dbtのインクリメンタル – 正しい方法
dbtのインクリメンタル - 正しい方法
フルロードの苦痛から段階的なゲインへ(そしていくつかの間違いも)
GlamCornerのチームが従来のMySQLデータベースからELTを使用したPostgresデータベースに移行し、変換とモデリングのレイヤーとしてdbtを採用したとき、私たちは喜びました。dbtプロジェクトとプロファイルを設定し、モデル用の専用マクロを作成し、より多くのデータマートを構築して下流ニーズを満たしました。私たちは終わったと思っていました — 私は終わったと思っていましたが、最初の問題に直面しました。モデルの実行時間です。この記事では、私がdbtのインクリメンタルを採用し、ミスを犯し(誰が犯さないでしょうか?)、その過程で貴重な教訓を学んだ経験について説明します。
進化するモンスター
GlamCornerでは、サーキュラーファッションのゲームに取り組んでいます。私たちの「バックエンド」チームは、倉庫でRFIDスキャナーを使って、プロのようにアイテムをスキャンしています。また、ZendeskやGoogle Analyticsなどの高度なプラットフォームを使用して、お客様を特別な気分にさせています。そして、私たちの優れたソフトウェアエンジニアのおかげで、独自の社内在庫システムも持っています。これにより、フロントエンドとバックエンドのすべてのシステムがリンクされます。まさに天国での出来事です。しかし、私たちは成長し、運用年数を増やすにつれて、データベースがますます大きくなっています。そして、伝統的なフルテーブルのロードは、少し面倒に感じるようになってきました。
苦痛
「データを朝9時までに準備してほしい」という苦痛を理解するか、しないかです。

チームは完璧な(E)xtract and (L)oadを作成するための努力をし、集まり、乾杯します。しかしある日、(T)ransformationが「いや、ここではそのようには機能しない」と決め、実行時間を10分から90分に引き上げました。10分から90分に誇張しているかもしれませんが、すべてには理由があります。しかし、朝の8時55分にビジネスチームがコーヒーの最初の一杯を飲む前にドアをノックして、「最新のデータはどこですか?」と尋ねる恐怖は、毎日の通勤が地獄のようなものです。これはすべての苦労をゴミ箱に捨てるようなものであり、私自身、その現実を受け入れることはできません。
言ったことに戻りましょう: すべてには理由があります。なぜ私の時間を10分かけたおとぎ話が、90分の赤い角の悪魔になってしまったのかを説明するために、fct_bookingデータの例を取り上げましょう。このテーブルには、ウェブサイトから取得したすべての予約情報が含まれています。各booking_idは、ウェブサイトで予約された1つの注文を表します。
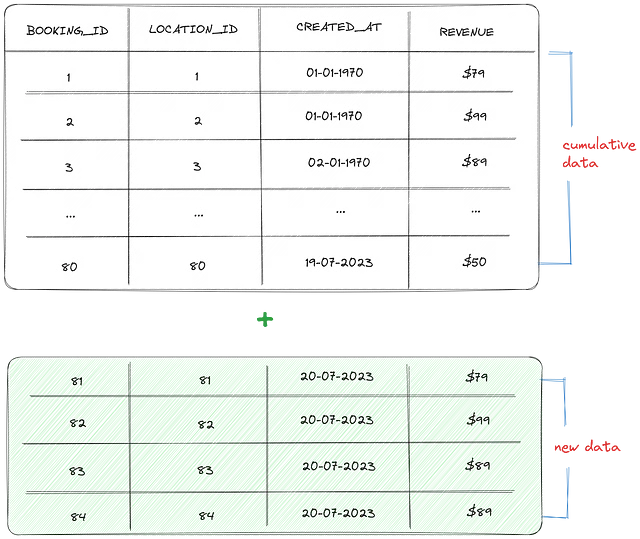
毎日、予約テーブルには4件の注文が追加されます。すでに80件の注文が含まれています。このモデルをdbtで実行すると、前日のテーブル全体が削除され、それらがすべて置き換えられます(過去の累積データの80件の注文と最新の日のために追加された4件の新しい注文を含む84件の注文)。さらに、新たに4件のレコードが追加されるたびに、クエリ時間が約0.5秒増加します。
今、4つの注文が1日で4000と同等であり、80の注文が実際には800,000のレコードを表していると想像してみてください。fct_bookingsテーブルを変換するのにどれくらいの時間がかかるか、そして例えば3ヶ月後にはどこにいるか、予想できますか?
さて、数学はあなたにお任せします。
黄金の卵
それで、dbtコミュニティのスレッドをふらふらと彷徨い、dbtのドキュメントをいい加減にざっと目を通して(誰もがそうしたことがあるでしょう)、dbt Incrementalの聖杯に偶然出くわしました。それはまるで針を干し草の中から見つけるようなものですが、針が金色で、干し草がコードでできているのです。
素人向けに言えば、dbt Incrementalは、最初からすべてのデータを処理する手間を省くことができます。新しいデータと変更されたデータだけを処理するだけで、時間とリソースを節約できます。これは実際に機能するショートカットであり、上司にトラブルを引き起こすことはありません。
dbt Incrementalの細かい詳細についてもっと知りたい場合は、このブログとドキュメントをチェックしてください:
ビッグデータ向けdbtインクリメンタルモデルのパワー
BigQueryでの実験
towardsdatascience.com
インクリメンタルモデル | dbt Developer Hub
dbtでビルドする際にインクリメンタルモデルを使用する方法については、このチュートリアルを読んでください。
docs.getdbt.com
dbtモデルにこのモデルを設定するには、モデルスクリプトの最初にconfigブロックを追加する必要があります。以下の2つのコンポーネントを念頭に置いてください:
- Materialized: デフォルトでは、dbtモデルのマテリアライズドビューは、設定がない場合には「テーブル」と等しいです。インクリメンタルモードを設定するには、マテリアライズドビューを「incremental」に設定します。他のdbtマテリアライズドビューについての詳細は、次を参照してください:
マテリアライズド | dbt Developer Hub
dbtでビルドする際にマテリアライズドを使用する方法については、このチュートリアルを読んでください。
docs.getdbt.com
- Unique_key: dbtのドキュメントによれば、ユニークキーの設定はオプションですが、どのように設定するかを合理的に考慮することが非常に重要です。基本的に、ユニークキーは、レコードが追加または変更されるべきかどうかをdbtに伝える主要な要素になります。考慮すべきいくつかの質問は次のとおりです:
- ユニークキーは本当に一意ですか?
- それは2つ以上の列の組み合わせですか?
ユニークキーを設定しないと、データの欠落や曖昧な値が発生する可能性がありますので、注意が必要です!
以下は、単一のユニークキーに対してconfigブロックを設定する例です:
ユニークキーが複数の列の組み合わせである場合、configを次のように調整できます:
注意:データを保存するためにBigQueryやSnowflakeを使用している場合、sync_modeの設定など、さらに追加の設定を調整するオプションがあるかもしれません。ただし、私の会社のデータベースはRedshift、具体的にはPostgresで構築されているため、そのような高度な機能はありません。
それが済んだら、dbtのインクリメンタルモデルのスクリプトに追加する必要があるもう1つの重要なステップがあります:is_incremental()マクロの条件付きブロックです。
is_incremental()マクロは、以下の条件が満たされている場合にTrueを返します:
- 宛先テーブルがデータベースに既に存在する。
- dbtが
full-refreshモードで実行されていない。 - 実行中のモデルが
materialized=’incremental’で設定されている。
モデル内のSQLは、is_incremental()がTrueまたはFalseに評価されるかどうかに関係なく有効である必要があります。
fct_bookingの例に戻りますが、以下は元のクエリです。
上記の増分設定を適用した後、モデルには一意のキー、モデルのタグ、およびis_incremental()マクロの条件ブロックが含まれています。
コードで見るように、unique_keyはbooking_idに設定されており、1つのbooking_idに1つのオーダーが対応しています。
さらに、増分マテリアライズドと統合する他のモデルに対してincremental_modelというモデルタグを追加しました。主な目的は、dbtモデルの増分設定がうまくいかない場合、問題は通常「一括」で発生することです。したがって、他のモデルに影響を与えずにそれらをリフレッシュし、増分モードが有効になっている各モデル名を覚える必要がないため、上記のコードを実行することができます。
dbt run — select tag:incremental_model --full-freshまた、増分モデルが正しく設定されており、本番テーブルのデータを更新する場合は、--full-refreshコマンドを使用してモデルを再実行する必要があります。ただし、フルロードリフレッシュモードで実行すると、増分モードよりも遅くなることに注意してください。したがって、実行する適切な時期を選ぶことを忘れないでください(ヒント:朝の9時には実行しないでください)。
The Slap Back
ここまで、生活は再び良くなりました!テーブルを完璧に設定し、パフォーマンスのクエリが大幅に改善されました。ついに、夜に眠ることができます。手が草に触れ、dbt増分の少しの間違いも見逃さないで、リトル・レアを与えることができました-夢が叶いました。しかし、その後間もなく、財務チームの人が手にレポートを持って私のデスクに突進し、激しく「間違ったデータを与えた!」と主張しました。
増分モデルが1日に多くのオーダーをスキップして次の日に移行してしまったことがわかりました。「なぜこんなことが起こるのだろう?専門のチュートリアルに従ったのに-これは間違いではないはずだ!」と私は頭の中でささやきました。ただし、見落とした可能性のある上流の問題があるようです。調査の結果、問題が明らかになりました。
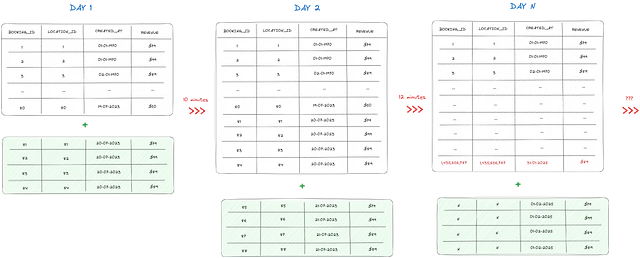
毎日、データの抽出とロードプロセスが真夜中に行われ、その時点までのすべてのデータが同期されます。この同期は通常真夜中に行われますが、開始スピンアップ時間やパッケージキャッシュなどの要因によってタイミングが影響を受けることがあります。重要なのは、プロセスの抽出部分が真夜中よりもわずかに遅れて開始される場合があるということです。
例えば、抽出が午前0時2分に始まり、誰かが午前0時1分ごろに予約をするというシナリオを考えてみましょう。この場合、データにはその日の一部のオーダーも含まれます。これは、技術的な用語で「遅れて到着したデータ」と呼ばれます。
ただし、WHEREフィルタの現在のロジックには欠点があります。フィルタの効率が低下しているのは、created_atの最新の日付値から新しいレコードのみを追加するためです。つまり、1日全体のすべてのデータをキャプチャしないということです。
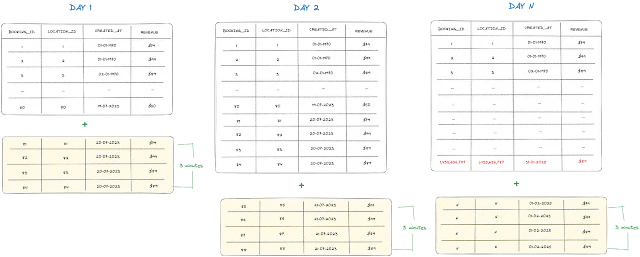
これを修正するために、このロジックを少し変更します。
新しいフィルタでは、過去7日間のすべてのデータを同期します。新しいデータは既存のデータセットに追加され、更新されたフィールド値を持つ古いデータは置き換えられます。
The Tradeoff
これまでに進んできたので、「is_incrementalフィルタを使用して何日前まで戻るべきか?私の場合はなぜ7日間を選んだのか?過去30日間のデータが必要な場合はどうなるのか?」と思っているかもしれません。しかし、答えは一概には言えません-それはあなたの具体的なシナリオによります。
私の場合、毎日少なくとも1つのオーダーがあることを確認しています。過去7日間でデータに内部的な変更がある可能性があるため、その期間内に新しいデータを追加し、既存のデータを更新するためにフィルタを設定しました。ただし、クエリのパフォーマンスに自信があり、過去365日間のデータが必要な場合は、自由に設定することができます!ただし、考慮するべきトレードオフがあることに注意してください。
増分モデルを使用する主な理由は、モデルの実行パフォーマンスにおけるコストを削減することです。ただし、過去7日間のより大きなデータセットをスキャンすると、データのサイズと企業の具体的なユースケースに応じてパフォーマンスが低下する可能性があります。必要に応じて適切なバランスを取ることが重要です。
より一般的なアプローチとして、標準ルールとして7日間を使用することをおすすめします。dbtの増分モデルの完全更新のために、データ更新スケジュールを週次または年次で設定することができます。このアプローチでは、予期しない問題に対応することができます。セットアップがどれほど良くても、時折ダウンタイムが発生する可能性があるためです。
私のユースケースでは、通常、週末に増分ランをフルリフレッシュのためにスケジュールします。この時期は運用タスクが少ないためです。ただし、このスケジュールはチームの要件に合わせてカスタマイズすることができます。
覚えておいてください、重要なのはデータの新鮮さとクエリのパフォーマンスの間の適切なトレードオフを見つけることです。データが正確かつ最新のままで、モデルの効率を最適化することが重要です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「データガバナンスチームを改善するための4つの革命的な方法」
- 「Pandas:データをワンホットエンコードする方法」
- 「データサイエンティスト vs データアナリスト vs データエンジニアー – 違いを解明する」
- Salesforce AIとコロンビア大学の研究者が、DialogStudioを導入しましたこれは、80の対話データセットの統一された多様なコレクションであり、元の情報を保持しています
- 2023年の機械学習研究におけるトップのデータバージョン管理ツール
- 「FathomNetをご紹介します:人工知能と機械学習アルゴリズムを使用して、私たちの海洋とその生物の理解のために視覚データの遅れを処理するためのオープンソースの画像データベース」
- 中国の研究者たちは、データプライバシーを保護しながらスクリーニングを改善するために、フェデレーテッドラーニング(FL)に基づく新しいμXRD画像スクリーニング方法を提案しました
