Google DeepMindの研究者は、機能を維持しながら、トランスフォーマーベースのニューラルネットワークのサイズを段階的に増やすための6つの組み合わせ可能な変換を提案しています
DeepMindの研究者は、トランスフォーマーベースのニューラルネットワークのサイズを増やすための6つの変換を提案しています


最近、トランスフォーマベースのニューラルネットワークは注目を集めています。トランスフォーマーアーキテクチャ(図1参照)は、機械翻訳、テキスト生成、質問応答など、自然言語処理の活動の中で業界標準として浮上しました。トランスフォーマベースのモデルの効果はNLPに制限されません。音声認識、コンピュータビジョン、レコメンデーションシステムなど、他のいくつかの分野でも成功を収めています。言語、ビジョン、マルチモーダルの基礎モデルは、数十億から数兆のパラメータを持つこれらのモデルの中で最も複雑で効果的です。
ただし、新しいモデルは通常、以前に学習した小さなモデルのスキルを活用せずに最初から教えられます。さらに、モデルのサイズはトレーニング中も一貫して維持されます。トレーニングに必要なトレーニングデータの量の増加により、モデルサイズの計算コストは二次的に増加します。事前学習モデルのパラメータを再利用するか、トレーニング中にモデルのサイズを動的に増やすことで、トレーニングの総コストを削減することができます。ただし、トレーニングの進捗を犠牲にすることなくこれを行うことは容易ではありません。これらの制限を解決するために、トランスフォーマベースのモデルには、機能保存パラメータ拡張変換が提供されています。
これらの変換は、モデルのサイズを増やし、その機能を変えずにモデルの潜在的な容量を増やすため、トレーニングを継続できます。これらの組み合わせ可能な変換は、アーキテクチャの独立した次元で動作し、細粒度なアーキテクチャの拡張を可能にします。以前の研究では、小さな畳み込みモデルや密なモデルのための技術を拡張したトランスフォーマベースのモデルのための機能保存パラメータ拡張変換も提案されています。
- 「LangChainとGPT-4を使用した多言語対応のFEMAディザスターボットの研究」
- コンピュータ科学の研究者たちは、モジュラーで柔軟なロボットを作りました
- MITの研究者は、ディープラーニングと物理学を組み合わせて、動きによって損傷を受けたMRIスキャンを修正する方法を開発しました
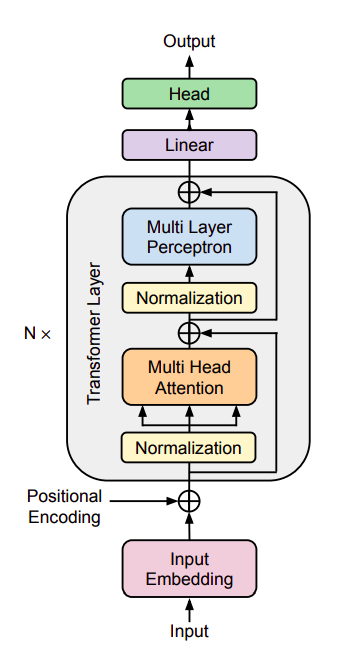
この研究では、Google DeepMindとトゥールーズ大学の研究者が、トランスフォーマアーキテクチャに適用される機能保存変換の最も包括的でモジュラーなコレクションを開発しました。この論文の6つの貢献は、トランスフォーマーアーキテクチャに適用される6つの組み合わせ可能な機能保存変換です。以下に示します。
- MLP内部表現のサイズ
- アテンションヘッドの数
- アテンションヘッドの出力表現のサイズ
- アテンション入力表現のサイズ
- トランスフォーマーレイヤーの入力/出力表現のサイズ
- レイヤーの数
著者たちは、各変換において追加パラメータの初期化に可能な制限を最小限に抑えながら、正確な機能保存性がどのように達成されるかを実証しています。これらの貢献については、論文で詳しく議論されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「NTUとSenseTimeの研究者が提案するSHERF:単一の入力画像からアニメーション可能な3D人間モデルを復元するための汎用的なHuman NeRFモデル」
- このUCLAのAI研究によると、大規模な言語モデル(例:GPT-3)は、様々なアナロジー問題に対してゼロショットの解決策を獲得するという新たな能力を獲得していることが示されています
- SalesforceのAI研究者が、LLMを活用した自律エージェントの進化と革新的なBOLAA戦略を紹介します
- 「IBMの「脳のような」AIチップが、環境にやさしく効率的な未来を約束します」
- スタビリティAIは、StableChatを紹介します:ChatGPTやClaudeに似た会話型AIアシスタントの研究プレビュー
- Google DeepMindの研究者がSynJaxを紹介:JAX構造化確率分布のためのディープラーニングライブラリ
- 「AIモデルは強力ですが、生物学的に妥当でしょうか?」






