「オープンソースモデルと商用AI/ML APIの違い」
Difference between open-source models and commercial AI/ML APIs
モデルのパフォーマンスを超えた多次元分析
最近、おそらく無数の議論を見かけたことでしょう。大規模言語モデル(LLM)においてオープンソースや商用APIを使用するべきかについての議論です。しかし、これはLLMに特有のものではありません。この問いは機械学習(ML)全般に適用されます。私は過去5年間、AWSのMLアーキテクトとして多くの顧客からこの質問を受けてきました。
このブログでは、オープンソースのMLモデルと商用のML APIのどちらを選ぶかを、モデルのパフォーマンスだけでなく、コストや開発時間、所有権、メンテナンスなど、重要な複数の分析の観点からMLエンジニア、意思決定者、MLチーム全体に助言するアプローチを共有します。
1. はじめる前に定義を確認しましょう!
オープンソースのMLモデルは、モデルのアーキテクチャ(モデルの設計)とウェイト(モデルの知識)の組み合わせです。Hugging Face、Pytorch Hub、Tensorflow Hubなどの公開モデルのハブにアクセスし、ダウンロードすることができます。
商用のML API(例:OpenAI API)は、APIエンドポイントを介してアクセスされるサービスであり、MLモデルを含むものです(他の要素については後ほど詳しく説明します)。これらのML APIは、クラウドプロバイダ(AWS、Azure、GCPなど)や特定のドメイン/MLタスクのサブセットに特化した小規模な企業(Mindee、Lettria、Gladiaなど)のサービスの中に見つけることができます。
外見上は非常に似ています。データを入力し、テキスト生成などの希望する出力を受け取ります。しかし、それらがどのように異なるかを掘り下げてみましょう。
2. ML APIは単なる「APIで包まれたMLモデル」ではありません
モデルの周りのブロックとそれらがどのように使用されるかを見てみましょう:
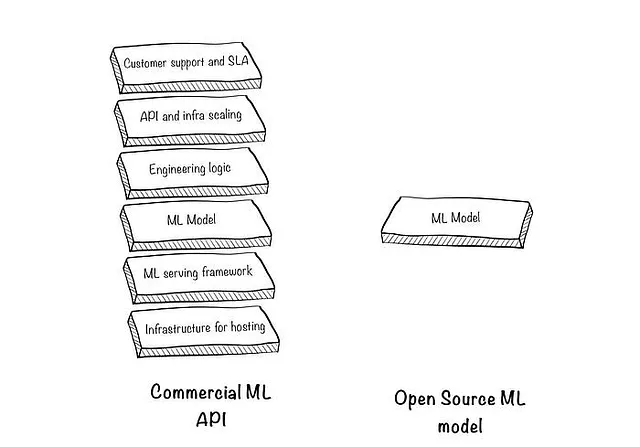
2.1 ホスティングのためのインフラストラクチャ: MLモデルを選ぶ際に最初に行うのは、どこで実行するかを決めることです。実験中であり、モデルが比較的小さい場合は、自分のマシンで実行することができます。しかし、これは常に可能またはスケーラブルではないため、クラウドプロバイダ(AWS、GCP、Azure)を利用してサーバーを借りることになります。
2.2 MLサービングフレームワーク: モデルは単なる「Python関数」ではありません。予測を最適な方法で提供するために、サービングフレームワーク(TorcheServe、TFServingなど、よりLLMに特化したものもあります)を利用することになります。これらのフレームワークは、最適なレイテンシと高並行性を処理するために必要なものですが、学習曲線も存在します。
2.3 エンジニアリングロジック: これは非常にケースに依存し、MLエンジニアにとって大量の時間を消費することがあります(悪魔は細部に宿るのです)。
例えば、シンプルなユースケースとして感情分析を取り上げましょう。以下はHugging Faceの抜粋です:

テキストの数行の感情を生成する必要がある場合、それで終わりです。
しかし、例えば10,000のドキュメント(pdf、ワード、テキストなどの異なる形式)の感情を検出したい場合、以下の手順が必要です:
- まず、PDFをOCR(光学文字認識)モデルに通します。
- エッジケースに対処します(複数ページ、向きが正しくないページなど)。
- ドキュメントの種類に基づいて異なるモデルを使用し、すべてのデータを適切な形式に変換するためのオーケストレーションワークフローを構築します。
- すべてを感情分析モデルに渡します。しかし、シーケンシャルに実行することはできないことに気づきます。
- Xドキュメントを受け取り、それらを複数のプロセス(複数のサーバーなど)に分割し、予測を実行して結果を返すパラレル化パイプラインを実装します。
- 上記のソリューションの安定性を確保するためのテストと自動化プロセスを作成します。
これらのコンポーネントは、商用のML APIによって抽象化される詳細の中にある悪魔です。APIプロバイダーは、自分たちのチームでエンジニアを雇い、上記の作業を行い、それを維持し、更新することができます。したがって、次のようなものを使用できます:
#疑似コード(実際のライブラリではありません)import providerx#プロバイダにアクセスできるようにAPIキーを設定するproviderx.api-key = "123452" #データをプロバイダに渡し、上記のステップを実行し、感情を検出します。sentiments = providerx.detect_sentiment('./folder-containing-documents/', document_types=["pdf","word", "txt"]))2.4 APIおよびインフラストラクチャのスケーリング:これには2つの側面があります。まず、上記のすべてのコンポーネントをAPIにパッケージ化して、モデルの予測をテックスタックと製品の他の部分からアクセスできるようにします。次に、同時性とトラフィックの急増に対応できるようにします。例を挙げると:
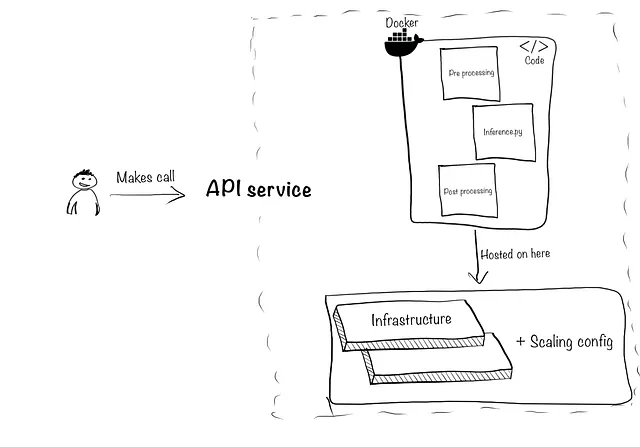
モデルをパッケージ化するには、推論コード(inference.pyスクリプト)を組み合わせ、他の前処理/後処理ファイルを作成し、Dockerコンテナを作成し、FastAPI、Amazon APIゲートウェイ、Apigee API管理などを使用してAPIを作成する必要があります。
次に、スケーリングです。ユーザー数や予測数が増えるにつれて、作成したAPIの背後に必要なインフラストラクチャも増えます。ユーザートラフィックに基づいて、まずは小規模なサーバー(月額約30ドル)から始め、必要に応じて(月額約200ドル)にスケーリングすることになるかもしれません。そして、誰もAPIを使用していないときには再びスケーリングダウンします。
ここで事態はややこしくなります。単なるMLの予測だけでなく、チーム内で小規模なソフトウェア/サービスを作成しています。
これがあなたの主要なビジネスである場合は問題ありません(例:会社の小売ウェブサイトの推奨システムを構築している場合)。ただし、プロジェクトがサポート機能のためにある場合は、完全にリスクが伴います(例:操作ドキュメントからテキストを抽出してエクセルでデータ入力を容易にする場合)
2.5 顧客サポートとSLA:最後に、予期しない動作や何かが壊れたときに、誰が修正しますか?
オープンソースのMLモデルを使用してソリューションを自社内で構築する場合、少なくとも1人のエンジニアをチームに配置してサポートとバグ修正に時間を割かなければなりません。
商用のML APIを使用する場合、サービスレベル契約(SLA)の下でサポートを受けることがサービスの一部です。SLAの例として、「サービスが停止した場合、エンジニアを割り当てて6時間以内に修正します」といったものがあります。
最後に、商用のML APIがデザイン上、より多くのことを行っているとしても、それらを自分で実行できないわけではありません。重要なのは、商用のML APIと同じレベルのサービスを提供するためには、いずれこれらの要素を構築する必要があるということです。
3. コストを比較する際には、総所有コスト(TCO)を使用します
多くの人は「MLモデルは無料」とか「API呼び出しが高すぎる」と考えていますが、それがどれだけ真実か見てみましょう。
まず、予測の生成コストから始めましょう:
1/オープンソースのモデルを使用する場合:ResNet50(画像分類用)をg4dn.xlargeインスタンスにホスティングすると、1時間あたり0.526ドルかかり、このモデルに対して約75の予測を秒ごとに行うことができます(このテーブルの末尾にあります)。リアルタイムの応答をユーザーに提供する必要があるため、24時間365日インスタンスを稼働させ続けると、約400ドルかかり、APIを絶えず使用できれば約2億(75 * 60 * 60 * 24 * 31)の予測が可能です。
2/Amazon Rekognition APIを使用する場合:1つの予測につき0.00025ドルかかり、1か月で2億の予測を実現したい場合、それは驚異の5万ドルです
したがって、明らかにオプション1を選ぶべきですよね?まあ、それは月にどれだけの呼び出しを行っているかによります:
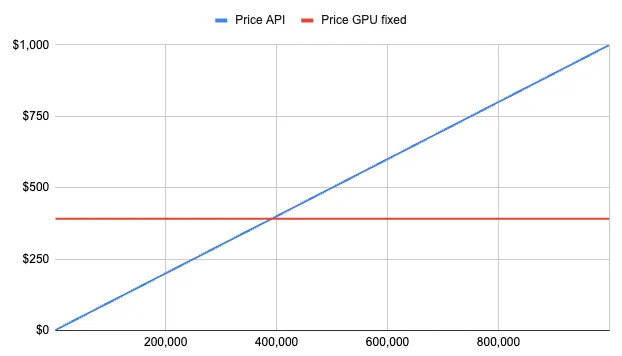
トラフィックの「バースト」を考慮していないことに注意してください。同時にMLモデルを呼び出すユーザーが増えれば増えるほど、負荷を処理するためにスピンアップする必要があるサーバーも増えます。そのため、GPUの価格は完全に固定されていませんが、簡略化のために、安定したワークロードに焦点を当て、以下の結論に至りましょう:
-> 1ヶ月に40万件未満の予測を行っている場合、商用ML APIの料金を支払う方が良いです。もしボリュームがそれ以上の場合、毎月、オープンソース版を選択し、自分でホストしてください。
注:LLMsに関する類似の研究はこちらで行われています。
これまでは予測を行うための費用について見てきました。しかし、コストを考える際にはTCO(総所有コスト)を考慮する必要があります。基本的には以下の質問に答えるものです:
モデル、インフラストラクチャ、エンジニアリングの時間、運用およびメンテナンスの労力を含めると、いくらかかるでしょうか?
エンジニアリングロジック、フレームワークの設定、インフラストラクチャの拡張性、メンテナンスとサポートなど、これらの要素には人的資本が必要です。これは推定するのが最も難しい部分であり、達成したいMLのタスク、提供したいサービスレベル、およびリソースに依存します。
MLの専門知識を持つ人物とバックエンド/クラウドの専門知識を持つ人物の2人を雇用すると仮定します。ソフトウェアエンジニアの平均年俸はアメリカでは12万ドル(ヨーロッパでは6万ドル)なので、最低でも合計24万ドル(ヨーロッパでは12万ドル)です(indeed、glassdoor)。
要するに、商用ML APIはエンジニアを雇用し、インフラストラクチャを借り、サービスの相互化の力によって、自身のAPIを通じてインフラストラクチャとエンジニアリングの一部を「借りる」ことができますので、自身で大きな責任を負う必要はありません。
4. ファインチューニング
「はい、しかし私はデータとユースケースに応じてモデルを細かく調整したい」という場合、オープンソースモデルと商用ML APIの両方でそれを行うことができます。違いはカスタマイズの度合いとカスタマイズにかかる手間です。
両方の場合、最も困難な部分はデータを取得し、ファインチューニングのために準備することです。
オープンソースモデルでは、より柔軟性があります。モデルにアクセスできるため、モデルのアーキテクチャを深く理解し、モデルの適切なファインチューニング方法だけでなく、そのパラメータも理解するために、MLの知識を持つ人物が必要です。
商用ML APIの場合、柔軟性は低くなりますが、自身の手間も少なくなります。ファインチューニングの商用APIの最良の例は、最近リリースされたGPT-3.5のファインチューニングです。他の例としては、Amazon RekognitionのカスタムラベルやMindeeのカスタムドキュメントのOCRファインチューニングAPIなどがあります。
商用ML APIは、データとラベルをAPI/インターフェースを介して提供するように求めます。そして、トレーニング、最適化、カスタムモデルの展開をあなたのために処理します。一般のモデルと同じスタックで行います。
ファインチューニングAPIを使用し、入力と出力を与え、パフォーマンスが優れていない場合は、まずプロバイダーに連絡してください。彼らはあなたのユースケースを評価し、実現可能かどうかを伝えることができます。それでも実現不可能な場合は、オープンソースモデルの詳細に深く入り込んで適応することができるMLの専門家を雇用することを検討してください。
5. セキュリティとプライバシー
セキュリティは、システムが攻撃に対してどれだけ安全かについてのことです。セキュリティの専門家がチームにいない限り、商用ML APIよりも安全なシステムを構築する可能性は低いという厳しい現実があります。商用ML APIは専任のセキュリティチームを持ち、業界基準を実装し、システムを継続的にチェックしています。
同じことをしない限り、自分で管理しているからといって、オープンソースや自己ホストのモデルを「安全」とタグ付けすることはできません。
一方、プライバシーは異なります。データがデータセンター/サーバーを経由してAPIを介して外部に出ると、あなた以外の誰かによってデータが読まれるリスクが発生します。これが規制ルールに結び付いている場合(例:会社のデータがサービスxを経由する場合、yを行う必要がある場合)、それは単にそれらのルールを尊重し、承認手続きを行うことに関わります。
プライバシーが「プロバイダが私のデータを見る」という懸念と関係がある場合、彼らのビジネスはAPI呼び出しを販売することで成り立っています。彼らが信頼できなければ、それを行うことはできません。使用する前に、APIを提供している企業を確認し、それが正確に誰であり、彼らのプライバシールールは何であるかを確認してください。確立したベンダーは、データの取り扱いについて明確に説明し、データの転送と休止時にデータを暗号化し、場合によってはデータの使用をトレーニング目的から除外するオプションを提案することさえあります。
要約とまとめ
以下は、選択するタイミングについてのガイドラインを提供するテーブルです
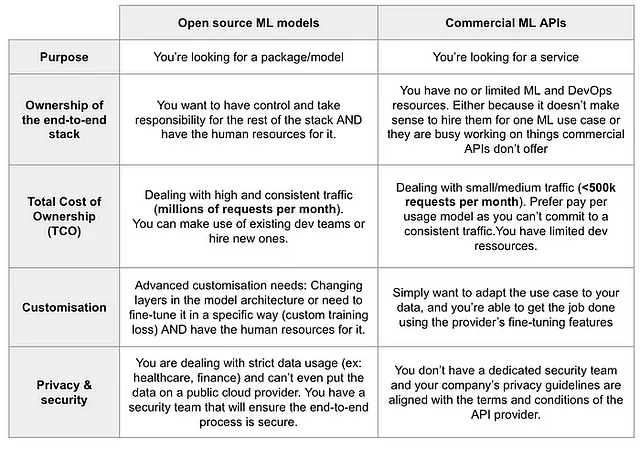
最も重要なことは、オープンソースのMLモデルと商用のML APIの両方が必要であり、それらは異なる目的に使われます。どちらがより優れているかは、上記の基準とあなたの状況によります。以下は推奨事項の要約です:
- 月間予測量が高い場合(約400〜500k以上)、オープンソースモデルを使用し、それらをホストした方が良い可能性が高いです。
- まずは商用のML APIを試してみてください。仕事が完了し、価格が予算に合っている場合は、それに固執してください。価格が若干高い場合は、同様のサービスを構築および維持するために人を雇うことがいくらかコストがかかるかを考慮してください。
- 商用のML APIの機能を微調整しても結果が悪い場合は、データを改善したり、プロバイダに連絡したりしてみてください。それでも悪い場合は、MLの専門家に投資することを検討し、MLのパフォーマンスが優れている場合は、MLエンジニア/DevOpsに投資してモデルを本番環境に展開するのに役立ててください。
お読みいただきありがとうございます!まだ会っていない方には、私はオスマンと申します。私はAWSでMLエンジニアとして5年間、30以上の企業が製品/ビジネスにMLを組み込むのを支援しました。
ご質問がありましたら、お気軽にTwitter(@OHamzaoui1)またはLinkedin(hamzaouiothmane)でお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AGENTS内部 半自律LLMエージェントを構築するための新しいオープンソースフレームワーク」
- 「大規模な言語モデルを使用した顧客調査フィードバック分析の強化」
- 「画像の匿名化はコンピュータビジョンのパフォーマンスにどのような影響を与えるのか? 伝統的な匿名化技術とリアルな匿名化技術の比較」
- ディープラーニングライブラリーの紹介:PyTorchとLightning AI
- 「Now You See Me (CME) 概念ベースのモデル抽出」
- 効果的な小規模言語モデル:マイクロソフトの13億パラメータphi-1.5
- 「BlindChat」に会いましょう:フルブラウザおよびプライベートな対話型AIを開発するためのオープンソースの人工知能プロジェクト





