「UniDetectorであなたが望むものを検出しましょう」
Detect what you desire with UniDetector.


深層学習とAIは、特に検出モデルにおいて、近年驚異的な進歩を遂げてきました。しかし、これらの素晴らしい進展にもかかわらず、物体検出モデルの効果は大規模なベンチマークデータセットに大きく依存しています。しかし、課題は物体のカテゴリやシーンの変動にあります。実世界では、既存の画像とは大きな違いがあり、新しい物体クラスが現れる可能性があり、物体検出器の成功を保証するためにデータセットの再構築が必要です。残念ながら、これは彼らのオープンワールドシナリオでの一般化能力に重大な影響を与えます。これに対して、人間、特に子供でさえも、新しい環境に素早く適応し、よく一般化する能力を持っています。その結果、AIシステムと人間の知能の間には普遍性の欠如が残っています。
この制限を克服する鍵は、あらゆる種類の物体を任意のシーンで検出するための普遍的な物体検出器の開発です。このようなモデルは、追加の再トレーニングを必要とせずに未知の状況で効果的に機能する驚異的な能力を持っているでしょう。このような突破口は、物体検出システムを人間と同等に知能を持つものにする目標に大きく近づくでしょう。
普遍的な物体検出器は、2つの重要な能力を持つ必要があります。まず第一に、さまざまな情報源と異なるラベル空間からの画像を使用してトレーニングする必要があります。分類と位置検出のための大規模な共同トレーニングは、検出器が効果的に一般化するための十分な情報を獲得するために重要です。理想的な大規模学習データセットは、多くの画像タイプを含み、可能な限り多くのカテゴリを網羅し、高品質のバウンディングボックス注釈と広範なカテゴリの語彙を備えている必要があります。残念ながら、このような多様性を実現することは、人間の注釈者による制約のために困難です。実際には、小規模な語彙のデータセットはよりきれいな注釈を提供しますが、大規模なデータセットはノイズが多く、不整合が生じる可能性があります。さらに、専門のデータセットは特定のカテゴリに焦点を当てています。普遍性を達成するためには、検出器は異なるラベル空間を持つ複数の情報源から学ぶ必要があり、包括的で完全な知識を獲得します。
- 「QLORAとは:効率的なファインチューニング手法で、メモリ使用量を削減し、単一の48GB GPUで65Bパラメーターモデルをファインチューニングできるだけでなく、完全な16ビットのファインチューニングタスクのパフォーマンスも保持します」
- 「LLMは強化学習を上回る- SPRINGと出会う LLM向けの革新的なプロンプティングフレームワークで、コンテキスト内での思考計画と推論を可能にするために設計されました」
- 「DeepMind AIが数百万の動画のために自動生成された説明を作成することで、YouTube Shortsの露出を大幅に向上させる」

第二に、検出器はオープンワールドにおいて堅牢な一般化能力を示さなければなりません。トレーニング中に見たことのない新しいクラスのカテゴリタグを正確に予測する能力を持っている必要がありますが、視覚情報だけに頼ることはこの目的を達成することができません。包括的な視覚学習には完全に教師あり学習のための人間の注釈が必要です。
これらの制限を克服するために、新しい普遍的な物体検出モデル「UniDetector」が提案されました。
アーキテクチャの概要は、以下のイラストに示されています。
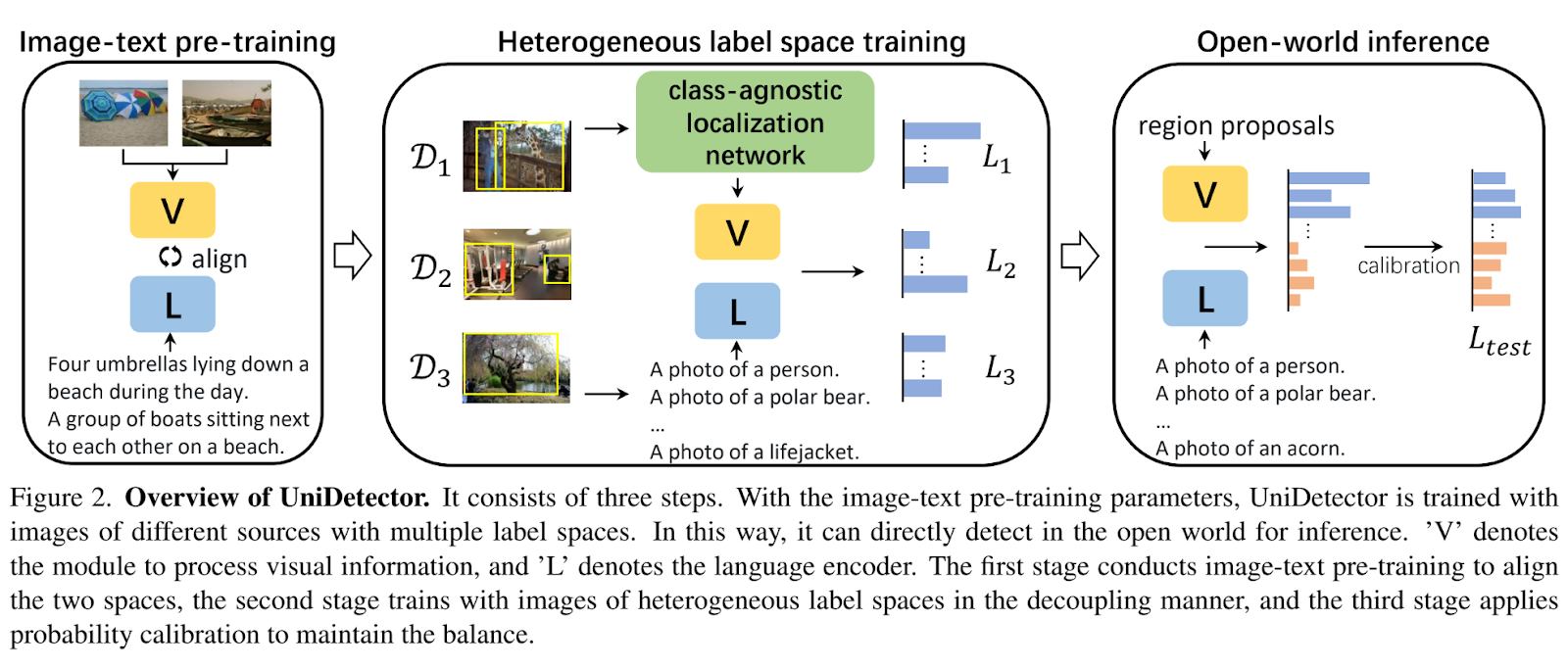
普遍的な物体検出器の2つの重要な能力を実現するためには、2つの対応する課題に取り組む必要があります。第一の課題は、複数の情報源からのトレーニングであり、画像が異なる情報源から来ており、異なるラベル空間と関連付けられています。既存の検出器は、1つのラベル空間からのクラスの予測に限定されており、データセット固有のタクソノミーの違いやデータセット間の注釈の不整合が、複数の異質なラベル空間を統一することを困難にしています。
第二の課題は、新しいカテゴリの識別です。最近の研究における画像テキストの事前トレーニングの成功に触発されて、著者は言語埋め込みを使用して未知のカテゴリを認識するために事前トレーニングされたモデルを活用しています。しかし、完全教師ありトレーニングは、トレーニング中に存在するカテゴリに焦点を当てる傾向があります。その結果、モデルは推論時に基本クラスに偏り、新しいクラスに対しては自信を持たない予測を行う可能性があります。言語埋め込みは新しいクラスを予測する可能性を提供しますが、その性能はまだ基本カテゴリのそれに大きく劣っています。
UniDetectorは、上記の課題に取り組むために設計されています。著者らは言語空間を活用し、異なるラベル空間で効果的に検出器をトレーニングするためにさまざまな構造を探索しています。彼らは、パーティション化された構造を採用することで、特徴の共有を促進し、ラベルの競合を回避することが、検出器のパフォーマンスに有益であることを発見しました。
新しいクラスに対する領域提案段階の一般化能力を向上させるために、著者らは、提案生成段階をRoI(Region of Interest)の分類段階から切り離し、共同トレーニングではなく個別のトレーニングを選択しました。このアプローチは、各段階の固有の特性を活用し、検出器の全体的な普遍性に貢献します。さらに、彼らはクラスに依存しない位置検出ネットワーク(CLN)を導入して一般化された領域提案を実現しました。
さらに、著者らは予測のバイアスを除去するための確率の補正技術を提案しています。彼らはすべてのカテゴリの事前確率を推定し、その事前確率に基づいて予測されたカテゴリの分布を調整します。この補正により、物体検出システム内の新しいクラスのパフォーマンスが大幅に改善されます。著者によれば、UniDetectorは最先端のCNN検出器であるDyheadを6.3% AP(平均適合率)で上回ることができます。
これは、ユニバーサルな物体検出のために設計された革新的なAIフレームワークであるUniDetectorの概要でした。もしこの研究に興味があり、詳細を知りたい場合は、以下のリンクをクリックしてさらなる情報を見つけることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





