SparkとPlotly Dashを使用したインタラクティブで洞察力のあるダッシュボードの開発
Development of an interactive and insightful dashboard using Spark and Plotly Dash.
PythonによるWebアプリケーションでのインタラクティブな大規模データ可視化

1. はじめに
クラウドデータレイクは、エンタープライズ組織によって、すべてのタイプ(構造化および非構造化)のデータのスケーラブルかつ低コストなリポジトリとして広く採用されています。大規模なデータセットから意義のある洞察を得るために、データレイクからの大規模なデータセットの効率的な分析には多くの課題があります。1つの課題は、データセットのサイズが1つのマシンに収まりきらないことです。大規模なデータセットを処理するためには、通常、サーバーのクラスターが必要です。もう1つの課題は、関連する顧客/株主のサーバー上でのデータ分析の結果をどのように簡単かつ費用効果的に共有するかです。
本論文では、Spark[2][3]とPlotly Dash[4]を使用したオープンソースベースのWebアプリケーションフレームワークを示すために、[1]で使用された同じオープンソースデータセットを使用しています。このフレームワークを使用すると、サーバー上で大規模なデータセットを分析して可視化し、データ分析と可視化の結果をダッシュボードとしてどこでも共有できます。
図1に示すように、新しいWebアプリケーションフレームワークは、3つの主要なコンポーネントで構成されています。
- 分散データ処理のためのSpark SQLサービス(DataFrameなど)(セクション2を参照)
- データ可視化グラフをダッシュボードとして作成するためのPlotlyグラフィングサービス(セクション3を参照)
- サーバーサイドのPlotlyグラフィングサービスとダッシュボードクライアントとの相互作用のためのDash Webサービス(セクション4を参照)

2. 分散データ処理のためのSpark SQLサービス
[2]に記載されているように、PySpark(SparkのPython API)を使用して、AWS S3などのクラウドデータレイクからCSVファイルを簡単に読み取ることができます。本論文では、代表性を失わずに、CSVファイルtrain_data.csv [1]がローカルマシンで利用可能であると仮定しています。
以下のコードは、CSVファイルをSpark SQL DataFrameとしてメモリにロードするためのものです。
import pysparkfrom pyspark.sql import SparkSessionspark = SparkSession.builder.appName('hospital-stay').getOrCreate()spk_df = spark.read.csv('./data/train_data.csv', header = True, inferSchema = True)データをロードした後、動的なデータクエリの利便性のために、グローバル一時ビューを作成できます。
spk_df.createOrReplaceTempView("dataset_view")データセットビューが作成されたら、データベースから通常のデータクエリと同様にSpark SQLを使用してデータをクエリできます。例えば、以下のコードは、人々の年齢が[21、30]の範囲にあるすべての行をデータセット_viewからクエリします。
age = "21-30"sdf = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'")Spark DataFrame sdfからデータ可視化グラフを作成するためにPlotlyを使用するには、Spark DataFrameを直接サポートしていないため、Pandas DataFrameに変換する必要があります。
pdf = sdf.toPandas()3. データ可視化グラフを作成するためのPlotly
Plotlyは、多くの異なるタイプのグラフを生成することができます。いくつかは連続的な数値特徴からグラフを作成するのに適しており、他のものは離散的なカテゴリ特徴からグラフを作成するのに適しています。
本論文では、デモンストレーション目的で、Plotly Expressライブラリを使用して、次のような一般的な図を作成します。
- 数値特徴のグラフ: 散布図、ヒストグラムチャート、折れ線グラフ
- カテゴリ特徴のグラフ: 棒グラフ、ヒストグラムチャート、折れ線グラフ、円グラフ
3.1 数値特徴のグラフ
以前述为例,数值特征的三个常见图表如下:
- 散点图
- 直方图
- 折线图
给定一对数值特征,散点图将每对特征值用作坐标,在二维平面上绘制一个点。例如,下图显示了年龄在21至30岁之间的人的两个数值特征患者ID和入院押金的散点图。特征“入院类型”用于颜色编码。
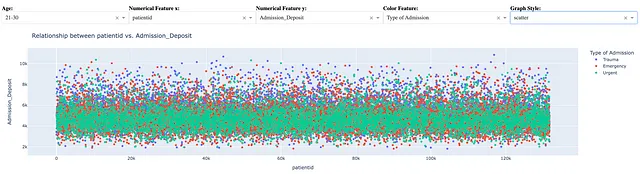
假设仪表板用户已选择年龄范围[21, 30],数值特征对x = 患者ID和y = 入院押金,颜色编码特征=入院类型,下面的语句创建了上述散点图。
fig = px.scatter(dff, x = x, y = y, color = color_feature)类似地,以下语句用于创建相同数据的直方图:
fig = px.histogram(dff, x = x, y = y, color = color_feature)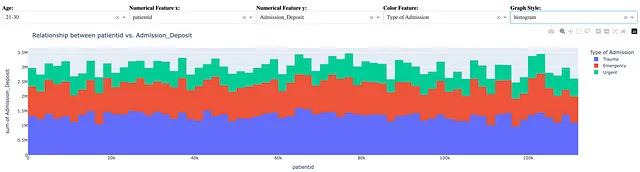
为了完整起见,以下语句用于创建折线图。
fig = px.ine(dff, x = x, y = y, color = color_feature)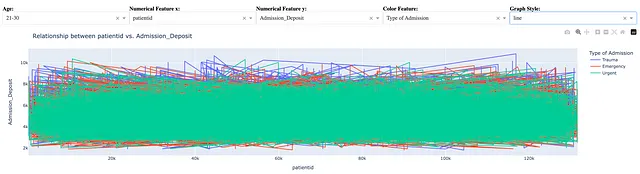
尽管我们可以轻松创建折线图,但像上面的折线图并不揭示有用的见解。折线图的好处是将其应用于有意义的排序数据集,例如按时间顺序排列的数据序列或按计数排序的特征值列表,如第3.2节所示。
3.2分类特征的图表
本小节展示了四种常见的分类特征的图表:
- 条形图
- 直方图
- 折线图
- 饼图
假设仪表板用户已选择年龄[21-30],分类特征=留存,颜色=紫色,图表样式=条形图,则可以使用以下代码生成下面的条形图。
dff = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'").toPandas()vc = dff[feature].value_counts()fig = px.bar(vc, x = vc.index, y = vc.values)我注意到直方图的结果与分类特征值计数的条形图相同。
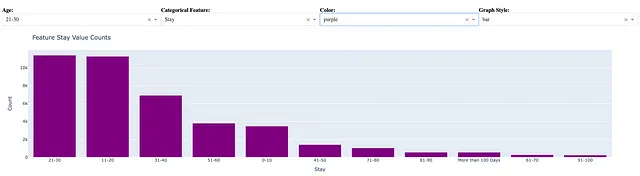
我们可以通过选择图表样式=线来创建以下线图:
fig = px.line(vc, x = vc.index, y = vc.values)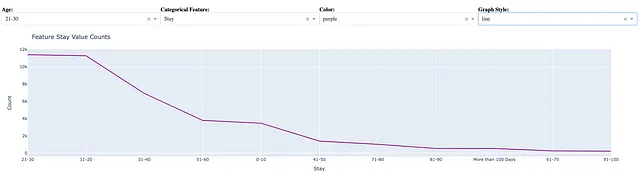
前述のように、ラインチャートはカテゴリカルな特徴量の値のカウントを視覚化するのに適しています。
以下のコードは Stay の同じカテゴリカル特徴量の値のカウント用のパイチャートを作成するものです。
fig = px.pie(vc, x = vc.index, y = vc.values)このパイチャートは、選択した紫色の代わりに自動的なカラーコーディングを使用しています。
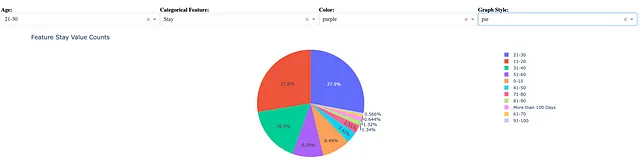
4. インタラクティブなデータ可視化のためのDash
前のセクションでは、Sparkサーバーのクラスター上でPlotly Expressライブラリを使用してさまざまな種類のグラフを使用してダッシュボードを作成する方法について説明しました。このセクションでは、Dashを使用してダッシュボードをWebアプリケーションクライアントと共有し、クライアントが対話的にデータを視覚化するためにダッシュボードを使用できるようにする方法を示します。
Webアプリケーションの1ページのダッシュボードを開発するには、次の手順を実行できます。
- ステップ1:Dashライブラリモジュールをインポート
- ステップ2:Dashアプリケーションオブジェクトを作成
- ステップ3:HTMLページのダッシュボードレイアウトを定義
- ステップ4:コールバック関数(Webサービスエンドポイント)を定義
- ステップ5:サーバーを開始
4.1 Dashライブラリモジュールのインポート
最初のステップとして、この論文でのデモンストレーションの目的で、Plotly Dashライブラリモジュールを次のようにインポートします。
import plotly.express as pxfrom dash import Dash, dcc, html, callback, Input, Output4.2 Dashアプリケーションオブジェクトの作成
ライブラリモジュールをインポートした後、次のステップはDashアプリケーションオブジェクトを作成することです。
app = Dash(__name__)4.3 ダッシュボードレイアウトの定義
Dashアプリケーションオブジェクトが作成されたら、HTMLページとしてダッシュボードレイアウトを定義する必要があります。
この論文では、ダッシュボードHTMLページは2つの部分に分かれています:
- Part1:数値特徴量の視覚化
- Part2:カテゴリカル特徴量の視覚化
ダッシュボードレイアウトのPart1は次のように定義されます:
app.layout = html.Div([ # dashboard layout html.Div([ # Part 1 html.Div([ html.Label(['Age:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['0-10', '11-20', '21-30', '31-40', '41-50', '51-60', '61-70', '71-80', '81-90', '91-100', 'More than 100 Days'], value='21-30', id='numerical_age' ), ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Numerical Feature x:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['patientid', 'Hospital_code', 'City_Code_Hospital'], value='patientid', id='axis_x', ) ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Numerical Feature y:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['Hospital_code', 'Admission_Deposit', 'Bed Grade', 'Available Extra Rooms in Hospital', 'Visitors with Patient', 'Bed Grade', 'City_Code_Patient'], value='Admission_Deposit', id='axis_y' ), ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Color Feature:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['Severity of Illness', 'Stay', 'Department', 'Ward_Type', 'Ward_Facility_Code', 'Type of Admission', 'Hospital_region_code'], value='Type of Admission', id='color_feature' ), ], style={'width': '20%', 'display': 'inline-block'}), html.Div([ html.Label(['Graph Style:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['scatter', 'histogram', 'line'], value='histogram', id='numerical_graph_style' ), ], style={'width': '20%', 'float': 'right', 'display': 'inline-block'}) ], style={ 'padding': '10px 5px' }), html.Div([ dcc.Graph(id='numerical-graph-content') ]),......図2、3、4はダッシュボードのレイアウトのPart 1を使用して作成されました。
ダッシュボードのレイアウトのPart 2は、以下のように定義されます:
......html.Div([ # Part 2 html.Div([ html.Label(['年齢:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['0-10', '11-20', '21-30', '31-40', '41-50', '51-60', '61-70', '71-80', '81-90', '91-100', '100日以上'], value='21-30', id='categorical_age' ), ], style={'width': '25%', 'display': 'inline-block'}), html.Div([ html.Label(['カテゴリ特徴:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['病気の深刻度', '滞在期間', '部署', '病棟タイプ', '病棟施設コード', '入院タイプ', '病院地域コード'], value='滞在期間', id='categorical_feature' ), ], style={'width': '25%', 'display': 'inline-block'}), html.Div([ html.Label(['色:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown( ['赤', '緑', '青', 'オレンジ', '紫', '黒', '黄'], value='青', id='categorical_color' ), ], style={'width': '25%', 'display': 'inline-block'}), html.Div([ html.Label(['グラフのスタイル:'], style={'font-weight': 'bold', "text-align": "center"}), dcc.Dropdown([ 'ヒストグラム', '棒グラフ', '折れ線グラフ', '円グラフ'], value='棒グラフ', id='categorical_graph_style' ), ], style={'width': '25%', 'float': 'right', 'display': 'inline-block'}) ], style={ 'padding': '10px 5px' }), html.Div([ dcc.Graph(id='categorical-graph-content') ])]) # ダッシュボードのレイアウトの終わり図5、6、7はダッシュボードのレイアウトのPart 2を使用して作成されました。
4.4 コールバック関数を定義する
ダッシュボードのレイアウトは、ダッシュボードの静的なHTMLページを作成するだけです。コールバック関数(すなわち、Webサービスのエンドポイント)を定義する必要があります。これにより、ダッシュボードのユーザーアクションがWebサービスリクエストとしてサーバーサイドのコールバック関数に送信されます。つまり、コールバック関数により、ダッシュボードのユーザーとサーバーサイドのダッシュボードWebサービスとの間で対話が可能になります。たとえば、ユーザーがドロップダウンの選択肢を選択すると、新しいグラフが作成されます。
この論文では、ダッシュボードレイアウトの2つの部分に対して2つのコールバック関数が定義されています。
ダッシュボードレイアウトのPart 1のコールバック関数は、以下のように定義されます:
@callback( Output('numerical-graph-content', 'figure'), Input('axis_x', 'value'), Input('axis_y', 'value'), Input('numerical_age', 'value'), Input('numerical_graph_style', 'value'), Input('color_feature', 'value'))def update_numerical_graph(x, y, age, graph_style, color_feature): dff = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'").toPandas() if graph_style == 'line': fig = px.line(dff, x = x, y = y, color = color_feature ) elif graph_style == 'histogram': fig = px.histogram(dff, x = x, y = y, color = color_feature ) else: fig = px.scatter(dff, x = x, y = y, color = color_feature ) fig.update_layout( title=f"{x} vs. {y}の関係", ) return figダッシュボードレイアウトのPart 2のコールバック関数は、以下のように定義されます:
@callback( Output('categorical-graph-content', 'figure'), Input('categorical_feature', 'value'), Input('categorical_age', 'value'), Input('categorical_graph_style', 'value'), Input('categorical_color', 'value'))def update_categorical_graph(feature, age, graph_style, color): dff = spark.sql(f"SELECT * FROM dataset_view WHERE Age=='{age}'").toPandas() vc = dff[feature].value_counts() if graph_style == 'bar': fig = px.bar(vc, x = vc.index, y = vc.values ) elif graph_style == 'histogram': fig = px.histogram(vc, x = vc.index, y = vc.values ) elif graph_style == 'line': fig = px.line(vc, x = vc.index, y = vc.values ) else: fig = px.pie(vc, names = vc.index, values = vc.values ) if graph_style == 'line': fig.update_traces(line_color=color) elif graph_style != 'pie': fig.update_traces(marker_color=color) fig.update_layout( title=f"{feature}の値の数", xaxis_title=feature, yaxis_title="カウント" ) return fig各々のコールバック関数は、アノテーション @callback に関連付けられます。コールバック関数に関連付けられたアノテーションは、ユーザーの要求に応じてどのHTMLコンポーネント(例:ドロップダウン)がコールバック関数に入力を提供し、どのHTMLコンポーネント(例:divタグ内のグラフ)がコールバック関数の出力を受け取るかを制御します。
4.5 サーバーの起動
Dash Webアプリケーションの最後のステップは、以下のようにWebサービスサーバーを起動することです。
if __name__ == "__main__": app.run_server()以下の図は、ダッシュボードユーザーがダッシュボードで以下の選択肢を選択した場合のダッシュボードの1つのシナリオを示しています。
- 年齢が21〜30歳
- 数値特徴量のペアであるpatientidとAdmission_Deposit
- 数値特徴量の可視化のためのカテゴリカル特徴量であるType of Admissionのカラーコーディング
- 数値特徴量の可視化のための散布図
- 特徴量値のカウントを計算するためのカテゴリカル特徴量であるStay
- 棒グラフ、ヒストグラム、および折れ線グラフの青色
- 自動的なカラーコーディングによるカテゴリカル特徴量値のカウントの視覚化のためのパイグラフ
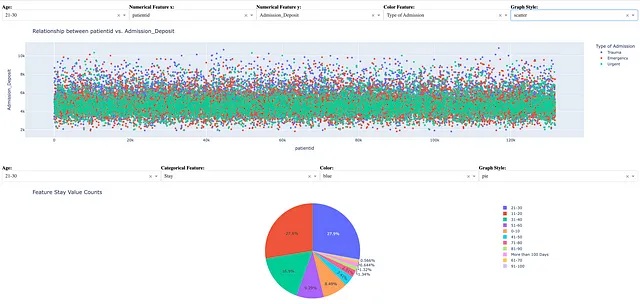
上記のダッシュボードシナリオは、以下のインサイトを明らかにします。
- 21〜30歳の大多数の患者は、どのくらい長く入院していようとも、$3,000から$6,000の間のデポジットを持っていました。
- 21〜30歳の大多数の患者は、11〜30日(27.6%)または21〜30日(27.9%)に入院しました。
以下の図は、ダッシュボードユーザーがダッシュボードで以下の選択肢を選択した場合のダッシュボードの別のシナリオを示しています。
- 年齢が21〜30歳
- 数値特徴量のペアであるpatientidとAdmission_Deposit
- 数値特徴量の可視化のためのカテゴリカル特徴量であるType of Admissionのカラーコーディング
- 数値特徴量の可視化のためのヒストグラム
- カテゴリカル特徴量であるType of Admission
- 棒グラフ、ヒストグラム、および折れ線グラフの緑色
- カテゴリカル特徴量値のカウントの視覚化のための棒グラフ
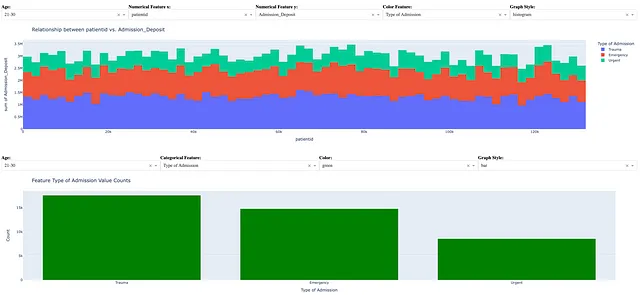
上記のダッシュボードシナリオは、以下のインサイトを明らかにします。
- 緊急ケアの患者は、その他の入院タイプの患者よりも高い合計デポジットを持っていました。
- 患者の大多数は、外傷として入院しました。
要約すると、ダッシュボードを使用すると、以下のように柔軟な方法でデータを視覚化して、相互に有用なインサイトを得ることができます。
- 年齢の範囲(0〜10、11〜20など)で数値特徴量およびカテゴリカル特徴量を視覚化する。
- 散布図、ヒストグラム、および/または折れ線グラフで任意の数値特徴量のペアを視覚化する。
- 数値特徴量の可視化のための任意のカテゴリカル特徴量値のカラーコーディングを使用する。
- 棒/ヒストグラムグラフ、折れ線グラフ、および/または異なるカラーコーディングを使用したピーチャートで任意のカテゴリカル特徴量の値をカウントして視覚化する。
5. 結論
本論文では、Spark [3]とPlotly Dash [4]を使用してインタラクティブで洞察力のあるダッシュボードを開発するためのPythonベースのオープンソースWebアプリケーションフレームワークを紹介しました。このフレームワークにより、Cloudデータレイクから大規模なデータセットを分析し、Sparkサーバー上でインタラクティブなダッシュボードを作成し、ユーザーがどこからでもダッシュボードと対話して柔軟な方法でデータを視覚化し、さまざまな有用なインサイトを得ることができます。
参考文献
[1] Yu Huang, Predicting Hospitalized Time of Covid-19 Patients
[2] PySpark AWS S3 Read Write Operations
[3] Apache Spark examples
[4] Dash Python User Guide
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
