを使用する際には、適切な緩和策を実装する必要があります。", "sources": [ { "content": "これがFalcon-40Bの重要性の所在です。先週末、テクノロジーイノベーション研究所(TII)は、Falcon-40Bが商用利用および研究利用のロイヤリティフリーとなったことを発表しました。これにより、プロプライエタリモデルの障壁が取り払われ、開発者や研究者は特定のニーズに応じて使用および変更できる最新の言語モデルに無料でアクセスできるようになりました。\n\nまた、Falcon-40Bモデルは、LLaMA、StableLM、RedPajama、MPTなどのモデルを上回り、OpenLLM Leaderboardで最もパフォーマンスの高いモデルになりました。このLeaderboardは、さまざまなLLMやチャットボットのパフォーマンスを追跡し、順位付けし、評価することで、その能力の明確で偏見のない指標を提供します。図1:Falcon-40BがOpenLLM Leaderboardを制覇している(画像の出典)\n\nいつものように、コードは私のGithubで利用できます。Falcon LLMはどのように開発されましたか?", "metadata": { "source": "/app/content/Harnessing the Falcon 40B Model, the Most Powerful Open-Source LLM.txt" }, "score": 1.045290231704712 }, { "content": "Falcon-40Bのデコーダブロックは、並列アテンション/MLP(マルチレイヤパーセプトロン)設計と2層の正規化を備えています。この構造は、モデルのスケーリングと計算速度の観点から利点を提供します。アテンションとMLPレイヤの並列化により、モデルは大量のデータを同時に処理する能力が向上し、トレーニング時間が短縮されます。さらに、2層の正規化の実装は、学習プロセスの安定化と内部共変量シフトに関連する問題の緩和に役立ち、より堅牢で信頼性の高いモデルを実現します。Falcon-40B-Instructを使用したチャット機能の実装\n\n私たちはFalcon-40B-Instructを使用しており、これはFalcon-40Bの新しいバリアントです。基本的には同じモデルですが、LoRA(大規模言語モデルの低ランク適応)というものとの混合で微調整されています。BaizeはChatGPTが自身と対話したり、Alpacaのデータを使用してパフォーマンスを向上させるために使用されるオープンソースのチャットモデルです。", "metadata": { "source": "/app/content/Harnessing the Falcon
結論
この記事では、ベクトルデータベースとオープンソースのツールの組み合わせを活用し、AIシステムで大規模なドキュメントを処理する際の課題に対処する解決策を構築しました。当社のアプローチは、ChromaDBとLangchainを使用し、OpenAIのChatGPTを活用して能力のあるドキュメント指向のエージェントを構築するものです。
私たちのアプローチにより、エージェントは大規模なデータベースからテキストのチャンクを検索・処理することで複雑なクエリに答えることができます。私たちの場合は、さまざまなAIのトピックに関するVoAGIの記事シリーズが対象です。エージェントの回答に加えて、ユーザーのクエリとの類似性に関する元のドキュメントのチャンクとそのスコアも返します。これは重要な機能であり、これらのエージェントは時に不正確な情報を提供することがあります。
大規模言語モデルクロニクル:NLPフロンティアの航海
この記事は「大規模言語モデルクロニクル:NLPフロンティアの航海」という新しい週刊記事シリーズの一部であり、さまざまなNLPタスクにおいて大規模モデルの力を活用する方法を探求します。最先端の技術に深入りすることで、開発者、研究者、愛好家がNLPの可能性を引き出し、新たな可能性を開拓できるよう支援することを目指しています。
これまでに公開された記事:
- ChatGPTを使用した最新のSpotifyリリースの要約
- FAISSとSentence Transformersを使用して数百万のドキュメントを高速推論でインデックスする大規模セマンティックサーチのマスタリング
- Whisper、WhisperX、およびPyAnnotateを使用した高度な音声データのトランスクリプションとダイアリゼーションの活用
- ASRのGPUパフォーマンスに関する真実を明らかにするWhisper JAX vs PyTorch
- 効率的なエンタープライズグレードの音声認識のためのVosk:評価と実装ガイド
- 1162言語をサポートする大規模多言語音声(MMS)モデルのテスト
- 最も強力なオープンソースLLMであるFalcon 40Bモデルの活用
- 言語学習モデルでのOpenAIの関数呼び出しのパワー:包括的なガイド
参考文献
[1] https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier#introduction
[2] FAISSとSentence Transformersを使用して数百万のドキュメントを高速推論でインデックスする大規模セマンティックサーチのマスタリング
お問い合わせ先:LinkedIn
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
