「多数から少数へ:機械学習における次元削減による高次元データの取り扱い」
Dimension Reduction in Machine Learning Handling High-Dimensional Data from Many to Few
この記事では、機械学習の問題における次元の呪いと、その問題の解決策である次元削減について説明します。
次元の呪いとは何ですか?
機械学習の問題は、トレーニングインスタンスごとに数千、数百万の特徴を持つ場合があります。このようなデータで機械学習モデルをトレーニングすることは、非常にリソースを消費するだけでなく、時間もかかります。この問題はしばしば「次元の呪い」と呼ばれています。
高次元性の問題を解決する方法
- 「MITとスタンフォードの研究者は、効率的にロボットを制御するために機械学習の技術を開発しましたこれにより、より少ないデータでより良いパフォーマンスが得られるようになります」
- 「LG AI Researchが提案するQASA:新しいAIベンチマークデータセットと計算アプローチ」
- 「カルロス・アルカラス vs. ビッグ3」
次元の呪いに対処するために、データの特徴数(つまり、次元数)を減らすさまざまな方法をよく使用します。
次元削減手法の有用性
次元削減手法は、リソースと時間を節約するのに役立ちます。まれな場合では、削減によって不要なノイズがデータから取り除かれることもあります。次元削減の別の用途は、データの可視化です。高次元データの可視化は難しく、成功しても理解するのが難しいため、次元を2または3に削減することでデータをより明確に可視化できるようになります。
データの次元削減の欠点
次元削減手法には欠点もあります。データの次元削減を行うと情報の損失が発生します。また、データに次元削減手法を使用してもモデルのパフォーマンスが向上することは保証されません。これらの手法はモデルをより速くトレーニングしたりリソースを保護するための手段であり、モデルのパフォーマンスを向上させる方法ではありません。ほとんどの場合、削減されたデータでトレーニングされたモデルのパフォーマンスは、元のデータでトレーニングされたモデルと比較して低いでしょう。
次元削減には2つの有名なアプローチがあります。
- 射影
- 多様体学習
射影
ほとんどの現実の問題では、データの特徴はすべての次元に均等に広がっているわけではありません。いくつかはほぼ一定であり、他の特徴と相関しています。したがって、これらのトレーニングインスタンスは元の高次元空間のはるかに低い部分空間内に存在します。言い換えれば、元のデータとほぼ同等の低次元表現が存在します。
ただし、このアプローチはすべてのタイプのデータセットにとって最適なアプローチではありません。一部のデータセットでは、射影方法を使用すると異なるレイヤーのインスタンスが一緒に押しつぶされ、そのような射影は元のデータを低次元に表現していません。このタイプのデータには、多様体学習の手法がより適しています。
多様体学習
多様体学習では、データを射影するのではなく、展開します。
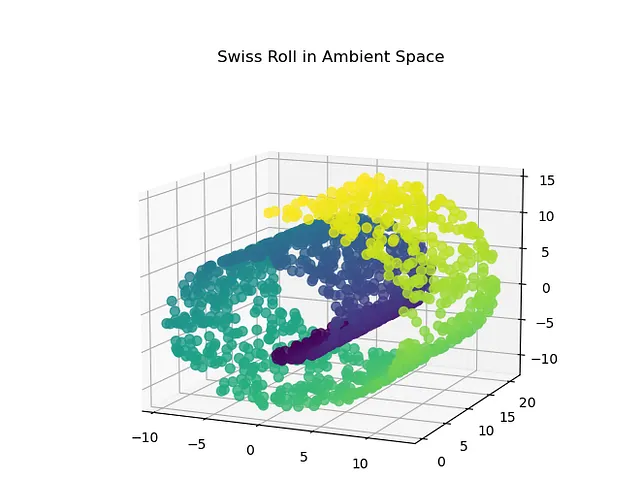
多様体学習の方法を理解するために、Swiss Rollデータセットの例を考えてみましょう。上記のSwiss Rollデータセットの可視化では、データの射影を重ねずに多くのデータインスタンスを重ね合わせることはできません。したがって、このような場合は、低次元部分空間に射影するのではなく、このデータを展開します。つまり、上記で示したデータポイントを2Dの場所に展開し、それを解釈します。
次に、最も人気で広く使用されている次元削減手法の1つである主成分分析(PCA)を理解しましょう。
PCAは射影の方法です。まず、データに近いハイパープレーンを見つけ、それにデータを射影します。
射影のための適切なハイパープレーンを見つける方法には2つの方法があります。
- データを射影した後、元のデータセットの分散の最大量を保持するハイパープレーンを見つける。
- 元のデータセットとその射影との平均二乗距離の最も低い値を与えるハイパープレーンを見つける。
データセットの分散を使用するのは、データセットの分散が含まれる情報の量を表すためです。
PCAは、最も多くの分散を説明するハイパープレーンの軸(つまり、主成分)を見つけます。
これを行う方法を理解しましょう。PCAのデモンストレーションには、ワインの品質データセットを使用します。
方法1
この方法では、PCAクラスをデフォルト設定でトレーニングし、その後各主成分が貢献する分散を求めます。その後、追加時に最も多くの分散を与える主成分の数を見つけます。次に、この理想的な主成分の数を使用して、PCAクラスを再度トレーニングします。
## 必要なライブラリのインポート
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
## データの読み込み
wine = pd.read_csv('データセットのパス')
wine.head()
## データを独立した特徴と従属した特徴に分割
X、y = wine.drop('quality', axis=1)、wine['quality']
## 方法1
pca = PCA()
pca.fit(X)
cumsum = np.cumsum(pca.explained_variance_ratio_)
no_of_principal_components = np.argmax(cumsum >= 0.95) + 1
print(f"主成分の数:{no_of_principal_components}\n\n分散比の累積和:{cumsum}.")
sns.set_style('darkgrid')
plt.plot(list(range(1, 12)), cumsum, color='c', marker='x')
plt.xlabel("主成分の数")
plt.ylabel("分散比の累積")
plt.title("理想的な主成分の数を見つける")
plt.grid(True)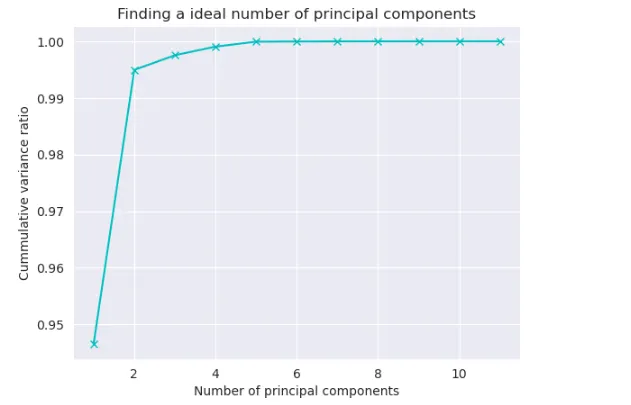
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
X_reduced
方法2
理想的な主成分の数を見つける代わりに、n_componentsの値を0から1の間の浮動小数点値に設定することもできます。この値は、削減後に保存したい分散の量を示します。
pca = PCA(n_components = 0.95)
X_reduced = pca.fit_transform(X)
X_reduced
データの展開
inverse_transform関数を使用して、データを元のサイズに復元することも可能です。もちろん、これは元のデータセットをそのまま取得するわけではありません。なぜなら、削減プロセスで情報の一部(約5%)を失っているからです。しかし、この展開により、元のデータセットに非常に近いデータセットが得られます。
pseudo_original_data = pca.inverse_transform(X_reduced)
pseudo_original_data
PCAアルゴリズムにはさまざまなバリエーションがあります:ランダム化されたPCA、インクリメンタルPCA、カーネルPCAなどです。また、この人気のあるPCAアルゴリズム以外にも、isomap、t分布型stochastic neighbor embedding(t-SNE)、線形判別分析(LDA)などの多くの次元削減アルゴリズムがあります。
この記事がお気に召しましたか?記事についてのご意見があれば、お知らせください。建設的なフィードバックは大歓迎です。LinkedInで私に連絡してください。[email protected]までメールしてください。素晴らしい一日をお過ごしください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
