クラウド上で機械学習モデルを本番環境にデプロイする
This title emphasizes the idea of deploying machine learning models to production environments seamlessly on the cloud, highlighting the smoothness and ease of the process.

AWS、またはAmazon Web Servicesは、多くのビジネスで使用されるクラウドコンピューティングサービスであり、ストレージ、分析、アプリケーション、展開サービスなど、さまざまな機能を備えています。これは、ペイアズユーゴースキームを使用してサーバーレスでビジネスをサポートするために、いくつかのサービスを活用するプラットフォームです。
AWSは、機械学習モデリング活動もサポートしています。開発から本番まで、モデル作成などの活動をサポートするためのさまざまなサービスがあります。スケーラビリティとスピードが必要なすべてのビジネスにとって、柔軟性は不可欠です。
この記事では、AWSクラウド内の機械学習モデルを本番環境にデプロイする方法について説明します。それをどのように行うのでしょうか?さらに探求してみましょう。
準備
このチュートリアルを始める前に、AWSアカウントを作成する必要があります。すべてのAWSサービスにアクセスするためにそれらが必要になります。私は読者がこの記事に従うために無料枠を使用すると想定しています。また、読者がPythonプログラミング言語を使用し、機械学習の基本知識を持っていると仮定します。また、データの前処理やモデル評価などのデータサイエンスの他の側面には焦点を当てず、モデルのデプロイメントに集中することになります。
それを念頭に置いて、AWS Cloudサービスにおける機械学習モデルのデプロイメントの旅を始めましょう。
AWSでのモデルデプロイメント
このチュートリアルでは、与えられたデータから離脱を予測する機械学習モデルを開発します。トレーニングデータセットはKaggleから取得し、こちらからダウンロードできます。
データセットを取得したら、データセットを保存するためのS3バケットを作成します。AWSサービス内でS3を検索し、バケットを作成します。
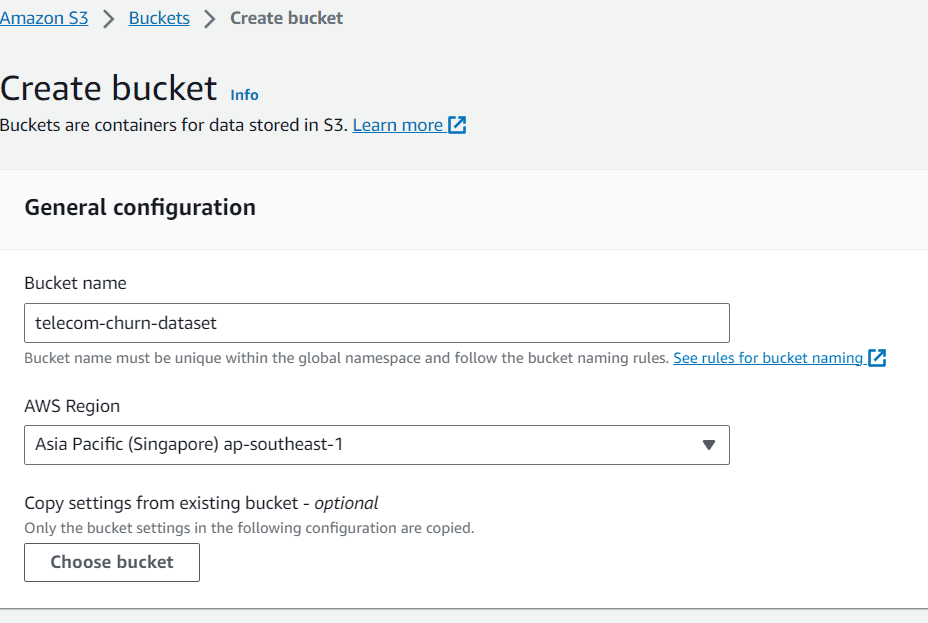
この記事では、バケットを「telecom-churn-dataset」と名付け、シンガポールに配置しました。必要に応じて変更することもできますが、今はこれで進めましょう。
バケットの作成を終え、データをバケットにアップロードしたら、AWS SageMakerサービスに移動します。このサービスでは、Studioを作業環境として使用します。Studioを使ったことがない場合は、進む前にドメインとユーザーを作成しましょう。
最初に、Amazon SageMaker管理設定の中のDomainsを選択します。
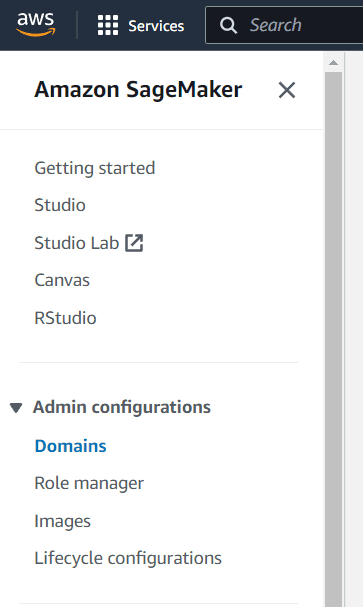
ドメインでは、選択するための多くのボタンが表示されます。この画面では、新しいドメイン作成ボタンを選択します。
ユーザー名を持つ新しいドメインがダッシュボードに作成されるのを確認したら、作成した新しいドメインを選択し、ユーザーを追加するボタンをクリックします。
次に、お好みに合わせてユーザープロフィールに名前を付けます。実行ロールについては、現時点ではデフォルトのままにしておきます。これは、ドメイン作成プロセス中に作成されたものです。
キャンバスの設定まで次に進んでください。このセクションでは、タイムシリーズ予測など、必要のない設定をオフにします。
すべてが設定されたら、スタジオの選択肢に移動し、ユーザー名と共に「スタジオを開く」ボタンを選択します。
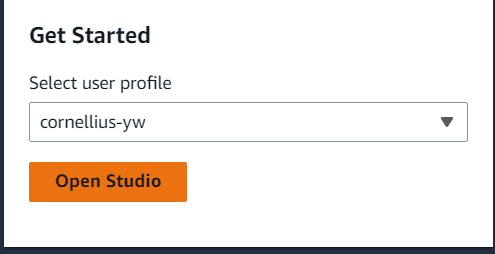
スタジオ内で、フォルダのように見えるサイドバーに移動し、そこで新しいノートブックを作成します。以下の画像のように、デフォルトのままにしておくことができます。
 画像提供:著者
画像提供:著者
新しいノートブックで、チャーン予測モデルを作成し、APIの推論に展開して、本番で使用できるようにします。
まず、必要なパッケージをインポートし、チャーンデータを読み込みます。
import boto3import pandas as pdimport sagemakersagemaker_session = sagemaker.Session()role = sagemaker.get_execution_role()df = pd.read_csv('s3://telecom-churn-dataset/telecom_churn.csv')  画像提供:著者
画像提供:著者
次に、上記のデータをトレーニングデータとテストデータに分割します。
from sklearn.model_selection import train_test_splittrain, test = train_test_split(df, test_size = 0.3, random_state = 42)
テストデータを元のデータの30%と設定します。データを分割した後、それらをS3バケットにアップロードします。
bucket = 'telecom-churn-dataset'train.to_csv(f's3://{bucket}/telecom_churn_train.csv', index = False)test.to_csv(f's3://{bucket}/telecom_churn_test.csv', index = False)
現在、3つの異なるデータセットで構成されるS3バケット内のデータを確認することができます。
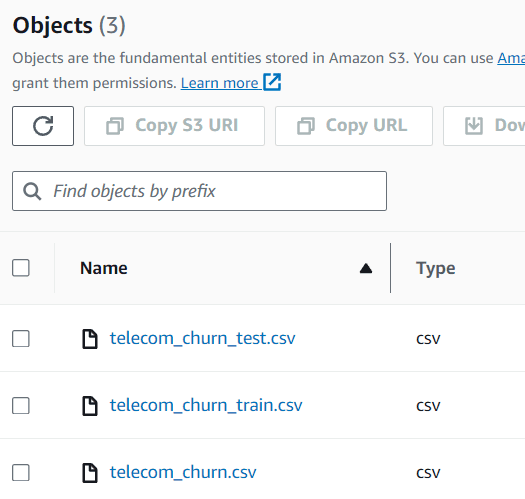 画像提供:著者
画像提供:著者
データセットの準備が整ったので、チャーン予測モデルを開発し、展開します。AWSでは、機械学習トレーニングにはスクリプトトレーニングメソッドをよく使用します。そのため、トレーニングを開始する前にスクリプトを作成します。
次のステップでは、同じフォルダにtrain.pyという名前の追加のPythonファイルを作成する必要があります。
 画像提供:著者
画像提供:著者
このファイルの中では、チャーンモデルを作成するためのモデル開発プロセスを設定します。このチュートリアルでは、Ram Vegirajuのコードの一部を使用します。
まず、モデルを開発するために必要なすべてのパッケージをインポートします。
import argparseimport osimport ioimport boto3import jsonimport pandas as pdfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_scoreimport joblib
次に、パーサーメソッドを使用して、トレーニングプロセスに入力できる変数を制御します。モデルをトレーニングするためのスクリプトに置く全体のコードは以下の通りです。
if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--estimator', type=int, default=10) parser.add_argument('--sm-model-dir', type=str, default=os.environ.get('SM_MODEL_DIR')) parser.add_argument('--model_dir', type=str) parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN')) args, _ = parser.parse_known_args() estimator = args.estimator model_dir = args.model_dir sm_model_dir = args.sm_model_dir training_dir = args.train s3_client = boto3.client('s3') bucket = 'telecom-churn-dataset' obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_train.csv') train_data = pd.read_csv(io.BytesIO(obj['Body'].read())) obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_test.csv') test_data = pd.read_csv(io.BytesIO(obj['Body'].read())) X_train = train_data.drop('Churn', axis =1) X_test = test_data.drop('Churn', axis =1) y_train = train_data['Churn'] y_test = test_data['Churn'] rfc = RandomForestClassifier(n_estimators=estimator) rfc.fit(X_train, y_train) y_pred = rfc.predict(X_test) print('Accuracy Score: ',accuracy_score(y_test, y_pred)) joblib.dump(rfc, os.path.join(args.sm_model_dir, "rfc_model.joblib"))最後に、SageMakerが推論を行うために必要な4つの異なる関数(model_fn、input_fn、output_fn、predict_fn)を配置する必要があります。
#モデルをロードするための逆シリアライズされたモデルdef model_fn(model_dir): model = joblib.load(os.path.join(model_dir, "rfc_model.joblib")) return model#アプリケーションのリクエスト入力def input_fn(request_body, request_content_type): if request_content_type == 'application/json': request_body = json.loads(request_body) inp_var = request_body['Input'] return inp_var else: raise ValueError("このモデルはapplication/jsonの入力のみをサポートしています")#予測関数def predict_fn(input_data, model): return model.predict(input_data)#出力関数def output_fn(prediction, content_type): res = int(prediction[0]) resJSON = {'Output': res} return resJSON
スクリプトが準備できたら、トレーニングプロセスを実行します。次のステップでは、上記で作成したスクリプトをSKLearnエスティメータに渡します。このエスティメータはSagemakerオブジェクトであり、トレーニングプロセス全体を処理し、次のコードと同様のすべてのパラメータを渡すだけで済みます。
from sagemaker.sklearn import SKLearnsklearn_estimator = SKLearn(entry_point='train.py', role=role, instance_count=1, instance_type='ml.c4.2xlarge', py_version='py3', framework_version='0.23-1', script_mode=True, hyperparameters={ 'estimator': 15})sklearn_estimator.fit()
トレーニングが成功すると、次のレポートが表示されます。
Image by Author
SKLearnトレーニングのDockerイメージとモデルアーティファクトの場所を確認する場合は、次のコードを使用してアクセスできます。
model_artifact = sklearn_estimator.model_dataimage_uri = sklearn_estimator.image_uriprint(f'モデルアーティファクトは次の場所に保存されています:{model_artifact}')print(f'イメージURIは次のとおりです:{image_uri}')
モデルが準備できたので、APIエンドポイントにモデルをデプロイします。そのために、次のコードを使用できます。
import timechurn_endpoint_name='churn-rf-model-'+time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())churn_predictor=sklearn_estimator.deploy(initial_instance_count=1,instance_type='ml.m5.large',endpoint_name=churn_endpoint_name)
デプロイが成功すると、モデルエンドポイントが作成され、予測を作成するためにそれにアクセスすることができます。Sagemakerダッシュボードでもエンドポイントを確認できます。
Image by Author
これでエンドポイントで予測を行うことができます。それには、次のコードでエンドポイントをテストすることができます。
client = boto3.client('sagemaker-runtime')content_type = "application/json"#置き換える予定の入力データrequest_body = {"Input": [[128,1,1,2.70,1,265.1,110,89.0, 9.87,10.0]]}#置き換える予定のエンドポイント名endpoint_name = "churn-rf-model-2023-09-24-12-29-04" #データのシリアル化data = json.loads(json.dumps(request_body))payload = json.dumps(data)#エンドポイントを呼び出すresponse = client.invoke_endpoint( EndpointName=endpoint_name, ContentType=content_type, Body=payload)result = json.loads(response['Body'].read().decode())['Output']result
おめでとうございます。これでAWSクラウドにモデルを正常にデプロイしました。テストプロセスが完了したら、エンドポイントをクリーンアップすることを忘れないでください。次のコードを使用してそれを行うことができます。
from sagemaker import Sessionsagemaker_session = Session()sagemaker_session.delete_endpoint(endpoint_name='your-endpoint-name')
必要がない場合は、使用しているインスタンスをシャットダウンし、S3ストレージをクリーンアップすることを忘れないでください。
さらなる読み物として、SKLearnエスティメータやバッチ変換の推論についても詳しくお読みください。
結論
AWS Cloudプラットフォームは、多くの企業がビジネスをサポートするために使用するマルチ目的プラットフォームです。データ分析を目的としたサービスの1つは、特にモデルの作成です。この記事では、AWS SageMakerの使用方法とモデルのエンドポイントへの展開方法について学びました。 Cornellius Yudha Wijayaはデータサイエンスアシスタントマネージャー兼データライターです。Allianz Indonesiaでフルタイムで働きながら、Pythonとデータのヒントをソーシャルメディアや執筆メディアで共有するのが好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
 Image by Author
Image by Author 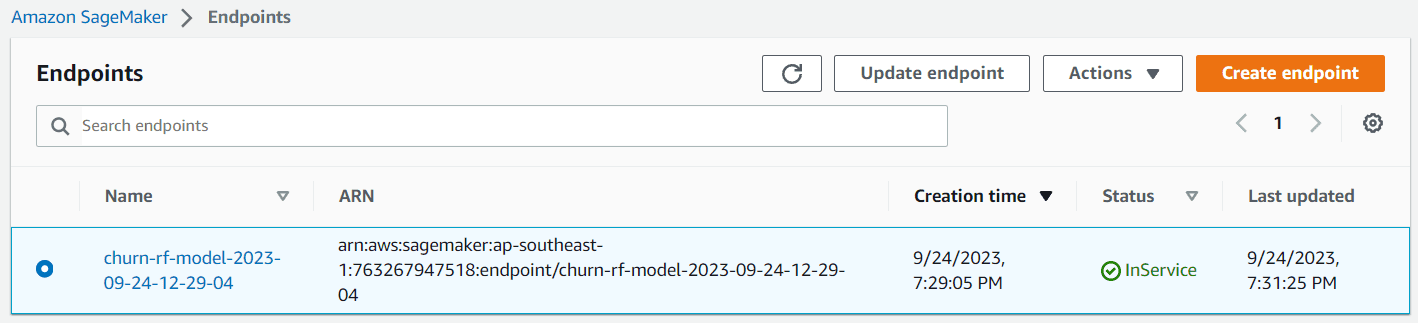 Image by Author
Image by Author 





