「LLaMaをポケットに収めるトリック:LLMの効率とパフォーマンスを結ぶAIメソッド、OmniQuantに出会おう」
Discover OmniQuant the AI method that combines the efficiency and performance of LLM, allowing you to carry LLaMa in your pocket.


大型言語モデル(LLM)は、機械翻訳、テキスト要約、質問応答など、さまざまな自然言語処理タスクで印象的なパフォーマンスを発揮しています。彼らは私たちがコンピュータとコミュニケーションを取る方法やタスクを行う方法を変えてきました。
LLMは、自然言語の理解と生成の限界を押し広げる変革的な存在として現れています。その中でもChatGPTは、会話の文脈でユーザーと対話するために設計されたLLMのクラスを代表する注目すべき例です。これらのモデルは、非常に大きなテキストデータセットでの集中的なトレーニングの結果、人間のようなテキストを理解し生成する能力を持っています。
しかし、これらのモデルは計算とメモリの消費量が多く、実用的な展開を制限しています。その名前が示すように、これらのモデルは大きいです。最新のオープンソースLLMであるMetaのLLaMa2は、約700億のパラメータを含んでいます。
これらの要件を削減することは、より実用的にするための重要なステップです。量子化は、LLMの計算とメモリのオーバーヘッドを削減する有望な技術です。量子化には、トレーニング後の量子化(PTQ)と量子化に対応したトレーニング(QAT)の2つの主要な方法があります。QATは競争力のある精度を提供しますが、計算と時間の両方の面で非常に高価です。そのため、PTQは多くの量子化の試みで主要な方法となっています。
重みのみの量子化や重み活性化の量子化など、既存のPTQ技術は、メモリ消費量と計算オーバーヘッドの大幅な削減を達成しています。ただし、効率的な展開には重要な低ビット量子化で苦労する傾向があります。低ビット量子化におけるこの性能の低下は、手作業での量子化パラメータに依存しているため、最適な結果が得られないことが主な原因です。
それでは、OmniQuantに会いましょう。これはLLM用の画期的な量子化技術であり、特に低ビット設定でさまざまな量子化シナリオで最先端のパフォーマンスを実現し、PTQの時間とデータの効率性を保ちます。
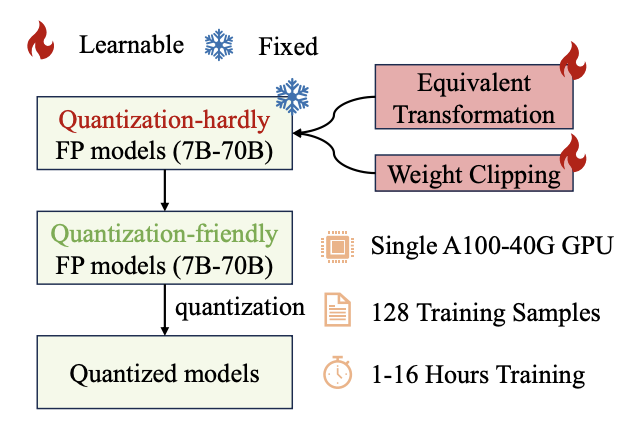
OmniQuantは、元の完全精度の重みを凍結し、一部の学習可能な量子化パラメータを組み込むというユニークなアプローチを取ります。QATとは異なり、煩雑な重みの最適化を必要とせず、OmniQuantは個々のレイヤーに焦点を当てた順次量子化プロセスに焦点を当てています。これにより、単純なアルゴリズムを使用した効率的な最適化が可能になります。
OmniQuantは、学習可能な重みクリッピング(LWC)と学習可能な等価変換(LET)という2つの重要なコンポーネントで構成されています。LWCはクリッピング閾値を最適化し、極端な重み値を調整します。一方、LETはトランスフォーマーエンコーダ内で等価変換を学習することで、アクティベーションの外れ値に対処します。これらのコンポーネントにより、完全精度の重みとアクティベーションを量子化しやすくします。
OmniQuantの柔軟性は、重みのみの量子化や重み活性化の量子化の両方に対応しており、量子化されたモデルには追加の計算負荷やパラメータが必要ありません。なぜなら、量子化パラメータは量子化された重みに融合されるからです。
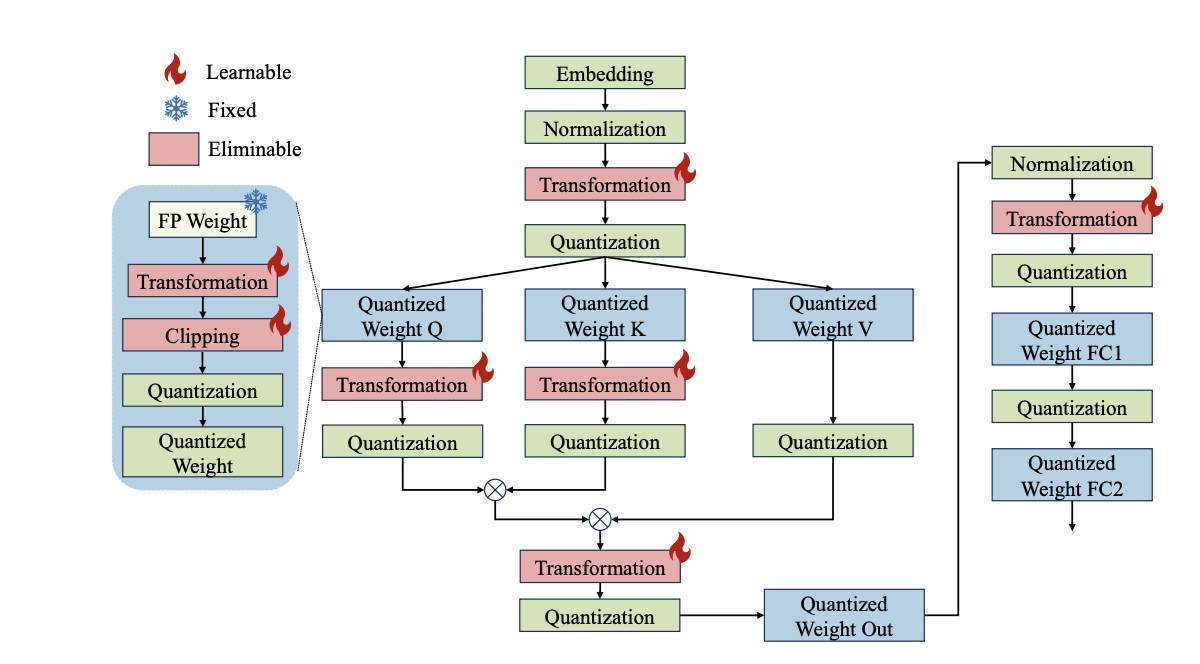
LLM全体のすべてのパラメータを共同で最適化する代わりに、「OmniQuant」は次のレイヤーに移る前に1つのレイヤーのパラメータを順次量子化します。これにより、OmniQuantは単純な確率的勾配降下法(SGD)アルゴリズムを使用して効率的に最適化することができます。
これは実用的なモデルであり、単一のGPU上でも簡単に実装できます。自分自身のLLMを16時間で訓練することができるため、さまざまな実世界のアプリケーションで本当にアクセスしやすくなります。また、OmniQuantは以前のPTQベースの方法よりも優れたパフォーマンスを発揮するため、パフォーマンスを犠牲にすることはありません。
ただし、これはまだ比較的新しい手法であり、パフォーマンスにはいくつかの制約があります。たとえば、フルプレシジョンモデルよりもわずかに悪い結果を生み出すことがある場合があります。しかし、これはOmniQuantの小さな不便さであり、LLMの効率的な展開のための有望な技術です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles