「非構造化データ内のデータスライスの検出」 翻訳結果は以下の通りです: 「非構造化データ内でデータスライスを見つける」
Detecting data slices in unstructured data
CIFAR-100データセットを用いたデータスライシング手法の短い紹介と実践例について
要約:
データスライスとは、モデルが異常な動作をするデータの意味的に有意な部分集合のことです。非構造化データの問題(例:画像、テキスト)に取り組む際、これらのスライスを見つけることは、データサイエンティストの重要な仕事の一部です。実際には、このタスクには個別の経験と手作業がたくさん必要です。この記事では、データスライスをより体系的かつ効率的に見つけるためのいくつかの手法とツールを紹介します。現在の課題についても議論し、オープンソースのツールを使用した実践的なワークフローのいくつかを示します。
CIFAR100データセットを使用したインタラクティブなデモが利用可能です。
はじめに
人工知能(AI)システムのデバッグ、テスト、モニタリングは困難です。ソフトウェア2.0の開発プロセスでは、高品質なデータセットの作成に多くの労力が費やされます。
頑健な機械学習(ML)アルゴリズムを開発するための重要な戦略の1つは、データスライスと呼ばれるものを特定することです。データスライスとは、モデルが異常な動作をする意味的に有意な部分集合のことです。これらのデータセグメントを特定し、追跡することは、データ中心のAI開発プロセスの核心です。また、医療や自動運転支援システムなどの安全なAIソリューションの展開においても、重要な要素です。
従来、データスライスの特定は、データサイエンティストの仕事の一部でした。実際には、データスライスの特定は、データサイエンティストの個別の経験とドメイン知識に強く依存しています。データ中心のAIムーブメントの中で、このプロセスをより体系的にするための現在の研究とツールがたくさんあります。
本記事では、非構造化データ上でのデータスライスの現状について概説します。特に、オープンソースのツールを使用した実践的なワークフローのいくつかを示します。
スライス探索とは何ですか?
データサイエンティストは常に単純な手動スライス探索技術を使用しています。もっとも有名な例は、分類問題のデバッグ手法である混同行列です。実際には、スライス探索プロセスは、事前計算されたヒューリスティックス、データサイエンティストの個別の経験、そして多くのインタラクティブなデータ探索の組み合わせに依存しています。
クラシカルなデータスライスは、表形式のフィーチャーやメタデータの述語の論理積によって記述することができます。人々のデータセットでは、例えば特定の年齢範囲の男性で身長が1.85m以上の人々です。エンジンの状態監視データセットでは、特定のRPM、運転時間、トルク範囲のデータポイントからなるスライスになるかもしれません。
非構造化データの場合、意味的なデータスライスの定義はより暗黙的なものになる場合があります。これは、「山岳地帯での混雑した交通のある曲がりくねった道路での軽い雨の中での運転シナリオ」といった、人間が理解できる記述形式のことです。
非構造化データセット上のデータスライスの特定は、次の2つの異なる方法で行うことができます:
- メタデータは、非構造化データから古典的な信号処理アルゴリズム(例:暗い画像、低SNRオーディオ)または事前学習済みの深層ニューラルネットワークによって抽出されることがあります。その後、このメタデータ上でスライス探索を行うことができます。
- 埋め込み空間の潜在表現を使用してデータクラスタをグループ化することができます。これらのクラスタを検査して関連するデータスライスを特定することができます。
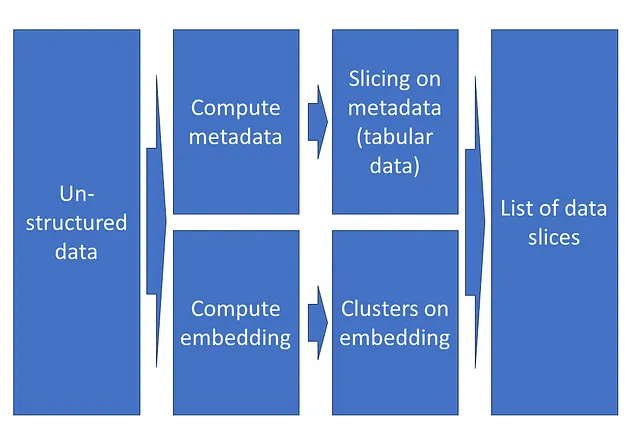
自動的なスライス探索技術は、スライスのサポート(大きいほど良い)とモデルのパフォーマンスの異常度(大きいほど良い)をバランスさせることを常に目指しています。
表形式のデータ上のスライス探索手法は、意思決定木と多くの類似点を共有しています:MLモデルの解析の文脈では、両方の手法を使用して、モデルのエラーが存在する場所を記述するルールを形成することができます。ただし、1つ重要な違いがあります:スライス探索問題では、重なり合うスライスが許容されます。これにより、検索空間の剪定がより困難になり、計算的に難しい問題になります。
データスライスの検出はなぜ重要なのですか?
特に最近の10年間、機械学習コミュニティはベンチマークデータセットから大いに恩恵を受けてきました。ImageNetを始めとするこのようなデータセットと競技は、非構造化データの問題におけるディープラーニングアルゴリズムの大きな成功要因となっています。この文脈において、新しいアルゴリズムの品質は、F1スコアや平均適合率などの数少ない定量的指標に基づいて通常評価されます。
本番環境に展開されるMLモデルがますます増えるにつれ、実世界のデータセットはベンチマークとは大きく異なることが明らかになってきました。実データは通常非常にノイズが多く、バランスが取れていませんが、同時にメタデータ情報も豊富です。一部のユースケースでは、これらのデータセットのクリーニングや注釈付けは非常に高額になる場合があります。
多くのチームは、トレーニングデータセットの反復と本番環境でのドリフトの監視がAIシステムの安全な構築と維持には必要であることを発見しました。
データスライスの検出はこの反復プロセスの核心です。モデルの失敗箇所を知ることで、システムのパフォーマンスを改善することが可能になります。これには、より多くのデータの収集、誤ったラベルの修正、最適な特徴の選択、またはシステムの操作ドメインの制約などが含まれます。
なぜデータスライスの検出は非常に困難なのですか?
スライスの検出には計算量の複雑さが重要な要素です。以下の小さな例を使って説明します。n個のバイナリ特徴量を持つ場合、ワンホットエンコーディング(例えばビニングや再コーディングによって得られる)を考えます。その場合、すべての可能な特徴組み合わせの検索空間はO(2^n)です。この指数的な性質から、通常は剪定のためにヒューリスティックが使用されます。そのため、自動的なスライスの検出にはかなりの時間がかかるだけでなく、出力は最適な安定した解ではなく、いくつかのヒューリスティックになります。
AIの開発プロセスでは、モデルのパフォーマンスの低下はしばしば異なる根本的原因に起因します。MLモデルの固有の確率的性質を考慮すると、容易に偽の発見につながり、手動で検査および検証する必要があります。したがって、スライスの検出技術が理論的に最適な結果を出すことができたとしても、その結果は手動で検査および検証される必要があります。クロスファンクショナルなチームがこれを効率的に行うためのツールの開発は、多くのMLチームにとってボトルネックとなっています。
すでに述べたように、一般的にはサポートが大きく、かつデータセットのベースラインとのモデルパフォーマンスに明確なギャップがあるスライスを見つけることが望ましいです。さまざまなデータスライス間の関係は、階層的な性質を持つことが多いです。これらの階層を自動的なスライスの検出プロセスおよび対話型のレビューフェーズで処理することは非常に困難です。
自動的なスライスの検出手法は、メタデータが豊富な問題に最も効果的です。これは実世界の問題によく当てはまります。対照的に、ベンチマークデータセットは常にメタデータが非常に少ないです。これには、データ保護と匿名化の要件があるためです。適切な例のデータセットがないため、効果的なスライスの検出ワークフローの開発とデモンストレーションは非常に困難です。
このような課題については、以下の例のセクションで対処する必要があります(残念ながら)。
ハンズオン:CIFAR-100でのデータスライスの検出
CIFAR-100データセットは確立されたコンピュータビジョンのベンチマークです。データセットのサイズが小さいため、取り扱いや計算要件が低いという点で、このチュートリアルで使用します。結果も特別なドメイン知識を必要としないため、理解しやすいです。
残念ながら、CIFAR-100は既に完全にバランスが取れており、高度にキュレーションされており、意味のあるメタデータが欠けています。このセクションで生成されるスライス検出ワークフローの結果は、実世界の設定とは意味が異なるため、あまり意味がありません。ただし、提示されるワークフローは、実際のデータにそれらを素早く適用する方法を理解するのに十分です。
準備の段階では、Cleanvisionライブラリを使用して画像メタデータを計算します。この豊かな情報についての詳細は、我々のデータ中心のAIプレイブックに記載されています。
また、データスライスの分析に重要な変数をいくつか定義します。分析する特徴量、ラベルおよび予測列の名前などです。
ほとんどのスライス手法は、ビニングされた特徴量でのみ機能します。SliceLineとWisePizzaライブラリ自体にはビニング機能がないため、前処理としてこれを実行します。
SliceLine
Slicelineアルゴリズムは、Sagadeevaらによって2021年に提案されました。多くの特徴を持つ大規模な表形式のデータセットで使用することを意図しています。このアルゴリズムは、疎行列の代数的テクニックに基づく新しい剪定技術を活用し、単一のマシン上でも迅速にデータスライスを見つけることができます。
このチュートリアルでは、DataDomeチームのSliceLine実装を使用します。非常に安定して実行されますが、現在のところPythonバージョン3.9以下のみをサポートしています。
スライスラインアルゴリズムのほとんどのパラメータは非常に直感的です。スライスの最小サポート(min_sup)、スライスを定義するための述語の最大数(max_l)、返されるスライスの最大数(k)です。パラメータalphaはスライスエラーの重要性に重みを割り当て、スライスのサイズとエラーの減少のトレードオフを制御します。
私たちはSliceLineライブラリを呼び出して、最も興味深い20のスライスを取得します。
スライスを対話的に探索するために、各データスライスの説明を豊かにします。
私たちは、Spotlightを開始して、データスライスを対話的に探索します。Huggingfaceの空間で直接結果を体験することができます。
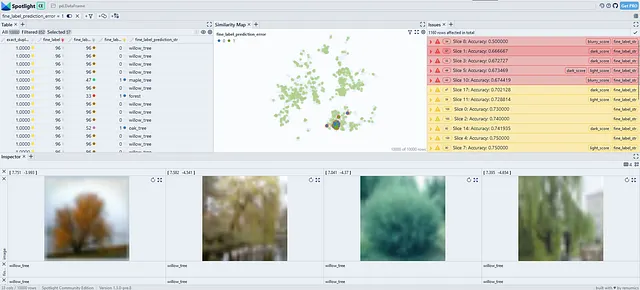
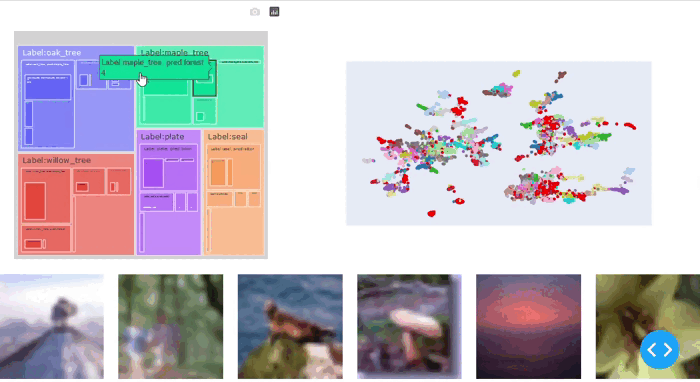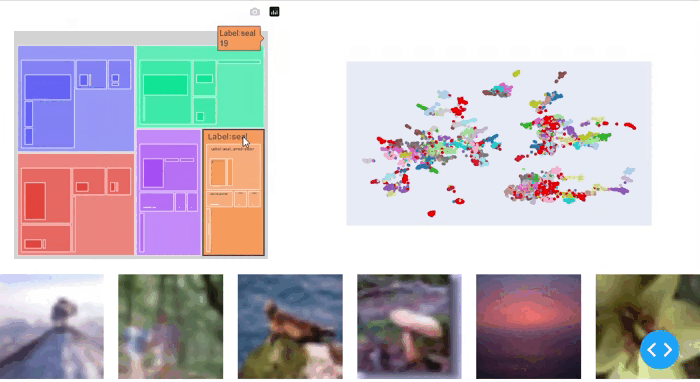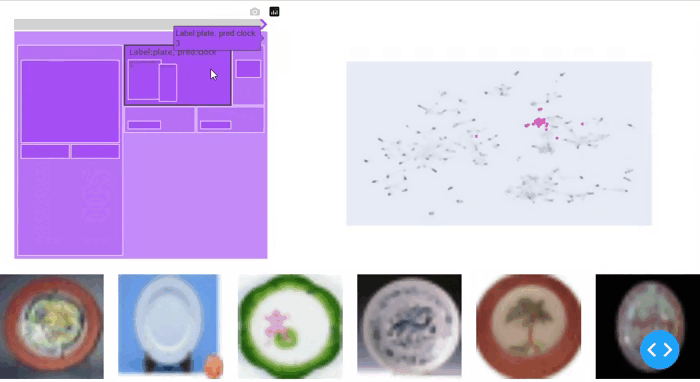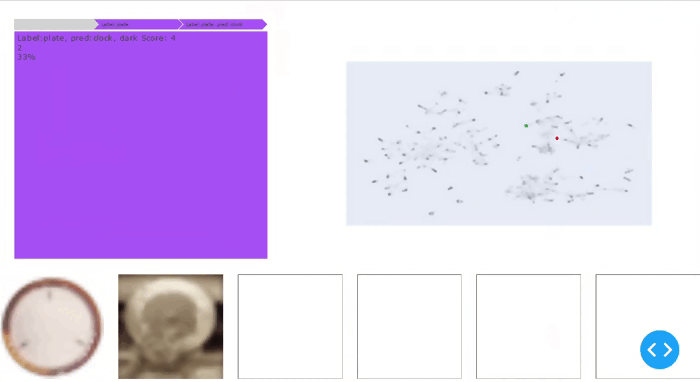
私たちは、SliceLineアルゴリズムがCIFAR-100データセットで意味のあるデータスライスをいくつか見つけたことがわかります。メープルの木、ヤナギの木、オークの木のクラスが問題のあるようです。また、高いダークスコアを持つこれらのクラスのデータポイントは特に難しいとわかります。より詳細に調査すると、これは明るい背景を持つ木々がモデルにとって難しいためです。
Wise Pizza
WisePizzaは、Wiseチームによる最近の開発です。それは表形式のデータで興味深いデータスライスを見つけて視覚化することを目的としています。そのコアアイデアは、各スライスの重要度係数を見つけるためにLasso回帰を使用することです。Wise Pizzaの動作方法の詳細については、ブログ記事をご覧ください。
WisePizzaはMLデバッグツールとして開発されたわけではないことに注意することが重要です。代わりに、主にEDA中のセグメント分析のサポートを目的としています。そのため、セグメント候補を手動で定義し、それに重みを割り当てることが可能です。私たちの実験では、WisePizzaをデータセットに直接適用し、各データポイントの重みを1に設定しました:
非構造化データセットの問題を探索するために、Slicelineの例と同じ方法で問題を抽出します。
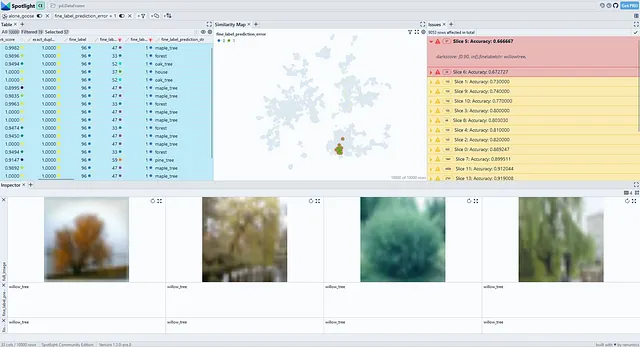
図4からわかるように、シンプルなCIFAR-100ベンチマークデータセットでは、WisePizzaは関連するセグメントを見つけます:それはまた、高いダークスコアを持つヤナギの木クラスをトップのスライスとしてリストします。ただし、以下の結果は異なるクラスカテゴリに限定されており、SliceLineの出力ほど細粒度ではありません。その理由の1つは、WisePizzaアルゴリズムがスライスのサポートと精度の低下の間の重み付けメカニズムを直接提供しないためです。
Sliceguard
Sliceguardライブラリは階層的クラスタリングを使用してデータスライスを特定します。その後、フェアラーニングの方法を使用してこれらのクラスタをランク付けし、説明可能なAI技術を介して述語を探索します。Sliceguardに関する詳細情報については、このブログ記事をご覧ください。
Sliceguardを構築した主な理由は、それが表形式のデータだけでなく、埋め込みデータに直接適用できることです。このライブラリは、前処理(例:ビニング)や後処理のための多くの組み込み機能を提供しています。
わずか数行のコードでCIFAR-100上でSliceguardを実行することができます:
Sliceguardは、特定されたデータスライスを対話的に視覚化するためにSpotlightを使用します:
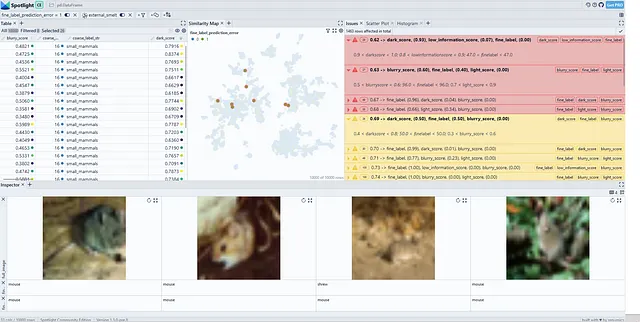
issue_df、issues = sg.report(spotlight_dtype = {"image":Image})SliceguardはCIFAR-100データセットで細かいデータスライスを明らかにすることができます(図5)。木のカテゴリで以前に発見されたデータスライスに加えて、マウスのクラスなどの他の問題も特定します。
結論
私たちはデータスライスをマイニングするための3つのオープンソースツールを紹介しました。単純なCIFAR-100ベンチマークでも、これらのツールを使用することで重要なデータセグメントを迅速に明らかにすることができます。これらのデータスライスを特定することは、モデルの故障モードを理解し、トレーニングデータセットを改善するための重要なステップです。
SliceLineツールは表形式のデータで機能し、述語の組み合わせで説明されるデータスライスを特定します。Sliceguardは数学的に最適な述語の組み合わせを返さないものの、埋め込み表現と直接的に動作することができます。さらに、わずか数行のコードで非構造化データセット上で実行することができます。
実際には、SliceLineとSliceguardの両方がデータスライスを特定するのに非常に役立ちます。ただし、これらのツールは完全に自動化されたスライス解析には使用できません。代わりに、インタラクティブな探索と組み合わせることができる強力なヒューリスティックスを提供します。正しく行われれば、このアプローチは信頼性のあるMLシステムを構築するための重要なツールです。
あなたはこれらのデータスライシングツールの使用経験がありますか、または他のオープンソースライブラリをお勧めできますか?コメントでのご意見をお聞かせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AIはほとんどのパスワードを1分以内に解読できますAI攻撃からパスワードを保護する方法」
- 「ヘイスタックの中の針を見つける – Jaccard類似度のための検索インデックス」 翻訳結果は以下の通りです: 「ヘイスタックの中の針を見つける – Jaccard類似度のための検索インデックス」
- 「プラットプス:データセットのキュレーションとアダプターによる大規模言語モデルの向上」
- 「大規模な言語モデルとベクトルデータベースを使用してビデオ推薦システムを構築した方法」
- 「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
- 「正しい方法で新しいデータサイエンスのスキルを学ぶ」
- 「機械学習モデルが医学的診断と治療において不公平を増幅する方法」
