「DiffusionDet 物体検出のために拡散を使用する人工知能(AI)モデルを紹介します」
DiffusionDet AIモデルは、物体検出に拡散を使用します


オブジェクト検出は、画像や動画中のオブジェクトを識別するための強力な技術です。深層学習とコンピュータビジョンの進歩により、ここ数年で大きく進化してきました。これは、輸送やセキュリティ、医療、小売業など、さまざまな産業を革新する可能性を持っています。技術がさらに向上するにつれて、オブジェクト検出の分野でさらなるエキサイティングな発展が期待されます。
オブジェクト検出の主な課題の1つは、画像内のオブジェクトを正確にローカライズする能力です。これには、オブジェクトが存在することを特定し、その正確な位置とサイズを決定することが含まれます。
ほとんどのオブジェクト検出器は、画像の特定の領域(スライディングウィンドウや領域提案など)を見て、これらをオブジェクトを識別するための「ガイド」として使用することで、回帰と分類の組み合わせを使用してオブジェクトを識別します。アンカーボックスや参照点などの他の手法もオブジェクト検出に役立つことがあります。
これらのオブジェクト検出の手法は比較的簡単かつ効果的ですが、固定された一連の事前定義された検索基準に依存しています。ほとんどの場合、一連の候補オブジェクトを定義する必要がありますが、これは手間がかかることがあります。これらの事前定義された検索ガイドラインを必要とせずに、さらにプロセスをさらに簡素化する方法はありますか?
テンセントの研究者からの回答は、DiffusionDetというオブジェクト検出に使用される拡散モデルを提案するものでした。
拡散モデルは、最近数ヶ月間、AIコミュニティの注目を集めています。主に、Stable Diffusionモデルの公開によるものです。簡単に説明すると、拡散モデルはノイズを入力として受け取り、ある規則に従って徐々にノイズを除去して望ましい出力を得るまで変化させます。安定した拡散の文脈では、入力はテキストプロンプトによって得られたノイズ画像であり、これを似たようなテキストプロンプトの画像になるまでゆっくりとノイズを除去していきます。
では、オブジェクト検出に拡散アプローチをどのように使用するのでしょうか?私たちは新しいものを生成することには興味がありません。代わりに、与えられた画像内のオブジェクトを知りたいのです。彼らはどのようにそれを行ったのでしょうか?
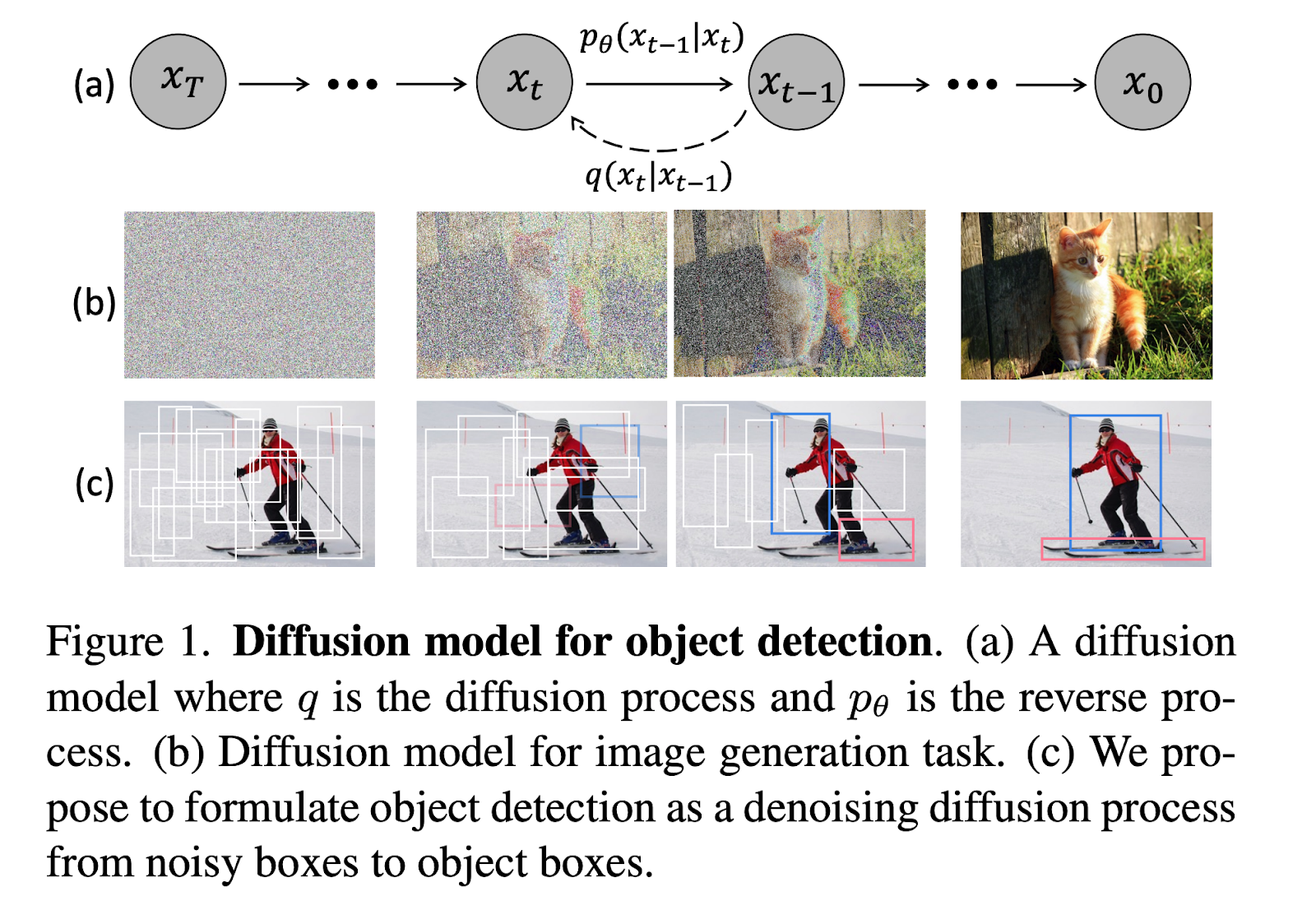
DiffusionDetでは、一連のランダムボックスから直接オブジェクトを検出するための新しいフレームワークが設計されています。これらのボックスには、トレーニング中に最適化する必要のある学習可能なパラメータは含まれていません。これらのボックスの位置とサイズは、ノイズからボックスへのアプローチを通じて徐々に修正され、最終的に対象のオブジェクトを正確にカバーするようになります。
ボックスを入力ノイズと考え、制約はそれらがオブジェクトを含んでいる必要があることです。したがって、最終的には、異なるオブジェクトを含む一連のボックスを取得したいと考えています。デノイジングステップでは、ボックスのサイズと位置を徐々に変化させていきます。ヒューリスティックなオブジェクト事前知識や学習可能なクエリは、このアプローチでは必要ありません。これにより、オブジェクト候補の特定が簡素化され、検出パイプラインの開発が進展します。
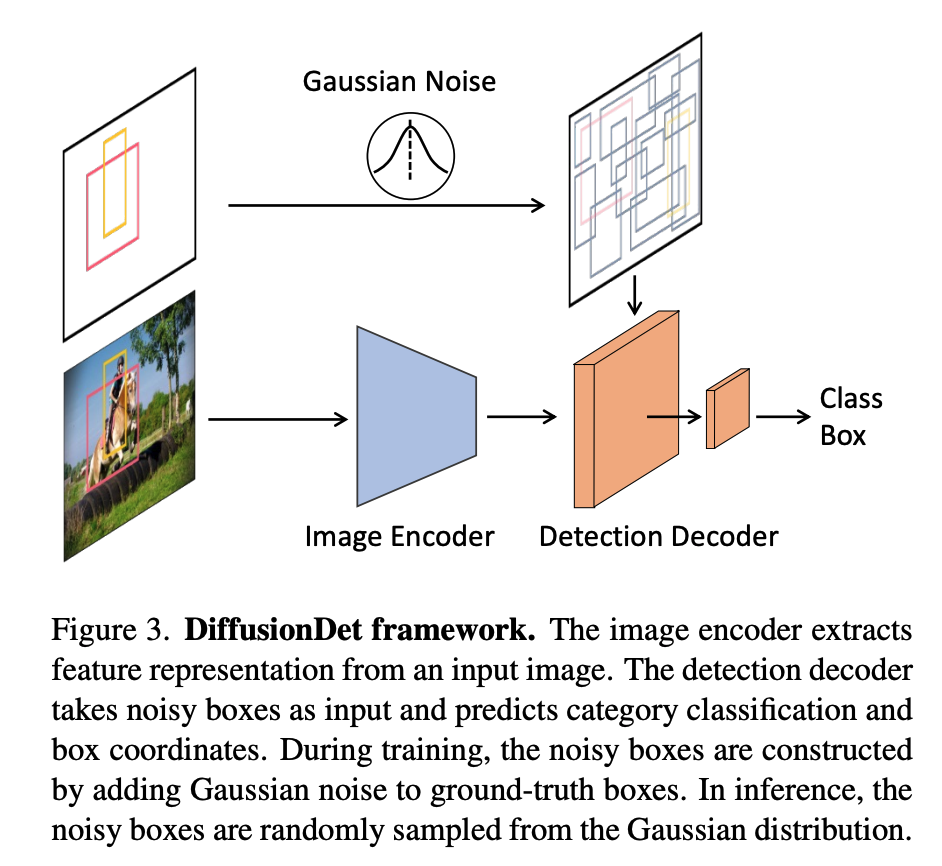
DiffusionDetは、画像内のバウンディングボックスの位置とサイズを含む生成課題として、物体検出を考えます。トレーニング中には、分散スケジュールによって制御されたノイズが真のボックスに追加され、ノイズのあるボックスが作成されます。そして、これらのボックスをバックボーンエンコーダの出力特徴マップからクロップされた特徴に使用します。これらの特徴は、ノイズのない真のボックスを予測するようにトレーニングされた検出デコーダに送られます。これにより、DiffusionDetはランダムなボックスから真のボックスを予測することができます。推論時には、DiffusionDetは学習された拡散プロセスを逆転させ、学習されたバウンディングボックスの分布に対してノイズのある事前分布を調整してバウンディングボックスを生成します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






