オリジナルのPDFのフォーマットを保持し、Amazon Textract、Amazon Translate、およびPDFBoxで翻訳されたドキュメントを表示します
Display documents translated using Amazon Textract, Amazon Translate, and PDFBox while preserving the original PDF format.
様々な業界の企業は、大量のPDF文書を作成し、スキャンし、保存しています。多くの場合、コンテンツはテキストが多く、異なる言語で書かれており、翻訳が必要です。これに対応するためには、これらのPDF内のコンテンツを自動的に抽出し、迅速かつ効率的に翻訳する自動化されたソリューションが必要です。
多くのビジネスは、多様なグローバルユーザーを持ち、それらの間でクロス言語コミュニケーションを可能にするためにテキストを翻訳する必要があります。これは手作業であり、遅く、高価な人間の努力です。オリジナルの文書のフォーマットを保持しながら文書を翻訳するためのスケーラブルで信頼性のある、費用対効果の高いソリューションを見つける必要があります。
医療などの業界では、規制要件により、翻訳された文書には追加の人間が必要で、機械翻訳された文書の妥当性を検証する必要があります。
翻訳された文書が元のフォーマットと構造を保持していない場合、文脈が失われます。これにより、人間のレビュアーが検証し修正することが困難になる可能性があります。
この投稿では、Amazon Textract、Amazon Translate、およびApache PDFBoxを使用したジオメトリベースのアプローチを使用して、スキャンされたPDFから新しい翻訳されたPDFを作成する方法を示します。
ソリューションの概要
この投稿で紹介するソリューションでは、次のコンポーネントを使用します:
- Amazon Textract – スキャンされた文書から印刷されたテキスト、手書き、およびその他のデータを自動的に抽出する、完全に管理された機械学習(ML)サービスです。Amazon Textractは、単純な光学文字認識(OCR)を超えて、フォームやテーブルからデータを識別、理解、抽出するためのものです。 Amazon Textractは、財務報告書、医療記録、税務フォームなど、さまざまなドキュメントでテキストを検出できます。
- Amazon Translate – 高速で品質の高い、手頃な価格の言語翻訳を提供するニューラル機械翻訳サービスです。 Amazon Translateは、2,970以上の言語ペアを対象にオンデマンドおよびバッチ翻訳機能を提供し、翻訳コストを削減します。
- PDF Translate – Javaで書かれたオープンソースのライブラリで、AWS SamplesのGitHubに公開されています。このライブラリには、Amazon TextractとAmazon Translateを使用して、希望の言語で翻訳されたPDF文書を生成するためのロジックが含まれています。また、PDFドキュメントを作成するためにオープンソースのJavaライブラリであるApache PDFBoxも使用しています。他のプログラミング言語でも同様のPDF処理ライブラリが利用可能です。たとえば、Node PDFBoxなどがあります。
機械翻訳を行う際には、名前や固有の識別子など、特定のテキストのセクションを翻訳しないように保持したい場合があります。 Amazon Translateでは、タグの修正を許可するため、翻訳されないテキストを指定することができます。 Amazon Translateはまた、翻訳出力のフォーマリティのカスタマイズもサポートしており、翻訳の形式レベルをカスタマイズすることができます。
Amazon Textractの制限の詳細については、Amazon Textractのクォータを参照してください。
このソリューションは、現在English、Spanish、Italian、Portuguese、French、GermanをサポートしているAmazon Textractで抽出できる言語に制限されています。これらの言語はAmazon Translateでもサポートされています。Amazon Translateでサポートされている言語の完全なリストについては、サポートされている言語と言語コードを参照してください。
このPDFでは、英語からスペイン語へのテキストの翻訳をデモンストレーションするために使用されます。このソリューションは、フォーマットなしで翻訳されたドキュメントを生成することもサポートします。翻訳されたテキストの位置は保持されます。ソースと翻訳されたPDFドキュメントは、AWS SamplesのGitHubリポジトリでも見つけることができます。
次のセクションでは、ローカルマシン上で翻訳コードを実行する方法と、翻訳コードの詳細について見ていきます。

前提条件
開始する前に、AWSアカウントとAWSコマンドラインインターフェース(AWS CLI)をセットアップしてください。 Amazon TextractやTranslateなどのAWSサービスへのアクセスには、適切なIAM権限が必要です。最小特権のアクセス許可を利用することをお勧めします。 IAMの権限については、IAMのポリシーと権限およびAmazon TextractとIAMの連携、Amazon TranslateとIAMの連携を参照してください。
ローカルマシンで翻訳コードを実行する
このソリューションでは、PDFドキュメントを抽出して翻訳するためのスタンドアロンのJavaコードに焦点を当てています。これは、最適なレンダリングされた翻訳済みPDFドキュメントをテストおよびカスタマイズするためのものです。その後、コードをAWSでデプロイして実行する自動化されたソリューションに統合することができます。コードの実行には、Amazon Simple Storage Service(Amazon S3)を使用してドキュメントを保存し、AWS Lambdaを使用してコードを実行するサンプルアーキテクチャを参照してください。
ローカルマシンでコードを実行するには、以下の手順を完了してください。コードの例はGitHubリポジトリで利用可能です。
-
GitHubリポジトリをクローンします:
git clone https://github.com/aws-samples/amazon-translate-pdf -
次のコマンドを実行します:
cd amazon-translate-pdf -
次のコマンドを実行して、英語からスペイン語に翻訳します:
java -jar target/translate-pdf-1.0.jar --source en --translated es
2つの翻訳されたPDFドキュメントがdocumentsフォルダに作成されます。元の書式と共に(SampleOutput-es.pdfとSampleOutput-min-es.pdf)。
翻訳されたPDFを生成するためのコード
次のコードスニペットは、PDFドキュメントを取得し、対応する翻訳されたPDFドキュメントを生成する方法を示しています。Amazon Textractを使用してテキストを抽出し、翻訳されたテキストを画像のレイヤーとして追加して翻訳されたPDFを作成します。これは、Amazon Textractを使用してスキャンされたドキュメントから自動的に検索可能なPDFを生成する解決策に基づいています。
コードはまず、Amazon Textractで各行のテキストを取得します。 Amazon Translateを使用して翻訳されたテキストを取得し、翻訳されたテキストのジオメトリを保存します。
Region region = Region.US_EAST_1;
TextractClient textractClient = TextractClient.builder()
.region(region)
.build();
// 入力のDocumentオブジェクトをバイトとして取得
Document pdfDoc = Document.builder()
.bytes(SdkBytes.fromByteBuffer(imageBytes))
.build();
TranslateClient translateClient = TranslateClient.builder()
.region(region)
.build();
DetectDocumentTextRequest detectDocumentTextRequest = DetectDocumentTextRequest.builder()
.document(pdfDoc)
.build();
// Detect操作を呼び出す
DetectDocumentTextResponse textResponse = textractClient.detectDocumentText(detectDocumentTextRequest);
List<Block> blocks = textResponse.blocks();
List<TextLine> lines = new ArrayList<>();
BoundingBox boundingBox;
for (Block block : blocks) {
if ((block.blockType()).equals(BlockType.LINE)) {
String source = block.text();
TranslateTextRequest requestTranslate = TranslateTextRequest.builder()
.sourceLanguageCode(sourceLanguage)
.targetLanguageCode(destinationLanguage)
.text(source)
.build();
TranslateTextResponse resultTranslate = translateClient.translateText(requestTranslate);
boundingBox = block.geometry().boundingBox();
lines.add(new TextLine(boundingBox.left(),
boundingBox.top(),
boundingBox.width(),
boundingBox.height(),
resultTranslate.translatedText(),
source));
}
}
return lines;フォントサイズは次のように計算され、簡単に設定できます:
int fontSize = 20;
float textWidth = font.getStringWidth(text) / 1000 * fontSize;
float textHeight = font.getFontDescriptor().getFontBoundingBox().getHeight() / 1000 * fontSize;
if (textWidth > bbWidth) {
while (textWidth > bbWidth) {
fontSize -= 1;
textWidth = font.getStringWidth(text) / 1000 * fontSize;
textHeight = font.getFontDescriptor().getFontBoundingBox().getHeight() / 1000 * fontSize;
}
} else if (textWidth < bbWidth) {
while (textWidth < bbWidth) {
fontSize += 1;
textWidth = font.getStringWidth(text) / 1000 * fontSize;
textHeight = font.getFontDescriptor().getFontBoundingBox().getHeight() / 1000 * fontSize;
}
}保存されたジオメトリと翻訳されたテキストから翻訳されたPDFが作成されます。翻訳されたテキストの色の変更は簡単に設定できます。
float width = image.getWidth();
float height = image.getHeight();
PDRectangle box = new PDRectangle(width, height);
PDPage page = new PDPage(box);
page.setMediaBox(box);
this.document.addPage(page); //org.apache.pdfbox.pdmodel.PDDocument
PDImageXObject pdImage;
if(imageType == ImageType.JPEG){
pdImage = JPEGFactory.createFromImage(this.document, image);
} else {
pdImage = LosslessFactory.createFromImage(this.document, image);
}
PDPageContentStream contentStream = new PDPageContentStream(document, page, PDPageContentStream.AppendMode.OVERWRITE, false);
contentStream.drawImage(pdImage, 0, 0);
contentStream.setRenderingMode(RenderingMode.FILL);
for (TextLine cline : lines){
String clinetext = cline.text;
String clinetextOriginal = cline.originalText;
FontInfo fontInfo = calculateFontSize(clinetextOriginal, (float) cline.width * width, (float) cline.height * height, font);
//元のドキュメント構造を含めるように構成する - 元のドキュメントとオーバーレイ
contentStream.setNonStrokingColor(Color.WHITE);
contentStream.addRect((float) cline.left * width, (float) (height - height * cline.top - fontInfo.textHeight), (float) cline.width * width, (float) cline.height * height);
contentStream.fill();
fontInfo = calculateFontSize(clinetext, (float) cline.width * width, (float) cline.height * height, font);
//元のドキュメント構造を含めるように構成する - 翻訳されたドキュメントとオーバーレイ
contentStream.setNonStrokingColor(Color.WHITE);
contentStream.addRect((float) cline.left * width, (float) (height - height * cline.top - fontInfo.textHeight), (float) cline.width * width, (float) cline.height * height);
contentStream.fill();
//ここで出力テキストの色を変更する
fontInfo = calculateFontSize(clinetext.length() <= clinetextOriginal.length() ? clinetextOriginal : clinetext, (float) cline.width * width, (float) cline.height * height, font);
contentStream.setNonStrokingColor(Color.BLACK);
contentStream.beginText();
contentStream.setFont(font, fontInfo.fontSize);
contentStream.newLineAtOffset((float) cline.left * width, (float) (height - height * cline.top - fontInfo.textHeight));
contentStream.showText(clinetext);
contentStream.endText();
}
contentStream.close()以下の画像は、元の書式を保持した状態でスペイン語に翻訳されたドキュメントを表示しています(SampleOutput-es.pdf)。
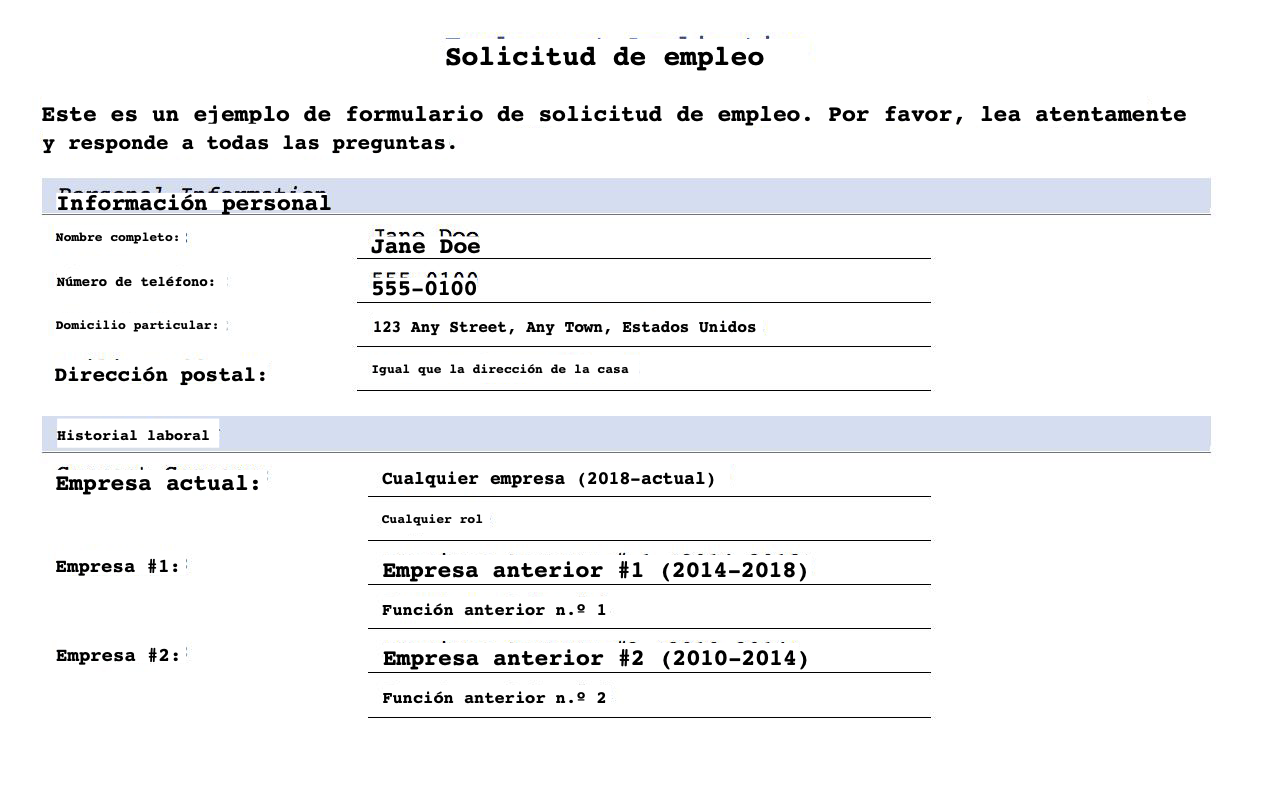
以下の画像は、書式のないスペイン語の翻訳PDFを表示しています(SampleOutput-min-es.pdf)。

処理時間
雇用申請PDFの抽出、処理、および翻訳PDFのレンダリングには約10秒かかりました。独立宣言PDFなどのテキストが多いドキュメントの処理時間は1分未満でした。
費用
Amazon Textractでは、処理されるページと画像の数に基づいて従量課金されます。Amazon Translateでは、処理されるテキスト文字の数に基づいて従量課金されます。実際の費用については、Amazon Textractの価格とAmazon Translateの価格を参照してください。
結論
この記事では、Amazon TextractおよびAmazon Translateを使用して、元のドキュメント構造を保持したまま翻訳されたPDFドキュメントを生成する方法を紹介しました。翻訳の品質を向上させるために、Amazon Textractの結果を事後処理することもできます。たとえば、抽出された単語をSymSpellなどのMLベースのスペルチェックに通すことでデータの検証ができます。また、クラスタリングアルゴリズムを使用して読み取り順序を保持することもできます。さらに、Amazon Augmented AI(Amazon A2I)を使用して、元のPDFドキュメントと翻訳されたPDFドキュメントを人間のレビューに提供し、より正確なコンテキストを提供するためのワークフローを構築することもできます。始めるには、「Amazon TranslateとAmazon Augmented AIを使用したヒューマンレビューワークフローの設計」と「ドメイン固有および言語固有のカスタマイズを使用した多言語ドキュメント翻訳ワークフローの構築」を参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- MITが革新的なAIツールを発表:すべての能力レベルのユーザーに対して適応可能で詳細豊富なキャプションを使用して、チャートの解釈とアクセシビリティを向上させる
- 既存のLLMプロジェクトをLangChainを使用するように適応する
- 顔認識によって食料品店から立ち入り禁止
- AIが宇宙へ!NASAがChatGPTのようなチャットボットを宇宙船通信に導入予定
- ChatHNに会いましょう:ハッカーニュースフィード上のリアルタイムAIパワーチャット
- ベストAI画像生成器(2023年7月)
- 新しいZeroscope v2モデルに会ってください:モダンなグラフィックカード上で動作する無料のテキストからビデオへのモデル






