デバイス上での条件付きテキストから画像生成のための拡散プラグイン
'Device上の条件付きテキストから画像生成のための拡散プラグイン'
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML
近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。
本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。
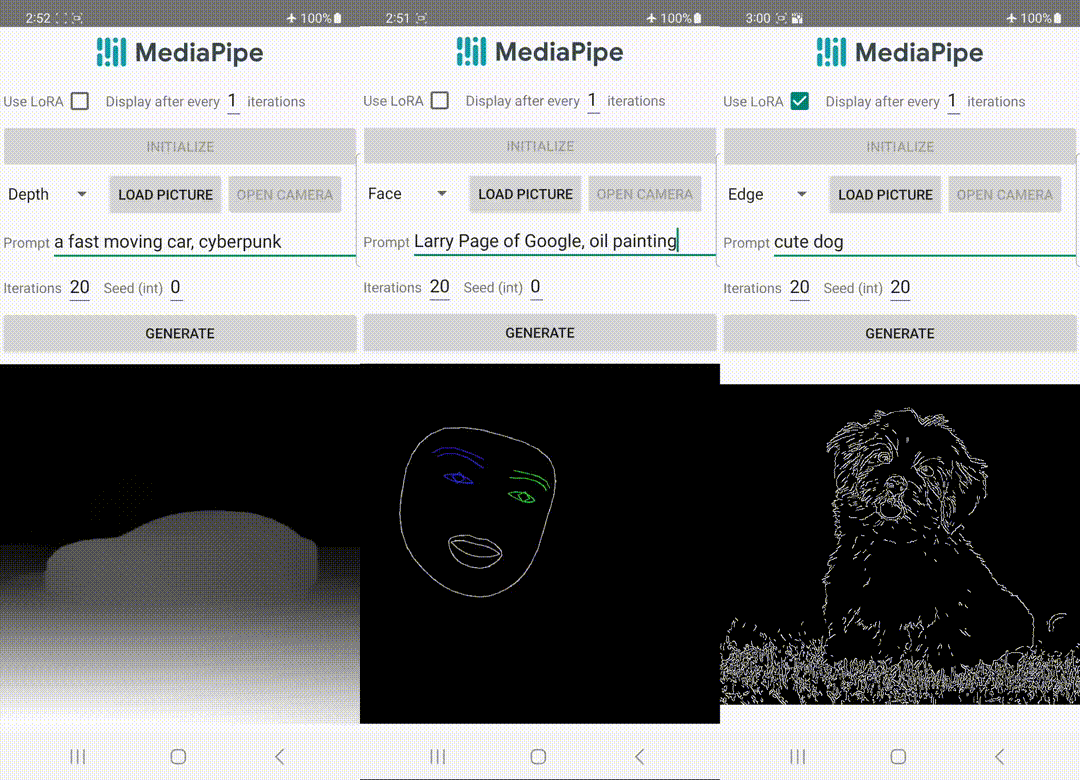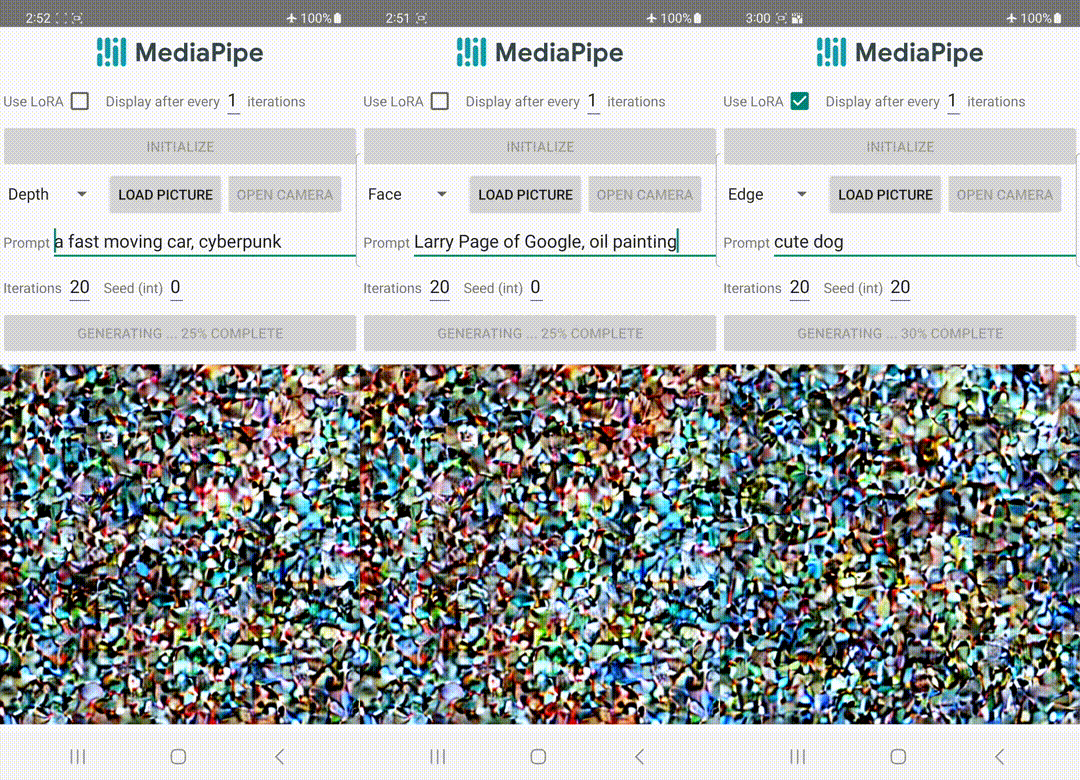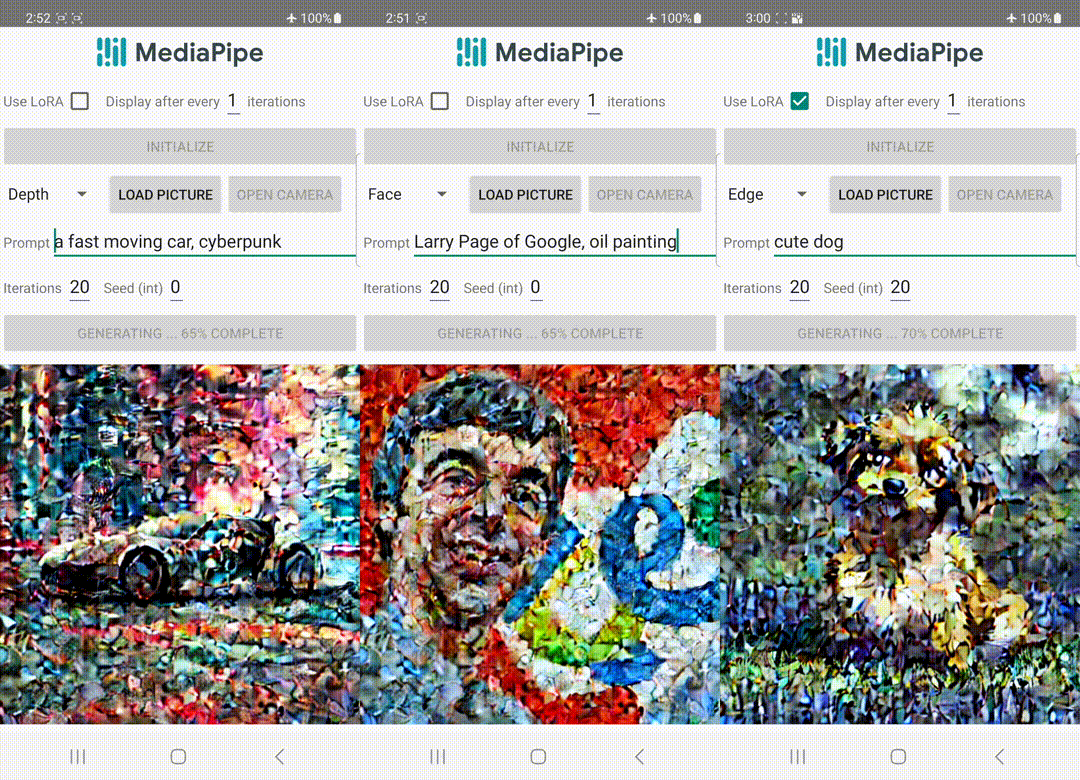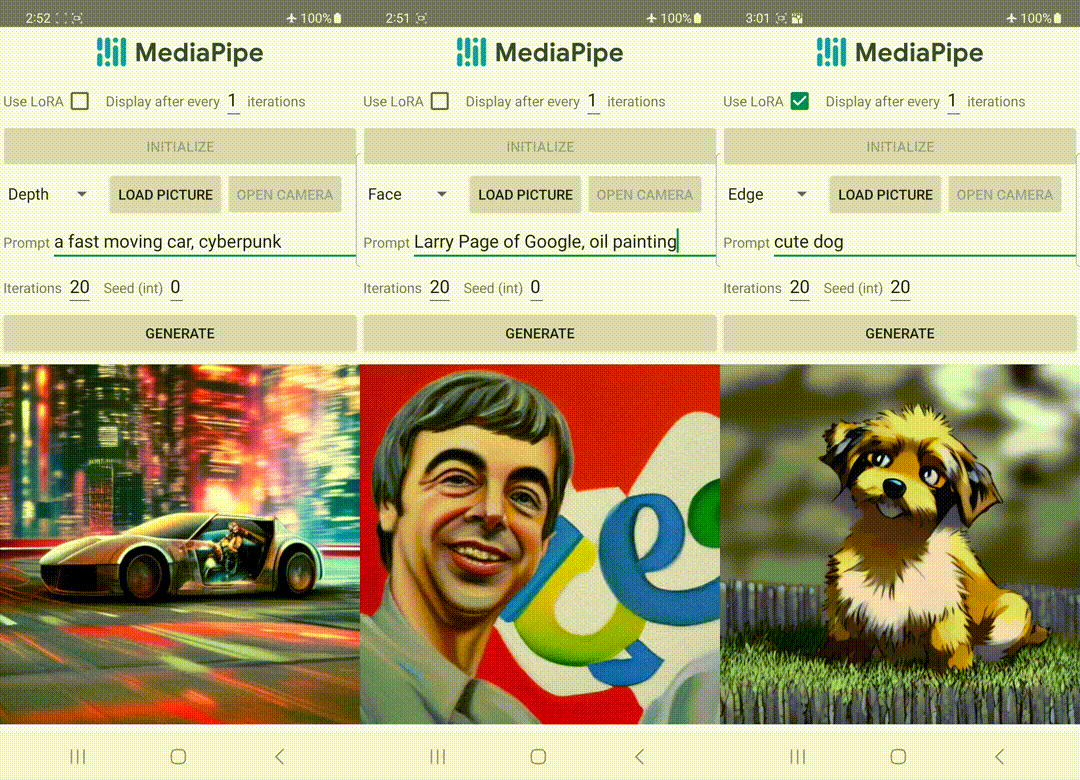 |
| デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 |
背景
拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。
- 複雑なタスクの実行におけるロボットの強化:Meta AIが人間の行動のインターネット動画を使用して視覚的な手がかりモデルを開発する
- Google DeepMindは、ChatGPTを超えるアルゴリズムの開発に取り組んでいます
- QLoRAを使用して、Amazon SageMaker StudioノートブックでFalcon-40Bと他のLLMsをインタラクティブにチューニングしてください
制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。
MediaPipe拡散プラグイン
条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています:
- プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。
- スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。
- ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。
| メソッド | パラメーターサイズ | プラグ可能 | スクラッチからトレーニング | ポータブル | ||||
| Plug-and-Play | 860M* | ✔️ | ❌ | ❌ | ||||
| ControlNet | 430M* | ✔️ | ❌ | ❌ | ||||
| T2I Adapter | 77M | ✔️ | ✔️ | ❌ | ||||
| MediaPipe Plugin | 6M | ✔️ | ✔️ | ✔️ |
| プラグアンドプレイ、ControlNet、T2Iアダプター、およびMediaPipe拡散プラグインの比較。*数値は拡散モデルの詳細によって異なります。 |
MediaPipe拡散プラグインは、テキストから画像を生成するためのポータブルなオンデバイスモデルです。これは、コンディショニング画像から多スケールの特徴を抽出し、対応するレベルの拡散モデルのエンコーダに追加されます。プラグインモデルは、わずか6Mのパラメータのみを持つ軽量モデルとして設計されています。モバイルデバイスでの高速推論のために、MobileNetv2からの深さのある畳み込みと逆ボトルネックを使用しています。
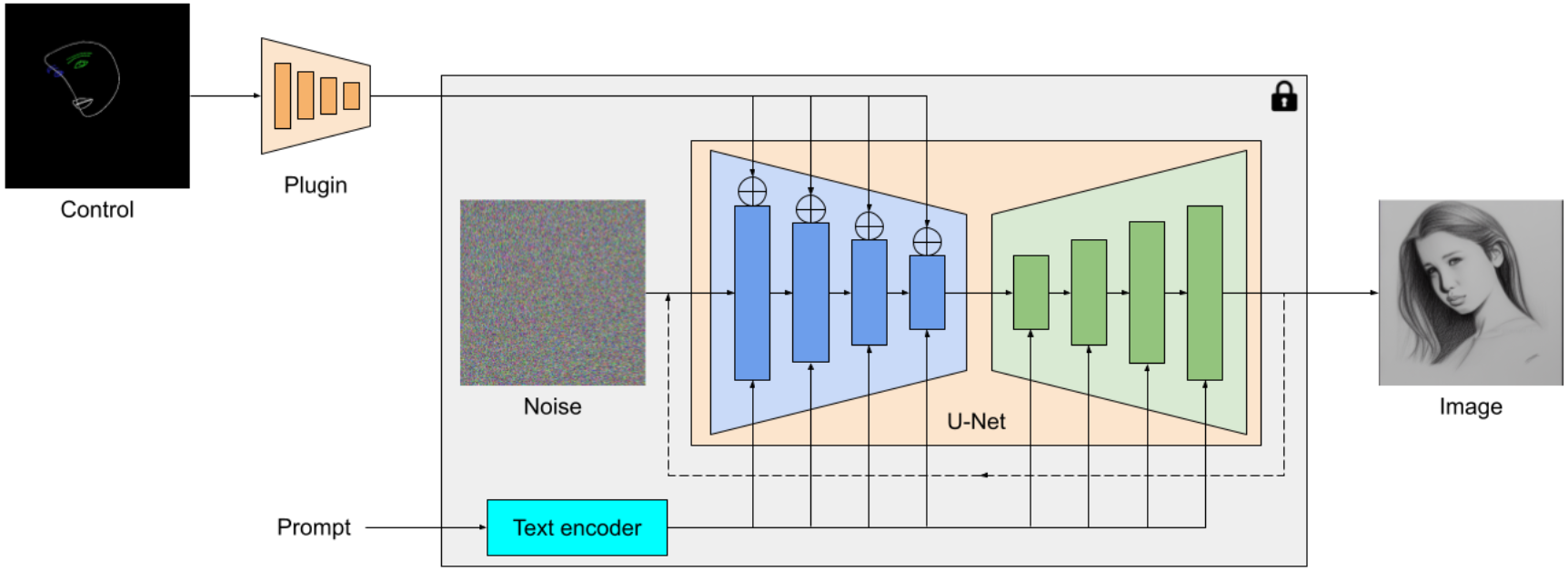 |
| MediaPipe拡散モデルプラグインの概要。プラグインは独立したネットワークであり、その出力は事前学習済みのテキストから画像を生成するモデルに接続できます。プラグインによって抽出された特徴は、拡散モデルの関連するダウンサンプリング層に適用されます(青色)。 |
ControlNetとは異なり、すべての拡散イテレーションで同じ制御特徴を注入します。つまり、1つの画像生成に対してプラグインは1回のみ実行され、計算量を節約します。以下に拡散プロセスのいくつかの中間結果を示します。制御はすべての拡散ステップで効果的であり、早い段階でも制御された生成を可能にします。より多くのイテレーションは、画像をテキストのプロンプトとより詳細な部分で整列させることができます。
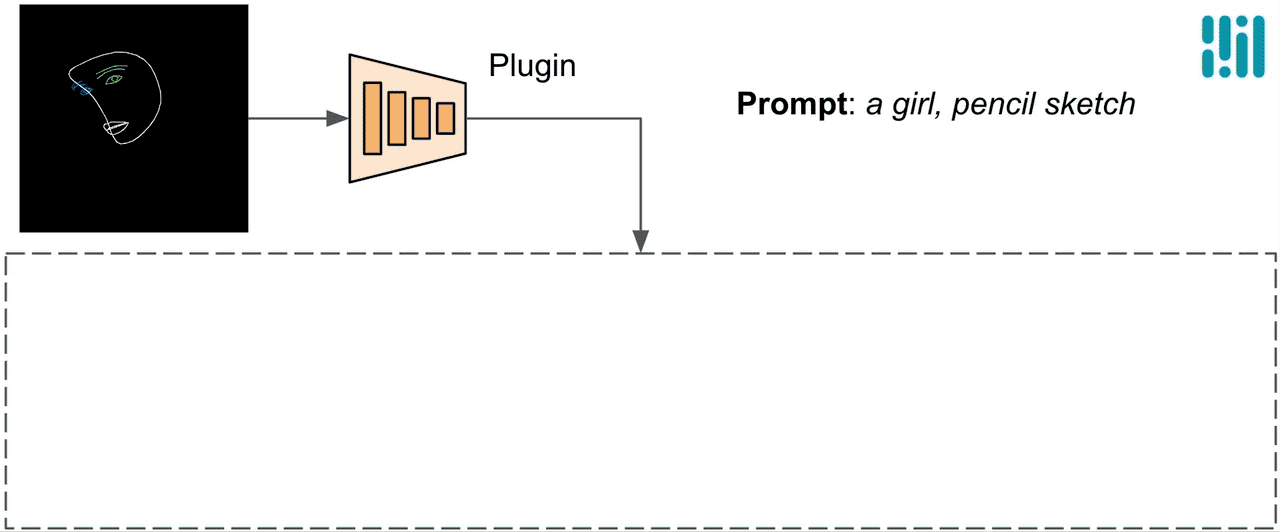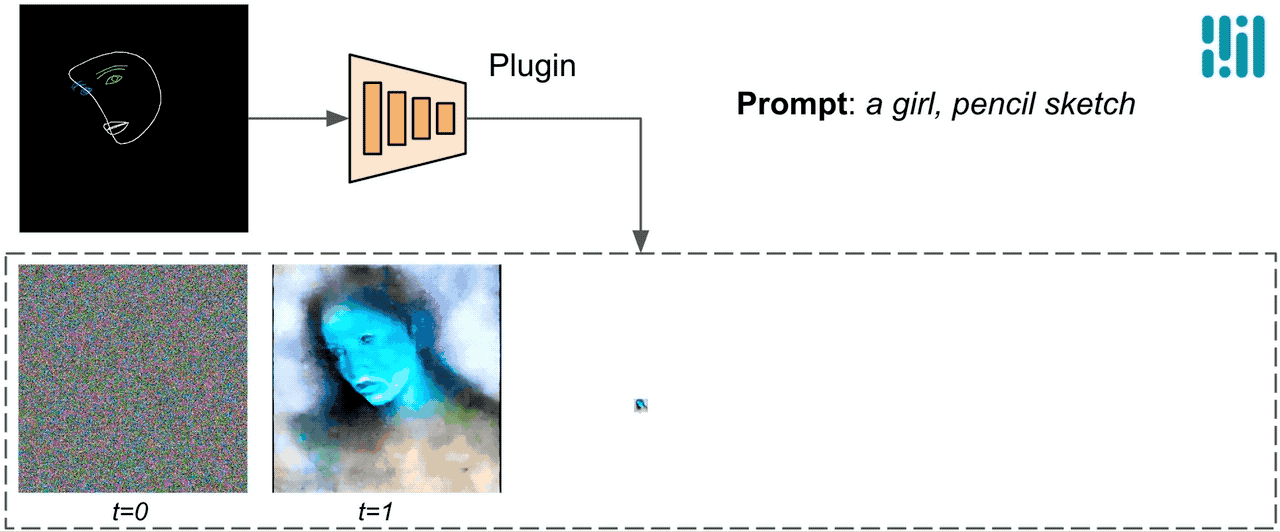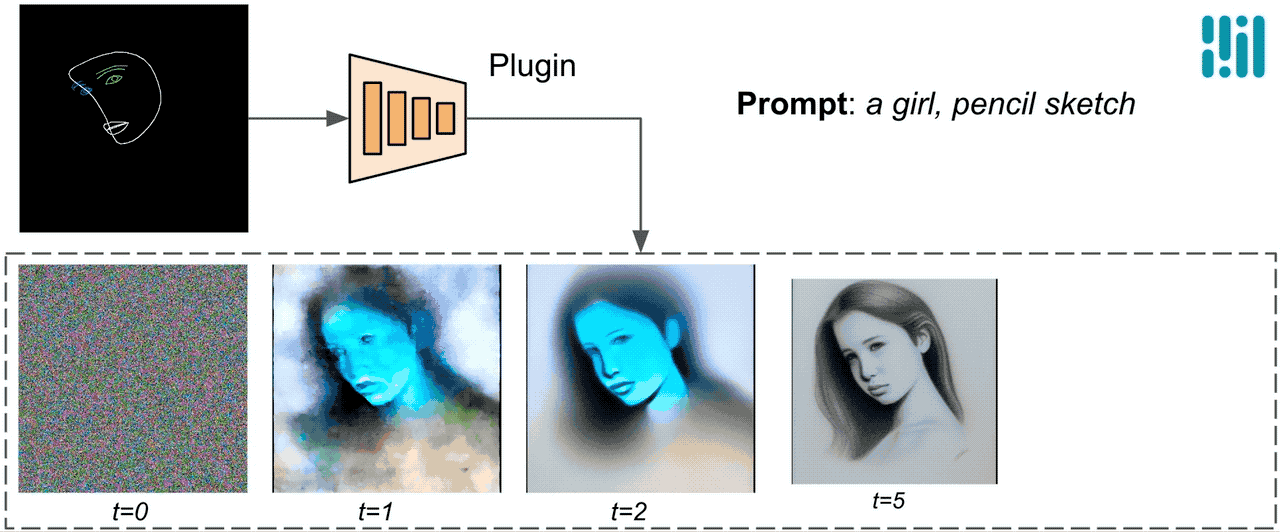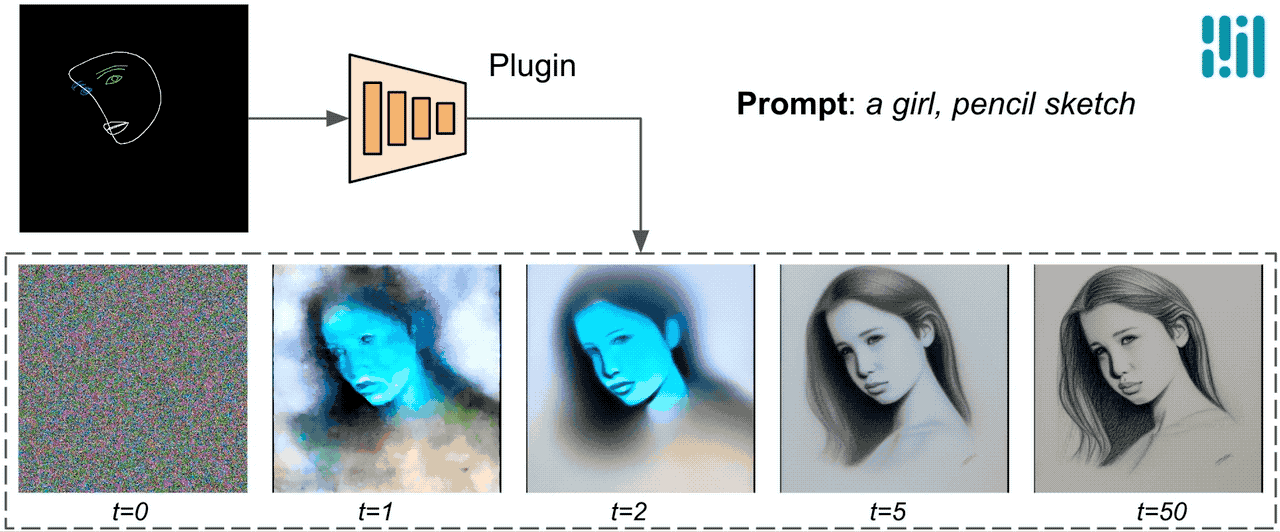 |
| MediaPipe拡散プラグインを使用した生成プロセスのイラスト。 |
例
この作業では、MediaPipe Face Landmark、MediaPipe Holistic Landmark、深度マップ、およびCannyエッジを使用した拡散ベースのテキストから画像への生成モデルのプラグインを開発しました。各タスクでは、ウェブスケールの画像テキストデータセットから約100Kの画像を選択し、対応するMediaPipeソリューションを使用して制御信号を計算します。プラグインのトレーニングにはPaLIからの洗練されたキャプションを使用します。
顔のランドマーク
MediaPipe Face Landmarkerタスクは、人間の顔の478のランドマーク(注目付き)を計算します。MediaPipeの描画ユーティリティを使用して、顔の輪郭、口、目、眉、虹彩などを異なる色でレンダリングします。以下の表は、顔のメッシュとプロンプトに基づいてランダムに生成されたサンプルを示しています。比較のために、ControlNetとプラグインの両方が条件付きでテキストから画像を生成できます。
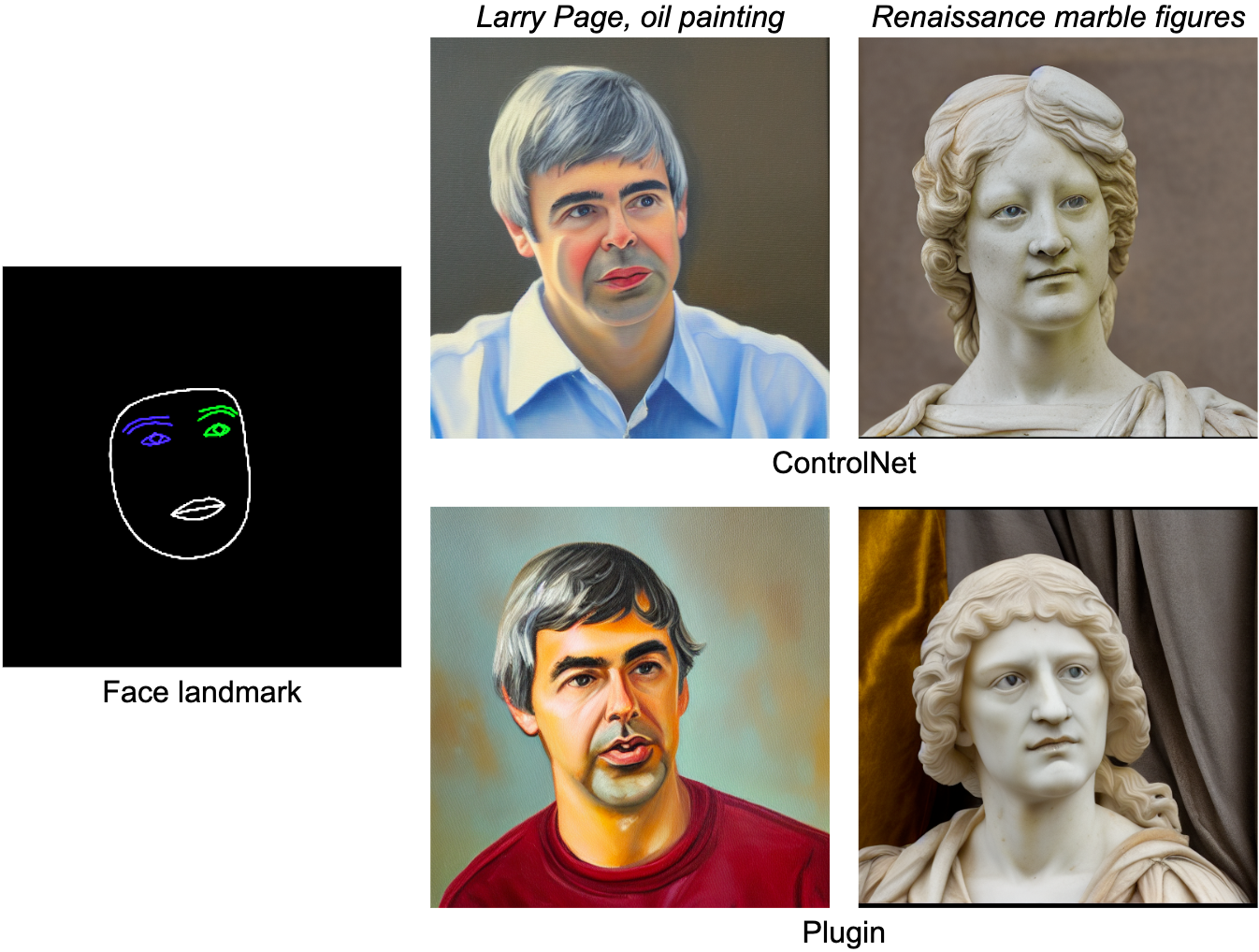 |
| 顔のランドマークプラグインによるテキストから画像の生成、ControlNetとの比較。 |
ホリスティックランドマーク
MediaPipeのホリスティックランドマーカータスクには、ボディポーズ、手、および顔メッシュのランドマークが含まれています。以下では、ホリスティックフィーチャーに基づいてさまざまなスタイルの画像を生成します。
 |
| テキストから画像を生成するためのホリスティックランドマークプラグインです。 |
デプス
 |
| テキストから画像を生成するためのデプスプラグインです。 |
Cannyエッジ
 |
| テキストから画像を生成するためのCannyエッジプラグインです。 |
評価
私たちは、顔ランドマークプラグインの性能を示すために、定量的な研究を行っています。評価データセットには5,000枚の人間の画像が含まれています。私たちは、広く使用されている指標であるフレシェ・インセプション・ディスタンス(FID)とCLIPスコアによる生成品質を比較します。ベースモデルは、事前学習済みのテキストから画像への拡散モデルです。ここではStable Diffusion v1.5を使用しています。
以下の表に示されているように、ControlNetとMediaPipeの拡散プラグインの両方が、FIDとCLIPスコアの観点でベースモデルよりもはるかに優れたサンプル品質を生成します。ControlNetは各拡散ステップで実行する必要がありますが、MediaPipeプラグインは生成された各画像に対して一度だけ実行されます。私たちは、サーバーマシン(NVIDIA V100 GPU搭載)とモバイル電話(Galaxy S23)で3つのモデルのパフォーマンスを測定しました。サーバーでは、50の拡散ステップで3つのモデルを実行し、モバイルでは、MediaPipe画像生成アプリを使用して20の拡散ステップを実行します。ControlNetと比較して、MediaPipeプラグインは推論効率に明確な利点を示しながら、サンプル品質を保持しています。
| モデル | FID↓ | CLIP↑ | 推論時間(秒) | |||||
| NVIDIA V100 | Galaxy S23 | |||||||
| ベース | 10.32 | 0.26 | 5.0 | 11.5 | ||||
| ベース + ControlNet | 6.51 | 0.31 | 7.4(+48%) | 18.2(+58.3%) | ||||
| ベース + MediaPipeプラグイン | 6.50 | 0.30 | 5.0(+0.2%) | 11.8(+2.6%) |
| FID、CLIP、および推論時間の定量的な比較。 |
本プラグインのパフォーマンスを、中堅からハイエンドまでの幅広いモバイルデバイスでテストします。以下の表には、AndroidとiOSの両方をカバーするいくつかの代表的なデバイスでの結果がリストされています。
| デバイス | Android | iOS | ||||||||||
| Pixel 4 | Pixel 6 | Pixel 7 | Galaxy S23 | iPhone 12 Pro | iPhone 13 Pro | |||||||
| 時間 (ms) | 128 | 68 | 50 | 48 | 73 | 63 |
| さまざまなモバイルデバイス上でのプラグインの推論時間 (ms)。 |
結論
本研究では、条件付きテキストから画像生成するためのポータブルなMediaPipeプラグインを提案しています。このプラグインは、条件画像から抽出した特徴を拡散モデルに注入し、画像生成を制御します。ポータブルなプラグインは、サーバーやデバイス上で実行される事前学習済みの拡散モデルに接続することができます。デバイス上で完全にテキストから画像生成とプラグインを実行することにより、より柔軟な生成AIの応用が可能になります。
謝辞
この作業に貢献してくれたすべてのチームメンバーに感謝します。GPU推論ソリューションのためのRaman SarokinさんとJuhyun Leeさん、リーダーシップのためのKhanh LeVietさん、Chuo-Ling Changさん、Andrei Kulikさん、Matthias Grundmannさんに特に感謝します。また、この技術とデモをデバイス上で実行できるようにしたJiuqiang Tangさん、Joe Zouさん、Lu wangさんにも特別な感謝を申し上げます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles