データサイエンティストのためのDockerチュートリアル
Dockerチュートリアル' for Data Scientists

Pythonと、pandasやscikit-learnなどのPythonデータ分析および機械学習ライブラリのスイートは、データサイエンスアプリケーションを簡単に開発できるようにサポートしてくれます。ただし、Pythonの依存関係管理は課題です。データサイエンスプロジェクトに取り組む際には、さまざまなライブラリをインストールし、使用しているライブラリのバージョンを追跡するなど、かなりの時間を費やす必要があります。
他の開発者があなたのコードを実行し、プロジェクトに貢献したい場合はどうでしょうか? 他の開発者がデータサイエンスアプリケーションを複製するためには、まず彼らのマシン上でプロジェクトの環境を設定する必要があります。コードを実行する前に、異なるライブラリバージョンなどの小さな違いでも、コードに破壊的な変更が生じる可能性があります。 そこで、Dockerが登場します。Dockerは開発プロセスを簡素化し、シームレスなコラボレーションを可能にします。
このガイドでは、Dockerの基礎を紹介し、Dockerを使用してデータサイエンスアプリケーションをコンテナ化する方法を学びます。
- 「データ分析のためのトップ10のAIツール」
- 「Gartner Market Guideに掲載されているDataOps.liveでDataOpsの成功を実現しましょう!」
- 「完璧なPythonデータ可視化のためのAIプロンプトエンジニアリングの5つの習慣」
Dockerとは何ですか?

Dockerは、ポータブルなアーティファクトである「イメージ」としてアプリケーションをビルドおよび共有するためのコンテナ化ツールです。
ソースコード以外にも、アプリケーションには依存関係、必要な設定、システムツールなどがあります。たとえば、データサイエンスプロジェクトでは、開発環境(できれば仮想環境内)に必要なライブラリをすべてインストールします。また、ライブラリがサポートするPythonの更新されたバージョンを使用していることも確認します。
ただし、別のマシンでアプリケーションを実行しようとすると、問題が発生する場合があります。これらの問題は、開発環境内の構成やライブラリのバージョンの不一致から生じることがよくあります。
Dockerを使用すると、アプリケーションとそれに必要な依存関係および設定をパッケージ化できます。つまり、ホストマシンの範囲内でアプリケーションに対して独立した、再現可能で一貫性のある環境を定義できます。
Dockerの基本:イメージ、コンテナ、およびレジストリ
いくつかの概念/用語について説明します:
Dockerイメージ
Dockerイメージは、アプリケーションのポータブルなアーティファクトです。
Dockerコンテナ
イメージを実行すると、コンテナ環境内でアプリケーションが実行されます。したがって、イメージの実行インスタンスはコンテナです。
Dockerレジストリ
Dockerレジストリは、Dockerイメージを保存および配布するためのシステムです。アプリケーションをDockerイメージにコンテナ化した後、イメージをレジストリにプッシュして開発者コミュニティで使用できるようにすることができます。DockerHubは最大のパブリックレジストリであり、すべてのイメージはデフォルトでDockerHubからプルされます。
Dockerは開発をどのように簡素化しますか?
コンテナはアプリケーションのために独立した環境を提供するため、他の開発者は自分のマシンにDockerをセットアップするだけで済みます。そして、単一のコマンドを使用してDockerイメージをプルし、コンテナを起動することができます。複雑なインストールの心配をせずに、リモートで
アプリケーションを開発する際には、同じアプリの複数のバージョンをビルドおよびテストすることも一般的です。Dockerを使用すると、同じ環境内で異なるコンテナ内で同じアプリの複数のバージョンを実行できます。
開発を簡素化するだけでなく、Dockerはデプロイメントも簡素化し、開発および運用チームが効果的にコラボレーションできるようにサポートします。サーバーサイドでは、運用チームは複雑なバージョンおよび依存関係の競合を解決するための時間をかける必要はありません。Dockerランタイムのセットアップさえあれば十分です
重要なDockerコマンド
このチュートリアルでは主に使用するいくつかの基本的なDockerコマンドを簡単に説明します。詳細な概要については、「12 Dockerコマンド:データサイエンティストが知っておくべきこと」を参照してください。
| コマンド | 機能 |
docker ps |
実行中のすべてのコンテナを一覧表示します |
docker pull イメージ名 |
デフォルトでDockerHubからイメージ名をプルします |
docker images |
利用可能なすべてのイメージを一覧表示します |
docker run イメージ名 |
イメージからコンテナを起動します |
docker start コンテナID |
停止したコンテナを再起動します |
docker stop コンテナID |
実行中のコンテナを停止します |
docker build パス |
Dockerfileの指示に従ってパスでイメージをビルドします |
注意: もしdockerグループをユーザーで作成していない場合は、すべてのコマンドの前にsudoを付けて実行してください。
Dockerを使用してデータサイエンスアプリをコンテナ化する方法
Dockerの基礎を学びましたので、学んだことを実践する時がきました。このセクションでは、Dockerを使用してシンプルなデータサイエンスアプリをコンテナ化します。
住宅価格予測モデル
次の線形回帰モデルを考えましょう。このモデルは入力特徴に基づいてターゲット値である中央の住宅価格を予測します。モデルはCaliforniaの住宅データセットを使用して構築されます:
# house_price_prediction.py
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Californiaの住宅データセットを読み込む
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# データセットをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特徴量を標準化する
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# モデルをトレーニングする
model = LinearRegression()
model.fit(X_train, y_train)
# テストセットで予測を行う
y_pred = model.predict(X_test)
# モデルを評価する
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"平均二乗誤差: {mse:.2f}")
print(f"R2スコア: {r2:.2f}")
scikit-learnが必要な依存関係であることを知っています。コードを見ると、データセットを読み込む際にas_frameをTrueに設定しています。そのため、pandasも必要です。そして、requirements.txtファイルは以下のようになります:
pandas==2.0
scikit-learn==1.2.2
Dockerfileを作成する
これまで、ソースコードファイルhouse_price_prediction.pyとrequirements.txtファイルがあります。これからアプリケーションからイメージをビルドする方法を定義する必要があります。Dockerfileは、アプリケーションのソースコードファイルからイメージをビルドするための定義を含むテキストドキュメントです。
では、Dockerfileとは何でしょうか?それはDockerイメージのビルド手順をステップバイステップで記述したテキストドキュメントです。
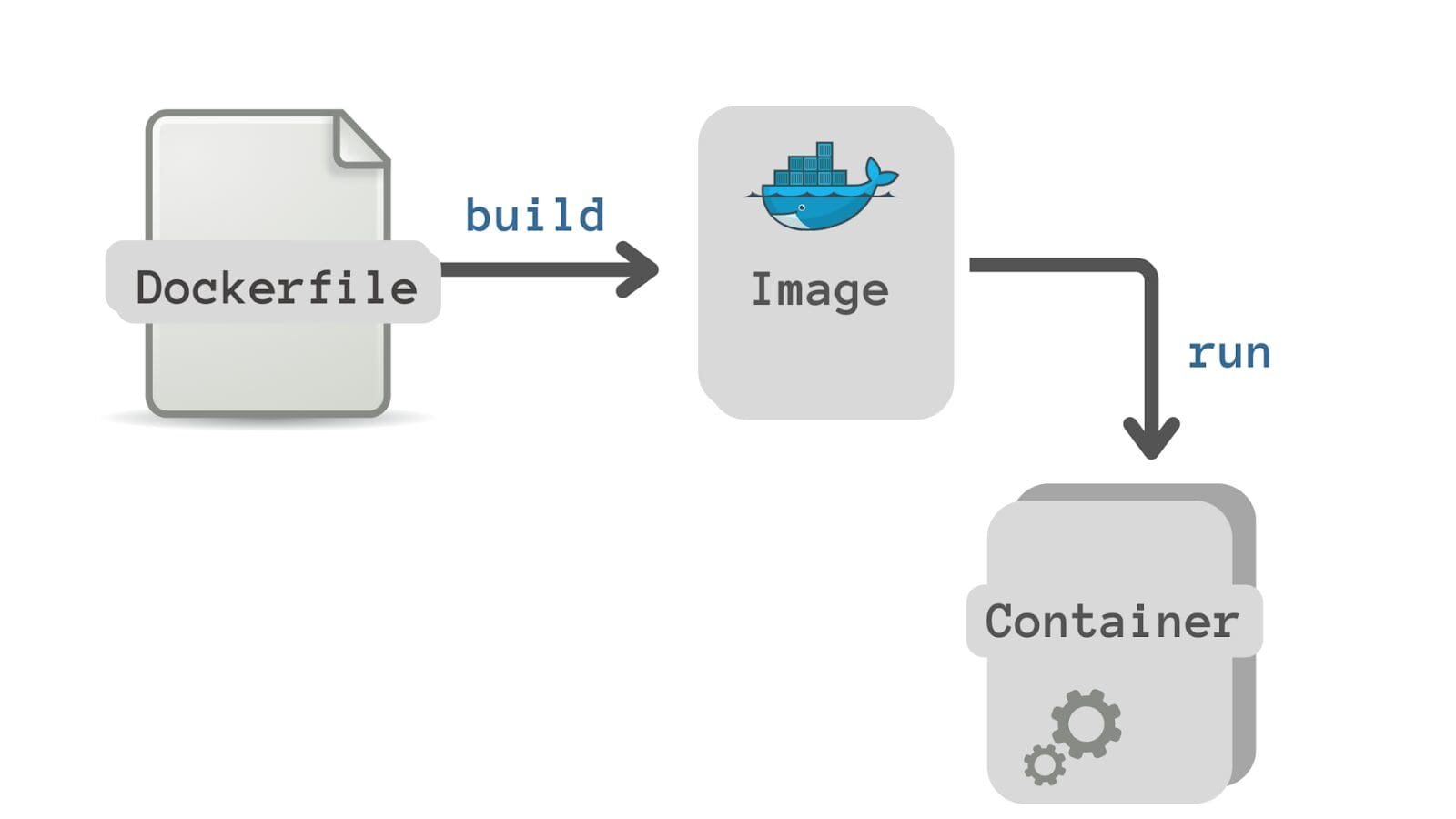
以下は、この例のDockerfileです:
# Pythonの公式イメージをベースイメージに使用する
FROM python:3.9-slim
# コンテナ内の作業ディレクトリを設定する
WORKDIR /app
# requirements.txtファイルをコンテナにコピーする
COPY requirements.txt .
# 依存関係をインストールする
RUN pip install --no-cache-dir -r requirements.txt
# スクリプトファイルをコンテナにコピーする
COPY house_price_prediction.py .
# Pythonスクリプトを実行するコマンドを設定する
CMD ["python", "house_price_prediction.py"]
Dockerfileの内容を解説しましょう:
- すべてのDockerfileは、ベースイメージを指定する
FROM命令で始まります。ベースイメージとは、イメージが基づいているイメージのことです。ここではPython 3.9の利用可能なイメージを使用しています。FROM命令は、現在のイメージを指定したベースイメージからビルドするようDockerに指示します。 SETコマンドは、すべての後続のコマンド(この例ではapp)の作業ディレクトリを設定するために使用されます。- 次に、
requirements.txtファイルをコンテナのファイルシステムにコピーします。 RUN命令は、コンテナ内で指定したコマンドをシェルで実行します。ここでは、pipを使用して必要な依存関係をすべてインストールしています。- 次に、ソースコードファイルであるPythonスクリプト
house_price_prediction.pyをコンテナのファイルシステムにコピーします。 - 最後に、
CMDはコンテナの起動時に実行される命令を指します。ここではhouse_price_prediction.pyスクリプトを実行する必要があります。Dockerfileには1つのCMD命令のみを含めるべきです。
イメージのビルド
Dockerfileを定義したので、docker buildを実行してDockerイメージをビルドできます:
docker build -t ml-app .
-tオプションを使用して、イメージの名前とタグをname:tag形式で指定できます。デフォルトのタグはlatestです。
ビルドプロセスには数分かかります:
Sending build context to Docker daemon 4.608kB
Step 1/6 : FROM python:3.9-slim
3.9-slim: Pulling from library/python
5b5fe70539cd: Pull complete
f4b0e4004dc0: Pull complete
ec1650096fae: Pull complete
2ee3c5a347ae: Pull complete
d854e82593a7: Pull complete
Digest: sha256:0074c6241f2ff175532c72fb0fb37264e8a1ac68f9790f9ee6da7e9fdfb67a0e
Status: Downloaded newer image for python:3.9-slim
---> 326a3a036ed2
Step 2/6 : WORKDIR /app
...
...
...
Step 6/6 : CMD ["python", "house_price_prediction.py"]
---> Running in 7fcef6a2ab2c
Removing intermediate container 7fcef6a2ab2c
---> 2607aa43c61a
Successfully built 2607aa43c61a
Successfully tagged ml-app:latest
Dockerイメージがビルドされたら、docker imagesコマンドを実行します。そこにml-appイメージが表示されるはずです。
docker images
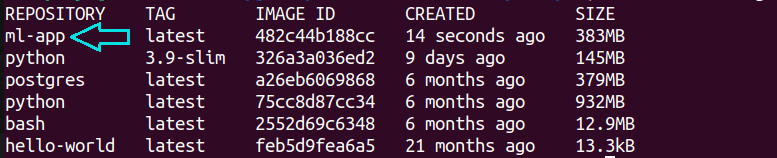
ml-appイメージをdocker runコマンドを使用して実行できます:
docker run ml-app

おめでとうございます!これで最初のデータサイエンスアプリケーションをDocker化しました。DockerHubアカウントを作成することで、イメージをDockerHubにプッシュすることができます(または組織内のプライベートリポジトリにプッシュすることもできます)。
結論
この入門的なDockerチュートリアルが役立つことを願っています。このチュートリアルで使用したコードは、このGitHubリポジトリで見つけることができます。次のステップとして、マシンにDockerを設定し、この例を試してみてください。または、選んだアプリケーションをDocker化してみてください。
マシンにDockerをインストールする最も簡単な方法は、Docker Desktopを使用することです:Docker CLIクライアントとコンテナを簡単に管理するためのGUIの両方が提供されます。ですので、Dockerを設定してすぐにコーディングを始めましょう! Bala Priya Cは、インド出身の開発者兼テクニカルライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での作業が好きです。彼女の興味と専門知識の範囲には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、コーヒーを楽しんでいます!現在は、チュートリアル、ハウツーガイド、意見記事などを執筆することにより、開発者コミュニティとの知識共有に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
