「物理学と流体力学に応用されたディープラーニング」
Deep learning applied to physics and fluid dynamics.
数値シミュレーションは、物理システムの振る舞いを理解するために長年にわたって使用されてきました。流体が構造物と相互作用する方法、応力下でジオメトリが変形する方法、または加熱条件下での熱分布などです。航空宇宙、自動車、エネルギーなど、より多様な領域に応用されるこれらの計算により、プロトタイプの寸法設計や安全なプロセスを構築せずに確保することができます。ただし、それらは計算コストが高く、数時間、数日、または数週間かかることがあります。そこで、機械学習、特にディープラーニングが光を放ち、処理時間をわずか数分に短縮します!
計算流体力学シミュレーション
一般的な数値シミュレーションは、通常以下の形式を持つ偏微分方程式(PDE)のセットを解くことによって物理システムを記述できます:
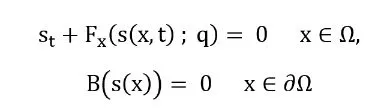
𝐹はドメインΩ ∈ ℝ上の微分演算子を表し、𝜕Ωはドメインの境界を、𝑞はパラメータを表します。システムの解𝑠(𝑥, 𝑡)は、空間座標と時間に依存し、添え字は偏微分を示します。この一連の方程式は、物理ドメインを小さなパーツ(有限要素または有限体積)に離散化して線形化したシステムを取得するために解くことができます。このアプローチは、流体力学に特に適用されます。
- 「人工知能の世界を探索する:初心者ガイド」
- Google AIはWeatherBench 2を紹介します:さまざまな天気予測モデルの評価と比較のための機械学習フレームワーク
- 「PDF、txt、そしてウェブページとして、あなたのドキュメントと話しましょう」
流体力学では、システムは主にナビエ・ストークス方程式によって表され、質量と力のバランスに基づいてすべての流体の振る舞いを記述するための解析的な解法はありません。より簡単な2D形式では、次のように記述できます:
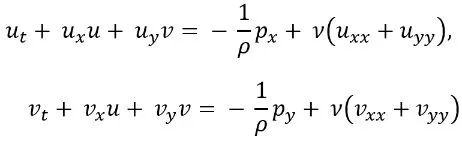
ここで、𝑢はx軸に沿った速度、𝑣はy方向の速度、𝑝は圧力、𝜌は密度、𝜈は粘度を表します。
計算流体力学(CFD)シミュレーションは、境界条件(ドメインの制約内での圧力と速度など)とともに、線形化された離散化されたシステムを反復的なマルチグリッドソリューション法によって解くことで構成されます。直接法は実世界の応用には非現実的であり、3D直交座標及び等間隔グリッド(i³要素)に対する行列の逆行列の計算はi⁷の計算量になります。
効率的なソルバーを使用してHPC並列環境で作業していても、このような操作の計算コストは数時間かかり、動的なエンジニアリングプロセスにとって有害になる可能性があります。解決策は?ますますAIが重要になってきています!
代替モデル
入出力の関係が可能である場合、AIはそのような振る舞いをモデル化するための候補として現れます。このシナリオはCFDと完全に一致し、幾何学的な設定はグリッドとその要素としてパラメータ化され、境界条件と関連付けられた出力であるグリッド内の物理フィールド(圧力、速度など)にリンクすることができます。構築されたモデルは、従来のシミュレーターをより低い計算コストで置換できるメッシュレスソルバーとして機能することができます。
一般的には、PDEパラメータ(𝑥、𝑞、𝑡):𝑋 ∈ ℝⁿ とその解𝑠(𝑥, 𝑡):𝑌 ∈ ℝⁿ の間のマッピングを学習したいと考えています。言い換えると、予測関数𝐺:(𝑥、𝑞、𝑡)→𝑠(𝑥, 𝑡)を見つけたいということです。ここで、𝑡は定数である場合もあります(定常解析)。したがって、それを行うためのさまざまな方法を想像することができます。
簡略化モデル
関係をモデル化するための最も簡単なアプローチは、データの次元を削減することによってそれを簡素化することです。この方法は、入力と出力の両方に適用することができます。たとえば、グリッドポイントの完全な座標の代わりに、先述のジオメトリを𝑘 ∈ N | 𝑘 < nとして表現することができます。ギアには歯数、基本半径、幅などがあります。
出力には、s(𝑘) ∈ Nとして表されるグローバルな性能指標を選択することができます。例としては、プロトタイプに作用する力、抗力係数や揚力係数などがあります。
単純化の利点は、より基本的で高速なAIモデルを適用できることです。線形/多項式回帰であっても、関数𝐺:k → 𝑠(k)を学習する際に大きな問題はありません。
欠点は、このように次元を削減すると、情報の固有の損失が発生し、設計空間以外のデータに対してモデルが一般化しにくくなることです。
体積モデル
データの次元を削減する代わりに、元の体積グリッド(𝑌 ∈ ℝⁿ)を使用することもできます。これにより、より複雑さが増し、ディープラーニングの技術が必要になります。
非構造化グリッドを扱う場合、一般的なアプローチは、一様な構造メッシュ上に補間することです。自由流速と圧力などの重要な特徴は各ボクセルに埋め込むことができ、それにより対応する予測が可能になります。その結果、流体のない領域はヌル値として表され、ジオメトリがエンコードされます。
このボクセルベースの表現では、画像認識タスクで一般的に使用される一連のテクニック、畳み込みを利用できます。畳み込みニューラルネットワーク(CNN)は、フィルタリングのアプローチにより、ローカルおよびグローバルな特徴を抽出できます。異なる段階を統合することで、異なるスケールの特徴抽出が可能となり、より複雑なモデル(u-netやオートエンコーダ/デコーダを含む)が生成されます。
順序付けられていないデータをボクセル/画像の形状に変換する代わりに、別の解決策として座標を積極的にエンコードする方法があります。これにより、各ポイントが対応するシミュレーション/例のインデックスと関連付けられた表形式でデータを記述できます。次のセクションで見るように、これがpytorch geometricで行われることです!
理論的には、各ポイントに対してモデルをトレーニングして適用することは可能ですが、このアプローチは通常、ローカル情報を特定するために重要なノード間の関係を捕捉することができません。この制限に対処するために開発されたモデルの別のクラスであるGraph Neural Networksが登場します。
幾何学モデル
CFDでは、領域ではなく表面における物理量を特定することがしばしば求められます。これにより、モデル構築戦略について考える必要があります。先ほど概説したボクセル化メソッドは有望な結果を示していますが、ジオメトリに対応するまばらな点群を表現するためには一様な構造グリッドの作成が必要です。ただし、これは複雑なジオメトリに対しては実用的ではありません。形状周りの不要な情報を含むことで不必要な計算コストが発生するか、粗いグリッドによる貴重な情報の損失が発生します。
より効率的な解決策は、幾何学的ディープラーニングの分野で提供されています。これは主に物体認識や意味的セグメンテーションでの成功で知られています。このアプローチはGraph Neural Networksと密接に関連しており、データを座標とインデックスの表として記述し、順序付けられていない点群として扱います。幸いなことに、非構造化メッシュにはそれが備わっています!
このような形式でデータを記述するために、GNNSと幾何学モデルに特化した最先端のpytorchフレームワークの拡張であるpytorch geometricを使用できます。AirfRANS⁴などのグラフデータセットも含まれており、RANSシミュレーション用の2D NACA翼データセットなどを使用できます。実際のコードにどのように変換されるかを簡単に見てみましょう:
from torch_geometric.datasets import AirfRANSfrom matplotlib import pyplot as pltdataset = AirfRANS(root='/tmp/AirfRANS', task='full', train=True) # ダウンロード例 = dataset[0]fig, ax = plt.subplots(figsize=(12,5))ax.set_aspect('equal', adjustable="datalim")# 座標x、yと圧力を使ってポイントクラウドを散布im = ax.scatter(*example.pos.T, s=0.5, c=example.y[:, 2]) fig.colorbar(im, ax=ax)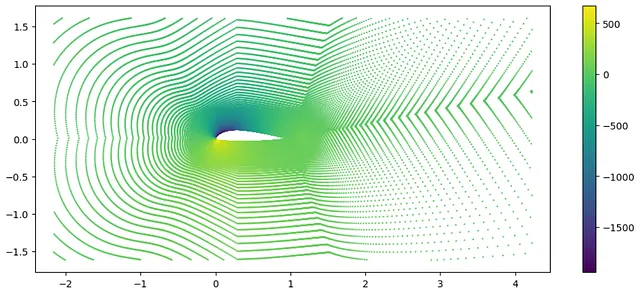
データセットの性質を把握すると、次の質問が浮かび上がります:どのようにしてそれを使用してモデルをトレーニングできるのでしょうか?Pytorch Geometricの助けを借りて、上記で説明した形状に変換します。 DataLoaderは、batch属性により、データセットをミニバッチでループ処理することができます。これは、各シミュレーションで集計関数を使用するために重要です。
from torch_geometric.loader import DataLoader# 訓練データセットとテストデータセットを区別せず、単にデータローダを分析するdataloader = DataLoader(dataset, batch_size=2) # バッチサイズ2のシミュレーションfor data in loader: # データセットをループ処理し、バッチを返す print(data), print(data.batch) break>>> DataBatch(x=[351974, 5], y=[351974, 4], pos=[351974, 2], surf=[351974], name=[2], batch=[351974], ptr=[3])>>> tensor([0, 0, 0, ..., 1, 1, 1])データの説明が完了したら、どのようなタイプのモデルが適していますか? Pytorch geometricは、非常に有用な事前設計されたニューラルレイヤーと操作の範囲を提供しています。おそらく最も伝統的なものの1つは、PointNet¹です。この分野の先駆者の1つであるこのアーキテクチャは、2017年に提案され、現在でも非常に重要な2つの主要な利点を導入しました。
PointNetの成功の鍵は、プーリング操作にあります。シミュレーション全体の情報を1つのベクトルに凝縮することで、グローバルな洞察を捉え、複数のポイントから単一のグローバル値に移行することができます。これにより、モデルの次元を変更できないという問題を解決する効果的な手段です。言い換えれば、データセット𝐷 = {Dᵢ | i ∈ N, 1 ≤ i ≤ m}(mはシミュレーションの総数)を考慮します。各シミュレーションDᵢに対して、ポイントの集合X = {Xⱼ(pⱼ, fⱼ) | j ∈ N , 1 ≤ i ≤ n}を定義できます。連結された特徴ベクトル(pⱼ, fⱼ) ∈ ℝʰ | h ∈ N。この方法で、プーリングは次の変換を行います:
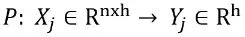
これは、ポイントクラウドを単一の値またはベクトルに縮小する分類タスクに必要です。プーリングのもう1つの利点は、各ポイントにグローバル情報を注入することで、セグメンテーションタスクに役立ちます。グローバル情報ベクトルは、各ポイントの特徴ベクトルに連結でき、その次元を増やすことができます。この方法で、各ポイントに適用されるモデルは、単にそのポイントの情報だけでなく、例全体の一般的なアイデアも持っています。形式的には、非構造化データセットのポイントの総数をzとして、Pointnetアーキテクチャが行う操作のシリーズは、簡略化された方法で次のように記述できます:
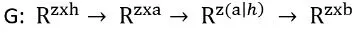
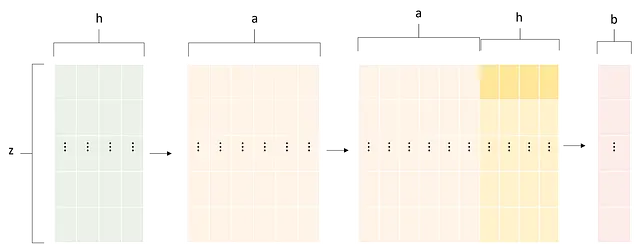
ここで、同じMLPが各ポイント/行に適用され、列は特徴を表しています。
後にはより複雑なモデルも提案されました。たとえば、Pointnet++²では、Pointnetを異なる階層レベルで使用するアイデアが提案されました。このアプローチは、グローバルな特徴だけでなく、より小規模な現象を表すベクトルも組み合わせます。これは、CFDの問題に取り組む際に特に価値があります。たとえば、航空機全体をシミュレートする場合、異なる幾何学的コンポーネント間で異なる振る舞いが生じます。翼はタービンとは異なる現象を示します。さらに細かいスケールでは、翼の背面と前面の間にも変動があり、特徴的な圧力分布が生じます。
グラフニューラルネットワークは、データをエッジと頂点として表し、ノード間の関係を反映することによって、前述の概念を一般化します。これにより、通常のグリッドではなく、順序のないポイントのセットに直接適用することができます。
典型的なGNNは、頂点としてノードをエンコードします(vⱼ = Xⱼ)、その座標を特徴として持ちます。エッジはノード間の接続性を表し、特定のノードとその近傍との距離(またはより複雑な式など)をエンコードします。たとえば、E = {(vᵢ, vⱼ) | ‖pᵢ, pⱼ‖₂ < r}(ここでpは座標、vは距離r内の近隣の頂点iおよびjを表します)。
このグラフが計算されると、反復的な更新が行われ、ローカルな情報が伝播され、非線形性とますます複雑な埋め込みが生成されます。更新ステップが多いほど、ノードはグラフのより遠い範囲から情報を取得します。グラフの更新関数、更新回数、グラフの初期構築方法、近傍の計算方法など、さまざまなグラフアーキテクチャを定義することができます(たとえば、残差接続や注意メカニズムなどの中間手順も可能です)。単純な更新手順では、次のように集約関数を使用します:
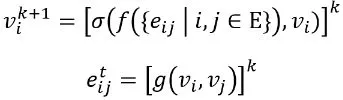
ここで、𝑓は近傍の頂点の集約関数を表し、非線形関数𝜎によって更新され、𝑔はエッジを更新する関数であり、先述したユークリッド距離などの関数です。
汎用的なモデルは、回転、変換、および順列に対する不変性という帰納的な特性も持っているべきです。クラシックなグラフアーキテクチャはGraphSage³です。その軽い計算コストにより、幾何学的データで効率的にトレーニングし、大きな成功を収めることができます。上記の式を使用することで、fを単純な連結操作に指定し、Wᵏによる重み行列の乗算を続けることができます。提案される集約器は、平均または最大プーリングです。近隣は一様にサンプリングされ、固定サイズで全体のセットから抽出されます。
上記に説明されているより単純なモデルに加えて、より複雑でモダンなグラフアーキテクチャが後年開発され、研究の有望な分野となっています。
物理を表現する
適切なモデルを特定したので、次の問題が生じます:物理システムの固有の特性を効果的に組み込む方法は何でしょうか?よく使用されるアプローチの1つは、物理法則をソフト制約またはペナルティ化の方法によって施行することです。具体的には、Physically Informed Neural Networks(PINNs)は、PDEの残差を用いてモデルをペナルティ化することで、その正確な遵守を保証します。CFDに関連する場合、これらはナビエストークス方程式です。各方程式の偏微分は、ディープラーニングフレームワークを使用してモデルの予測からADによって計算することができます。同様に、ディリクレ境界条件およびノイマン境界条件も同じ方法で組み込むことができます。その結果、このアプローチは次のような洗練された形式の損失関数につながります:
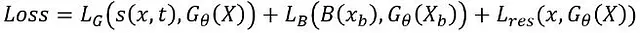
ここで、LGとLBは、それぞれデータと境界条件の損失を表し、2つの引数を持つ教師あり関数を構成します。LᵣₑₛはPDEの残差関数であり、Xbとxbはモデルの入力データと境界条件点上のPDEを表します。Bは境界条件の値を取得します。G𝜃はパラメータ𝜃を持つネットワークの順伝播関数です。
したがって、モデルは圧力と速度のバランスの両方を尊重し、未知のデータに対しても一般化能力が向上します。
損失関数の表現は、PINNsがデータと物理に基づいた教師ありアプローチで使用できることを強調しています。ただし、LG項はオプションであり、ネットワークを教師なしで訓練することもできます。これにより、解の空間が大幅に広がります。初期の予測は本質的にランダムですので、ネットワークの最適化は困難であり、適切な探索目的を特定することは機械学習における未解決の問題です。さまざまな解決策が想像されます。代替損失関数や最適化戦略、ネットワークの一部が直接指定された値を満たすように境界条件を強制することなどが挙げられます。
高周波信号
幾何学的ディープラーニングモデルは、収束が遅く高周波関数の学習が困難であるという課題に直面しています。この現象は、特に乱流流体力学を扱う場合に顕著です。この問題に対処するために、Implicit Neural Representationsの分野では効果的な戦略が提案されています。
これらの変換は、ディープネットワークが低周波関数の学習にバイアスを持つという事実に根ざしています。そのため、これらの技術は、高周波関数の表現を改善するのに役立ちます。例として、フーリエ特徴による展開があります:
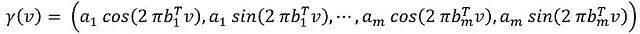
ニューラルネットワークを使用してこの技術を適用すると、幾何学的なコンテキストなどの低次元の問題領域で高周波関数の学習が容易になります。周波数パラメータを調整することで、モデルが捉えることができる周波数スペクトルを操作することができます。
実際的には、aⱼ = 1とし、bⱼをランダム分布から選択することで優れた結果を得ることができます。この分布の標準偏差を微調整することができ、通常はガウス分布です。より広い分布は高周波成分の収束を促進し、結果が改善されます(特に画像関連のタスクで、より高い定義を実現します)。逆に、極端に広い分布は出力にアーティファクトを導入する可能性があります(ノイズのある画像を生成する)、適合不足と過適合の間のトレードオフが存在します。
より現代的なアプローチでは、正弦波表現ネットワーク(SIRENs)を使用することができます。SIRENsは、次の形式の周期的な活性化関数を提案しています:
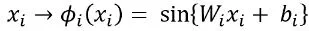
高周波表現を改善するだけでなく、SIRENsは微分可能です。これは、SIRENの導関数がSIREN自体であり、正弦関数の導関数が余弦関数であるのと同様です。一部の一般的な活性化関数はこの性質を持っていません。例えば、ReLUは不連続な導関数を持ち、ゼロの二階導関数を持っています。他のいくつかの関数はこの望ましい能力を持っていますが、Softplus、Tanh、またはELUなどの関数はうまく振る舞わず、細部を正確に表現できないことがあります。
したがって、彼らは私たちが非常に興味を持っているようなPDEのような逆問題を表現するのに適しています。さらに、SIRENは他のアーキテクチャよりも収束が速いことが証明されています。
意図した結果を達成するためには、適切な初期化スキームが不可欠です。この初期化は、ネットワーク全体で活性化分布を保持し、最終出力がレイヤーの数に独立していることを保証します。解決策は、次の方法で均一な初期化スキームを採用することにあります:
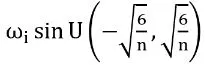
したがって、各ユニットへの入力が標準偏差1で正規分布に従うようになります。さらに、ネットワークの最初のレイヤーは[-1, 1]の複数の周期にわたるべきであり、これは sin(ω₀ ⋅ 𝑊𝑥 + 𝑏) で実現できます。この値は、モデル化された関数の周波数と観測数に応じて変更する必要があります。単一の周波数を使用するという制限は、後に呼ばれるModulated SIRENsで処理されました。
結論
おそらく、Deep Learningが、非構造化およびノイズのあるデータを扱う場合でも、数値シミュレーションのための代理モデルを作成する方法について、より明確な理解を持つことができました。ネットワークの一般化能力を向上させるためには、さまざまな技術を組み合わせることができます。これには、基になる偏微分方程式(PDE)の物理学を組み込むことから、Implicit Neural Representationを使用することまで、さまざまな手法があります。このダイナミックな研究分野は、より信頼性が高くなるにつれて、今後数年間で大幅に拡大することが予想されています。この手法は、数値シミュレーションを置き換えることを目指すのではなく、シミュレーション自体や実験データを活用したより迅速な代替手法を提供します。流体力学のシミュレーション、物理方程式、Deep Learningを組み合わせることができるなら、なぜそれらを単独で制限するのでしょうか?
参考文献
[1]: PointNet
C. R. Qi, H. Su, K. Mo, L. J. Guibas, PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation, arXiv:1612.00593 [cs]ArXiv: 1612.00593 (Apr. 2017). URL http://arxiv.org/abs/1612.00593
[2]: PointNet++
C. R. Qi, L. Yi, H. Su, L. J. Guibas, PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space, arXiv:1706.02413[cs] ArXiv: 1706.02413 (Jun. 2017). URL http://arxiv.org/abs/1706.02413
[3]: GraphSage
W. L. Hamilton, R. Ying, J. Leskovec, Inductive Representation Learning on Large Graphs, arXiv:1706.02216 [cs, stat]ArXiv: 1706.02216 (Sep. 2018). URL http://arxiv.org/abs/1706.02216
[4]: AirfRANS
F. Bonnet, A. J. Mazari, P. Cinnella, P. Gallinari, Airfrans: High fidelity computational fluid dynamics dataset for approximating reynolds averaged navier-stokes solutions (2023). arXiv:2212.07564.
[5]: Point-GNN
W. Shi, R. R. Rajkumar, Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud (2020) IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020): 1708–1716.
[6]: Scientific Machine Learning through Physics-Informed Neural Networks: Where we are and What’s next
S. Cuomo, V.S. Di Cola, F. Giampaolo, Scientific Machine Learning Through Physics–Informed Neural Networks: Where we are and What’s Next. J Sci Comput 92, 88 (2022). https://doi.org/10.1007/s10915-022-01939-z
[7]: Learning differentiable solvers for systems with hard constraints
G. Negiar, M.W. Mahoney, A.S. Krishnapriyan, Learning differentiable solvers for systems with hard constraints (2022). ArXiv, abs/2207.08675.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AIとのプログラミング」
- このAI論文は、さまざまなディープラーニングと機械学習のアルゴリズムを用いた行動および生理学的スマートフォン認証の人気のあるダイナミクスとそのパフォーマンスを識別します
- 「大規模言語モデルのダークサイドの理解:セキュリティの脅威と脆弱性に関する包括的なガイド」
- コードのための大規模な言語モデルの構築とトレーニング:StarCoderへの深い探求
- 「ガードレールでLLMを保護する」
- 「マイクロソフトは、VALLE-Xをオープンソース化しました:多言語対応のテキスト読み上げ合成および音声クローニングモデル」
- 「ChatGPTは本当に中立なのか?AIによる対話エージェントの政治的バイアスに関する実証的研究」