「全体的なメンタルモデルを持つAI製品の開発」
Development of AI products with a comprehensive mental model
AI製品の発案、計画、定義のためのクロスディシプリナリーチームによるツール
注:この記事は「AIアプリケーションの解剖学」というシリーズの最初の記事です。このシリーズでは、AIシステムのためのメンタルモデルを紹介します。このモデルは、クロスディシプリナリーなAIチームや製品チーム、さらにはビジネス部門との調整に役立つツールとして、AI製品の議論、計画、定義に使用されます。このモデルは、プロダクトマネージャー、UXデザイナー、データサイエンティスト、エンジニアなど、チームメンバーのさまざまな視点を結びつけることを目指しています。この記事では、メンタルモデルを紹介し、将来の記事では具体的なAI製品や機能への適用方法を示します。
企業はしばしば、AIを提供に取り入れるためにAIの専門家を雇い、彼らに技術的な魔術をしてもらうだけで十分だと想定しています。しかし、このアプローチは統合の誤謬に直結しています。たとえこれらの専門家やエンジニアが優れたモデルやアルゴリズムを生み出したとしても、その成果物はしばしばプレイグラウンドやデモのレベルでとどまり、実際の製品の一部として完全に成熟することはありません。私はこれまでに、データサイエンティストやエンジニアが技術的に優れたAIの実装をしても、ユーザーに直面した製品に組み込まれなかったという大いなる失望を目にしてきました。それどころか、それらはAIの波に乗っているという印象を内部の関係者に与える、最先端の実験という名誉ある地位を持っていました。2022年のChatGPTの発表以来、AIの普及が広範になった今、企業はAIを「目印」として使用して技術的な資質をアピールすることはできなくなりました。
なぜAIを統合するのがこんなに難しいのでしょうか?いくつかの理由があります:
- チームはしばしばAIシステムの一つの側面に焦点を当てます。これにより、データ中心、モデル中心、ヒューマン中心のAIなど、別々のキャンプが生まれることさえあります。それぞれが研究において魅力的な視点を提供している一方で、現実の製品はデータ、モデル、ヒューマンマシンインタラクションを統一したシステムに組み合わせる必要があります。
- AIの開発は非常に協力的な取り組みです。従来のソフトウェア開発では、バックエンドとフロントエンドのコンポーネントという比較的明確な二分法で作業します。しかしAIでは、チームにさまざまな役割とスキルを追加するだけでなく、異なる関係者間での緊密な協力も確保する必要があります。AIシステムの異なるコンポーネントは、お互いと密接にやり取りします。たとえば、仮想アシスタントに取り組んでいる場合、UXデザイナーは自然なユーザーフローを作成するためにプロンプトエンジニアリングを理解する必要があります。データの注釈付け担当者は、ブランドや仮想アシスタントの「キャラクター的特性」を把握し、ユーザーとのポジショニングに一貫性があり、整合性のあるトレーニングデータを作成する必要があります。プロダクトマネージャーは、データパイプラインのアーキテクチャを把握し、ユーザーのガバナンスに対応していることを確認するために、データパイプラインのアーキテクチャを理解し、精査する必要があります。
- AIを構築する際、企業はしばしばデザインの重要性を過小評価します。AIはバックエンドで始まりますが、本番で輝かせるためには優れたデザインが不可欠です。AIデザインは従来のUXの枠を超えます。提供する機能の多くは、インターフェース上では直接見えないが、モデルに「隠されて」おり、ユーザーにこれらの利点を最大限に活用するために教育し、ガイドする必要があります。さらに、現代の基礎モデルは、有害な出力を生み出すことがあり、これらのリスクを軽減するための追加のガードレールを設定する必要があります。これには、プロンプトエンジニアリングや会話設計など、新しいスキルがチームに必要な場合もあります。時には、ユーザーの期待を管理するために価値を過小評価したり、制御と透明性を高めるために摩擦を増やしたりするなど、直感に反することも行う必要があります。
- AIのハイプは圧力を生み出します。多くの企業は、顧客や市場のニーズに検証されていない実装に飛びつくことで、馬車を馬の前に置いてしまいます。AIのキーワードを散りばめることで、市場でのポジショニングを進歩的で革新的なビジネスとしてアピールすることはできますが、長期的にはブランドや実験を実際の機会と結びつける必要があります。これは、市場の機会を技術のポテンシャルに明示的にマッピングすることに基づくビジネスとテクノロジーの密な連携によって実現できます。
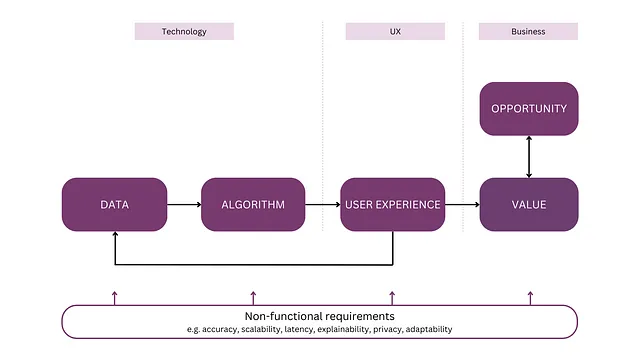
この記事では、これらの異なる側面を統合するAIシステムのためのメンタルモデルを構築します(図1参照)。これにより、ビルダーは総合的に考え、目標とする製品を明確に理解し、新たな洞察と入力でアップデートすることができます。このモデルは、協力を容易にし、AIチーム内外のさまざまな視点を調整し、共有のビジョンに基づいて成功する製品を構築するためのツールとして使用することができます。これは、新しいAI駆動の製品だけでなく、既存の製品に組み込まれるAI機能にも適用することができます。
- 「Declarai、FastAPI、およびStreamlitを使用したLLMチャットアプリケーション— パート2 🚀」
- ReAct、Reasoning and Actingは、LLMをツールで拡張します!
- コンピュータビジョンの革新:進歩、課題、そして将来の方向性
次のセクションでは、各コンポーネントについて簡単に説明し、AI製品に特有の部分に焦点を当てます。まずはビジネスの視点から始めて、市場の機会と価値について説明し、その後、UXとテクノロジーについて掘り下げていきます。このモデルを説明するために、マーケティングコンテンツの生成のための共同操縦士のランニングエグザンプルを使用します。各コンポーネントの詳細な考察は、この記事の範囲外ですので、このシリーズのより多くの記事や、私の新刊「製品マネージャーのための人工知能」をお楽しみにしてください。
1. 機会
AIでできるすべてのクールなことを考えると、手を汚して開発を始めたくなるかもしれません。しかし、ユーザーが必要とし、愛用してもらうためには、開発を市場の機会に基づかせる必要があります。理想的な世界では、機会は顧客から届き、彼らが必要とするものや欲しいものを教えてくれます。これらは未解決のニーズ、痛みのポイント、または欲望である可能性があります。既存の顧客フィードバック(製品レビューや営業・成功チームのノートなど)からこの情報を探すことができます。また、自分自身も製品の潜在的なユーザーとして忘れずに考えてください。自分自身が経験した問題をターゲットにしている場合、この情報の優位性は追加の利点になります。さらに、調査やインタビューなどのツールを使用して、積極的な顧客調査も行うことができます。
例えば、スタートアップや大企業におけるコンテンツマーケティングの苦労を見るまで遠くを探す必要はありません。私自身も経験しています。競争が激化するにつれて、個別の定期的で高品質なコンテンツでの思考リーダーシップの開発がますます重要になります。一方で、少人数で忙しいチームでは、週のブログ記事を書くよりも重要なタスクが常にあります。また、ネットワーク内の人々ともよく会うのですが、一貫したコンテンツマーケティングのルーティン設定に苦労している人々もいます。これらの「現地」での、潜在的に偏った観察は、自分のネットワークを超えた調査によって検証することができ、より広範な市場での解決策が存在することを確認することができます。
現実世界は少し曖昧であり、顧客が新しく、明確に定義された機会を持ってきてくれるわけではありません。むしろ、あなたのアンテナを伸ばしていれば、機会はさまざまな方向からあなたに届くでしょう。以下のような方向から機会が届くことがあります:
- 市場の位置づけ:AIはトレンドです。既存のビジネスにおいては、革新的でハイテク、将来に向けたイメージを強化するために利用されることがあります。例えば、既存のマーケティングエージェンシーをAIパワードのサービスに昇華させ、競合他社との差別化を図ることができます。ただし、AIのためだけにAIを行うことは避けるべきです。位置づけのトリックは注意して、他の機会と組み合わせて適用する必要があります。さもないと、信用を失う可能性があります。
- 競合他社:競合他社が動き出すと、彼らはすでに基礎となる研究と検証を行っている可能性があります。しばらくの間、彼らを見てみてください。彼らの開発は成功しましたか?この情報を使用して、自分自身のソリューションを最適化し、成功した部分を取り入れ、ミスを修正することができます。例えば、完全に自動化されたマーケティングコンテンツの生成サービスを提供している競合他社を観察しているとします。ユーザーは「大きな赤いボタン」をクリックし、AIがコンテンツを書いて公開するというプロダクトを利用することをためらっています。調査の結果、ユーザーはプロセスに対してより多くの制御を保ち、自分自身の専門知識や個性を執筆に貢献したいと考えていることがわかりました。結局、執筆も自己表現や個別の創造性に関わるものです。これは、ユーザーの効率を高める一方で、コンテンツを形作るための豊富な機能と設定を提供する万能なツールで前進する時です。ユーザーが望む場合にいつでも自分自身をプロセスに「注入」できるようにします。
- 規制:技術的な破壊やグローバル化などのメガトレンドは、規制当局に要件を厳格化するよう圧力をかけます。規制は機会の弾丸プルーフの源です。例えば、AI生成コンテンツを広告する際には、その旨を明示するよう厳格に規制が導入されるとします。既にAIコンテンツ生成ツールを使用している企業は、これについて内部での議論が行われるでしょう。その中には、AI生成されたテンプレートではなく、本物の思考リーダーシップのイメージを維持したいと考える企業も多いでしょう。例えば、あなたはユーザーがテキストの公式な「著者」として残るために、ユーザーに十分な制御機能を提供する拡張ソリューションを選びました。新しい制約が導入されると、あなたは免疫を持ち、規制を利用して前進し、完全に自動化されたソリューションを持つ競合他社はこの打撃から回復するための時間が必要になります。
- 可能にする技術:新興技術や既存技術の飛躍(例:2022-23年の生成AIの波)によって、新しい取り組み方が生まれたり、既存のアプリケーションが新たなレベルに到達したりすることがあります。例えば、過去10年間にわたって伝統的なマーケティングエージェンシーを運営してきたとします。今、AIのハックやソリューションをビジネスに導入して、従業員の効率を向上させ、既存のリソースでより多くのクライアントにサービスを提供し、利益を増やすことができます。既存の専門知識、評判、および(望ましいことを願って)顧客ベースを活用するため、新規参入者に比べてAIの改善を導入するリスクははるかにスムーズで少ないかもしれません。
最後に、現代の製品の世界では、機会はしばしば明示的で形式的ではなく、実験で直接検証できるため、開発がスピードアップします。したがって、プロダクト主導の成長では、チームメンバーは厳密なデータに基づく議論なしに独自の仮説を提案することができます。これらの仮説は、プロンプトの変更や一部のUX要素のレイアウトの変更など、部分的な形で定式化することができます。これにより、実装、展開、テストが容易になります。新しい提案ごとに事前データを提供する圧力をなくすことで、このアプローチはすべてのチームメンバーの直観と想像力を活用しながら、提案の直接的な検証を強制します。たとえば、コンテンツ生成がスムーズに進んでいるが、AIの透明性と説明可能性の不足に関する苦情がますます増えています。特定の情報源を生成したコンテンツの元に戻るために、追加の透明性レベルを実装し、ユーザーに具体的なドキュメントを表示することに決めます。チームは、ユーザーのグループでこの機能をテストし、ユーザーがそれを使用して満足していることを発見します。したがって、使用率と満足度を向上させるために、これをコア製品に導入することに決定します。
2. 価値
AI製品や機能の価値を理解し伝えるためには、まずそれを具体的なビジネスの問題を解決するユースケースにマッピングし、投資対効果(ROI)を把握する必要があります。これにより、技術から離れてソリューションのユーザーサイドの利点に焦点を当てるように意識を切り替えることができます。ROIは異なる次元で測定することができます。AIの場合、いくつかの次元は以下の通りです。
- 効率の向上:AIは、個人、チーム、企業全体の生産性を向上させるためのブースターとなることがあります。たとえば、コンテンツ生成では、通常ブログ記事を書くのに必要な4~5時間を1~2時間に短縮し、節約した時間を他のタスクに費やすことができるかもしれません。効率の向上は、同じ作業量を実行するために必要な人的な努力が減るため、コストの節約とも相関関係があります。したがって、ビジネスの文脈では、この利点はユーザーとリーダーシップの両方にとって魅力的です。
- よりパーソナライズされた体験:たとえば、コンテンツ生成ツールは、ユーザーに企業のブランド属性、用語、製品の利点などのパラメータの設定を求めることができます。さらに、特定のライターが行った編集を追跡し、そのユーザーの独自の執筆スタイルに合わせて生成物を適応させることができます。
- 楽しさと喜び:ここでは、製品の使用の感情的な側面、ドン・ノーマンによると「感情的」なレベルに入ります。ゲームや拡張現実など、楽しさとエンターテイメントのための製品のカテゴリがB2Cキャンプに存在します。B2Bではどうでしょうか?B2B製品は、無機質なプロフェッショナルな真空中に存在すると思われるかもしれませんが、実際にはこのカテゴリの方がB2Cよりも強い感情的な反応を引き起こすことがあります。たとえば、執筆は満足感のある自己表現の行為として捉えられるか、ライターズブロックや他の問題との内的な闘いとして捉えられるかもしれません。製品がタスクのポジティブな感情を強化し、苦痛の側面を軽減または変容させる方法について考えてみてください。
- 利便性:AIの魔法の力を活用するために、ユーザーは何をする必要がありますか?コンテンツ生成のコパイロットをMS Office、Google Docs、Notionなどの人気のあるコラボレーションツールに統合することを想像してみてください。ユーザーは、自分のデジタルな「ホーム」から出ることなく製品の知能と効率を利用することができます。したがって、製品の価値を体験して使用し続けるためにユーザーが必要とする努力を最小限に抑えることができます。これにより、ユーザーの獲得と採用が促進されます。
効率などのAIの利点の一部は、ROIのために直接数量化することができます。利便性や喜びなどの具体的でない利点については、ユーザー満足度などの代理指標を考える必要があります。エンドユーザーの価値について考えることは、ユーザーと製品の間のギャップを埋めるだけでなく、公共のコミュニケーションにおける技術的な詳細を減らすことにも役立ちます。これにより、意図しない競争を招くことを防ぎます。
最後に、早期に考慮すべき価値の基本的な側面は、持続可能性です。あなたのソリューションが社会と環境にどのような影響を与えるのかを考えてください。例えば、自動化されたまたは拡張されたコンテンツ生成は、大規模な人間の作業量を置き換えたり排除したりすることがあります。あなたはおそらく、ある仕事のカテゴリ全体の殺し屋として知られたくないでしょう。なぜなら、これには倫理的な問題が生じるだけでなく、仕事が脅かされているユーザーからの抵抗も呼び起こすからです。これらの懸念にどのように対処できるか考えてみてください。例えば、ユーザーに新しい自由な時間を効率的に活用する方法について教育することができます。これにより、他の競合他社が自動化されたコンテンツ生成に追いついても、守りの堀を提供することができます。
3. データ
AIや機械学習のいかなる種類においても、実際の入力を反映し、モデルに十分な学習信号を提供するようにデータを収集・準備する必要があります。現在では、データ中心のAIというトレンドが見られます。これは、モデルの無限の微調整や最適化から離れ、これらのモデルに供給されるデータの数多くの問題を修正することに焦点を当てるAIの哲学です。始める際には、優れたデータセットを手に入れるためのさまざまな方法があります:
- 既存のデータセットを使用することができます。これは、標準的な機械学習データセットや、初期の目的とは異なるデータセットを適応させることができるデータセットです。感情分析のためのIMDB映画レビューデータセットや、手書き文字認識のためのMNISTデータセットなど、いくつかのクラシックなデータセットがあります。Catching Illegal FishingやDog Breed Identificationなどのよりエキゾチックで刺激的な代替案や、Kaggleなどのデータハブにある無数のユーザーがキュレーションしたデータセットなど、さまざまな選択肢があります。特定のタスクに特化したデータセットを見つけて要件を完全に満たすという可能性は非常に低く、ほとんどの場合、データを豊かにするために他の手法も使用する必要があります。
- データのアノテーションや手動での作成を行うことで、適切な学習信号を作り出すことができます。テキストの感情スコアなどのアノテーションは、機械学習の初期の時代における主要な手法でした。最近では、ChatGPTの秘密のソースとして、人間の好みを反映したモデルの応答の作成とランキングに膨大な手作業が注がれています。この技術は、人間のフィードバックからの強化学習(RLHF)とも呼ばれます。必要なリソースがある場合、マーケティングコンテンツの生成など、より具体的なタスクのために高品質なデータを作成することができます。アノテーションは、内部で行うことも、Amazon Mechanical Turkのような外部のプロバイダーやクラウドソーシングサービスを使用することもできます。いずれにしても、多くの企業はRLHFデータを手動で作成するために必要な莫大なリソースを費やしたくないと考え、データの自動生成にはいくつかのトリックを考えることになるでしょう。
- したがって、データ拡張を使用して既存のデータセットにさらに例を追加することができます。感情分析などのより簡単なタスクでは、テキストにいくつかの追加ノイズを導入したり、いくつかの単語を入れ替えたりすることができます。よりオープンな生成タスクの場合、大規模なモデル(例:基盤モデル)を使用して自動的にトレーニングデータを生成することに関しては現在非常に熱心です。最適なデータ拡張方法を特定したら、必要なデータセットのサイズにスケールさせることが容易になります。
データを作成する際には、品質と量のトレードオフがあります。高品質なデータを少なく手動でアノテーションするか、予算を使って自動データ拡張のためのハックやトリックを開発して追加のノイズを導入するかを選ぶことができます。手動のアノテーションを選択する場合、内部で行うこともでき、詳細さと品質の文化を形成することもできます。また、Amazon Mechanical Turkのような外部プロバイダーやクラウドソーシングサービスに作業をアウトソースすることもできます。クラウドソーシングは通常品質が低いため、ノイズを補償するためにより多くのアノテーションが必要になるかもしれません。最適なバランスを見つける方法はありません。最終的には、トレーニングとデータの強化の間での継続的な試行錯誤を通じて、理想的なデータの構成を見つけることになります。一般的に、モデルを事前トレーニングする場合は、大量のデータが必要です。一方、既存の大規模モデルに最後の仕上げと専門性を与えたい場合は、品質を量よりも重視するかもしれません。詳細なガイドラインを使用して小規模なデータセットを制御的に手動でアノテーションすることが、この場合の最適な解決策となるでしょう。
4. アルゴリズム
データはモデルが学習するための生の素材であり、代表的で高品質なデータセットを編成することができることを望みます。さて、AIシステムの実際の超能力である既存のデータから学習し、新しいデータに一般化する能力はアルゴリズムにあります。AIモデルのコアとなるオプションとして、主に次の3つの選択肢があります:
- 既存のモデルにプロンプトすることができます。ChatGPTやGPT-4などのGPTファミリーの高度なLLM(大規模言語モデル)やAnthropic、AI21 Labsなど他のプロバイダーからのものは、APIを介して推論に使用することができます。プロンプトを使用することで、特定のドメインやタスクに必要な特定のコンテンツ、類似のタスクの例(few-shot prompting)やモデルに従うための指示などをプロンプトに含めることができます。たとえば、ユーザーが新しい製品の機能についてのブログ記事を生成したい場合、その機能に関するいくつかのコア情報(利点や使用方法、リリース日など)を提供するようにお願いすることができます。その情報を注意深く作成されたプロンプトテンプレートに埋め込み、LLMにテキストを生成してもらいます。プロンプトは、事前トレーニング済みモデルにスムーズに入り込むための素晴らしい手段です。ただし、プロンプトによって構築できる壁は時間の経過とともに薄くなる可能性があります。中期的には、競争上の優位性を維持するためにより堅牢なモデル戦略が必要です。
- 事前トレーニング済みモデルを微調整するアプローチは、過去数年間にAIを非常に人気のあるものにしました。Huggingfaceなどのポータルがモデルリポジトリやモデルとの作業のための標準的なコードを提供するなど、ますます多くの事前トレーニング済みモデルが利用可能に
トレーニングを超えて、評価は機械学習を成功させるためには非常に重要です。適切な評価指標と方法は、AI機能の自信を持った導入だけでなく、さらなる最適化のための明確な目標と、内部の議論と意思決定の共通の基盤としても機能します。精度、再現率、正解率などの技術的な指標は、良い出発点を提供するかもしれませんが、最終的には、AIがユーザーに提供する現実の価値を反映する指標を探すことが望ましいでしょう。
5. ユーザーエクスペリエンス
AI製品のユーザーエクスペリエンスは魅力的なテーマです。なぜなら、ユーザーは「パートナー」となるAIとの協力に高い期待と同時に不安を抱いているからです。この人間とAIのパートナーシップの設計には、慎重で理にかなった発見と設計プロセスが必要です。重要な考慮事項の1つは、製品にどの程度の自動化を許可するかということです。なお、全自動化が常に理想的な解決策であるわけではありません。以下の図は、自動化の連続体を示しています:

各レベルを見てみましょう:
- 最初の段階では、人間がすべての作業を行い、自動化は行われません。AIに関するハイプにもかかわらず、現代の企業におけるほとんどの知識集約型のタスクはまだこのレベルで実施されており、自動化のための巨大な機会を提供しています。たとえば、AI駆動のツールに抵抗し、執筆が高度にマニュアルで個別の技術だと主張するコンテンツライターはここで働いています。
- 第2の段階では、ユーザーはタスクの実行に完全な制御を持ち、作業の大部分を手動で行いますが、AIツールは時間を節約し、ユーザーの弱点を補うのに役立ちます。たとえば、締め切りの迫ったブログ投稿を執筆する際に、Grammarlyや類似のツールを使用して最終的な言語チェックを行うことは、歓迎される時間節約になります。これにより、手動の修正作業がなくなり、貴重な時間と注意を必要とする手動の修正作業によるエラーや見落としもなくなります。
- 拡張された知能では、AIは人間の知能を増強するパートナーです。したがって、両者の強みを活かします。アシストされたAIと比較して、機械はプロセスにおいてさらに多くを発言し、発案、起草物の生成と編集、および最終的な言語チェックなど、より広範な責任を担当します。ユーザーは仕事に参加し、意思決定を行い、タスクの一部を実行する必要があります。ユーザーインターフェースは、人間とAIの作業分担を明確に示し、エラーポテンシャルを強調し、実行される手順に透明性を提供する必要があります。要するに、「拡張された」エクスペリエンスは、反復と改善を通じてユーザーを目標の成果に導きます。
- 最後に、完全自動化があります。これはAIの専門家、哲学者、評論家にとって魅力的なアイデアですが、現実の製品においては常に最適な選択肢ではありません。完全自動化とは、プロセスを開始するための「大きな赤いボタン」を提供することを意味します。AIが完了すると、ユーザーは最終的な出力に直面し、それを受け入れるかどうかを決定します。それ以前に何が起こったかは、ユーザーが制御することはできません。想像できるように、ここではUXのオプションは非常に限られています。ほとんどの成功の責任は、技術の同僚たちの肩にかかっています。彼らは出力の非常に高い品質を保証する必要があります。
AI製品は設計に特別なアプローチが必要です。標準的なグラフィカルインターフェースは決定論的であり、ユーザーが取る可能性のあるすべての経路を予測することができます。対照的に、大規模なAIモデルは確率的で不確定性があります。これらは驚くべき能力を提供する一方で、有害な出力、間違った出力、有害な出力などのリスクももたらします。外部から見ると、あなたのAIインターフェースはシンプルに見えるかもしれませんが、製品の大部分はモデルそのものに直接含まれています。たとえば、LLMはプロンプトを解釈し、テキストを生成し、情報を検索し、要約し、特定のスタイルと専門用語を採用し、指示を実行するなどの能力を持っています。シンプルなチャットやプロンプトのインターフェースであっても、この潜在能力を見逃さないようにしましょう。ユーザーを成功に導くためには、明確で現実的な情報を提供する必要があります。ユーザーにAIモデルの能力と制約を認識させ、AIによる誤りを簡単に発見して修正することができるようにし、自分自身で最適な出力に進化する方法を教える必要があります。信頼性、透明性、ユーザー教育を重視することで、ユーザーがAIと共同作業できるようにすることができます。AIデザインの新興分野に深く入り込むことは、この記事の範囲外ですが、他のAI企業だけでなく、人間と機械のインタラクションなどのデザインの他の領域からもインスピレーションを探すことを強くお勧めします。自動補完、プロンプトの提案、AIの通知などのデザインパターンの範囲を特定し、データとモデルを最大限に活用するために独自のインターフェースに統合することができます。
さらに、本当に素晴らしいデザインを提供するためには、チームに新しいデザインスキルを追加する必要があるかもしれません。たとえば、マーケティングコンテンツの洗練のためのチャットアプリケーションを構築している場合、会話デザイナーと協力して、会話のフローとチャットボットの「個性」に注意を払います。利用可能なオプションを通じてユーザーを徹底的に教育しガイドする必要がある豊かな拡張製品を構築している場合、コンテンツデザイナーは適切な情報アーキテクチャを構築し、ユーザーに適切な量の促進とプロンプトを追加するのに役立ちます。
そして最後に、驚きに対してオープンになってください。AIデザインは、ユーザーエクスペリエンスに関する元々の概念を見直すことができます。たとえば、多くのUXデザイナーやプロダクトマネージャーは、ユーザーエクスペリエンスをスムーズにするためにレイテンシと摩擦を最小限に抑えることを徹底的に訓練されてきました。AI製品では、この戦いを一時停止して両方を利用することができます。レイテンシと待ち時間は、ユーザーを教育するのに最適です。たとえば、AIが現在何をしているのかを説明し、ユーザー側の可能な次のステップを示すことで、ユーザーに対して透明性と制御を高めることができます。対話や通知のポップアップなどの休憩は、ユーザーとAIのパートナーシップを強化し、ユーザーに対して透明性と制御を高めるための摩擦を導入することができます。
6. 非機能要件
データ、アルゴリズム、およびユーザーエクスペリエンスを通じて特定の機能を実装するために必要なものを超えて、正確性、レイテンシ、スケーラビリティ、信頼性、データガバナンスなどの非機能要件(NFR)が、ユーザーが望んでいる価値を実際に得られるようにします。 NFRの概念はソフトウェア開発から来ていますが、AIの領域ではまだ体系的に考慮されていません。これらの要件は、ユーザー調査、発想法、開発、およびAI機能の運用中に発生すると、アドホックに取り上げられることがよくあります。
早い段階でNFRを理解し定義するように努めるべきです。なぜなら、異なるNFRが旅程の異なるポイントで実現されるからです。たとえば、プライバシーはデータ選択の非常に初期の段階から考慮する必要があります。正確性は、ユーザーがオンラインでシステムを使用し、予期しない入力でシステムを圧倒する可能性がある製品の製造段階で最も敏感です。スケーラビリティは、ビジネスがユーザーや要求の数、または提供される機能の範囲を拡大すると戦略的な考慮事項となります。
NFRに関しては、すべてを持つことはできません。以下は、バランスを取る必要がある典型的なトレードオフのいくつかです:
- 正確性を向上させる最初の方法の1つは、より大きなモデルを使用することですが、これはレイテンシに影響を与えます。
- さらなる最適化のためにプロダクションデータをそのまま使用することは、学習にとって最適ですが、プライバシーと匿名化のルールに違反する可能性があります。
- スケーラビリティが高いモデルは一般的なものであり、会社やユーザー固有のタスクにおける正確性に影響を与えます。
異なる要件の優先順位付けは、利用可能な計算リソース、自動化の度合いを含むUXコンセプト、およびAIによってサポートされる意思決定の影響によって異なります。
キーポイント
- 目標を持って始める:技術だけでは仕事をすることはできないと思わないでください。ユーザー向け製品にAIを統合し、その利点、リスク、制約についてユーザーに教育するための明確なロードマップが必要です。
- 市場の調整:AIの開発をガイドするために市場の機会と顧客のニーズを優先しましょう。ハイプに駆られずに市場の検証なしでAIの導入を急がないでください。
- ユーザー価値:効率性、個別化、便利さなどの価値の次元でAI製品の価値を定義し、量化し、伝えましょう。
- データの品質:効果的にAIモデルをトレーニングするためにデータの品質と関連性に焦点を当てましょう。微調整には小さな高品質のデータを使用し、ゼロからトレーニングするためにはより大きなデータセットを使用してみてください。
- アルゴリズム/モデルの選択:使用ケースに応じた適切なレベル(プロンプト、微調整、ゼロからトレーニング)を選択し、そのパフォーマンスを慎重に評価しましょう。必要な専門知識と製品への自信を獲得するにつれて、より高度なモデル戦略に切り替えたくなるかもしれません。
- ユーザーセントリックなデザイン:ユーザーのニーズと感情を考慮したAI製品を設計し、自動化とユーザーコントロールをバランスさせましょう。確率的なAIモデルの「予測できなさ」に注意し、ユーザーがそれと協力し、それから利益を得るようにガイドしましょう。
- 協力的なデザイン:信頼性、透明性、ユーザー教育を重視することで、ユーザーがAIと協力することができるようにしましょう。
- 非機能要件:正確性、レイテンシ、スケーラビリティ、信頼性などの要素を開発全体で考慮し、早期にこれらのトレードオフを評価しましょう。
- 協力:AIの専門家、デザイナー、プロダクトマネージャー、および他のチームメンバーとの緊密な協力を促進し、異分野の知識を活用し、AIを成功裏に統合しましょう。
参考文献
[1] Teresa Torres(2021)。継続的なディスカバリーの習慣:顧客価値とビジネス価値を創出する製品を発見する。
[2] Orbit Media(2022)。新しいブログ統計:2022年にどのようなコンテンツ戦略が機能するか?1016人のブロガーに聞きました。
[3] Don Norman(2013)。日常のモノのデザイン。
[4] Google、Gartner、Motista(2013)。プロモーションから感情へ:B2Bの顧客をブランドにつなげる。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- DSPyの内部:知っておく必要のある新しい言語モデルプログラミングフレームワーク
- 「WavJourney:オーディオストーリーライン生成の世界への旅」
- 「ChatGPTをより優れたソフトウェア開発者にする:SoTaNaはソフトウェア開発のためのオープンソースAIアシスタントです」
- 「第一の汎用ビジュアルと言語のAI LLaVA」
- 機械学習なしで最初の自動修正を作成する
- 効率的なディープラーニング:モデルの圧縮のパワーを解き放つ
- このAI論文では、Complexity-Impacted Reasoning Score(CIRS)を紹介していますこれは、大規模な言語モデルの推論能力を向上させるためのコードの複雑さの役割を評価するものです






