データウェアハウスとデータレイクとデータマート:どれを選ぶべきか、助けが必要ですか?
データウェアハウスとデータレイクとデータマート:どれを選ぶべき?お悩みの方への助言
データを最大限に活用するには、組織は効率的でスケーラブルなソリューションが必要です。これにより、データを効果的に保存、処理、分析することができます。複数のソースからデータを取り込んで変換し、提供することで、データの保存がデータアーキテクチャの基盤となります。
したがって、データにアクセスする方法や特定のユースケースを考慮しながら、適切なデータ保存ソリューションを選択することが重要です。この記事では、データウェアハウス、データレイク、データマートという3つの人気のあるデータ保存抽象化について探求します。
アクセスパターン、スキーマ、データガバナンス、ユースケースなど、これらのデータ保存抽象化を比較します。
- 機械学習のオープンデータセットを作成中ですか? Hugging Face Hubで共有しましょう!
- ワシントン大学とプリンストン大学の研究者が、事前学習データ検出データセットWIKIMIAと新しい機械学習アプローチMIN-K% PROBを発表しました
- 「分析的に成熟した組織(AMO)の構築」
さあ始めましょう!
データウェアハウス
データウェアハウスは、現代のデータ管理システムの基盤となるコンポーネントであり、分析目的のために構造化データの効率的な保管、整理、検索をサポートするよう設計されています。
データウェアハウスとは?
データウェアハウスは、複数のソースからの構造化および加工済みデータを一元的に保管・管理し、複雑な分析およびレポート作成をサポートするための特殊なデータベースです。
データウェアハウスは、したがって、構造化データの中央集権的なリポジトリであり、組織に次のことを可能にします。
- 複雑なデータ分析を実行する
- レポートとダッシュボードを生成する
- ビジネスインテリジェンス(BI)および意思決定プロセスをサポートする
- 歴史的および現在のデータトレンドに対する洞察を得る
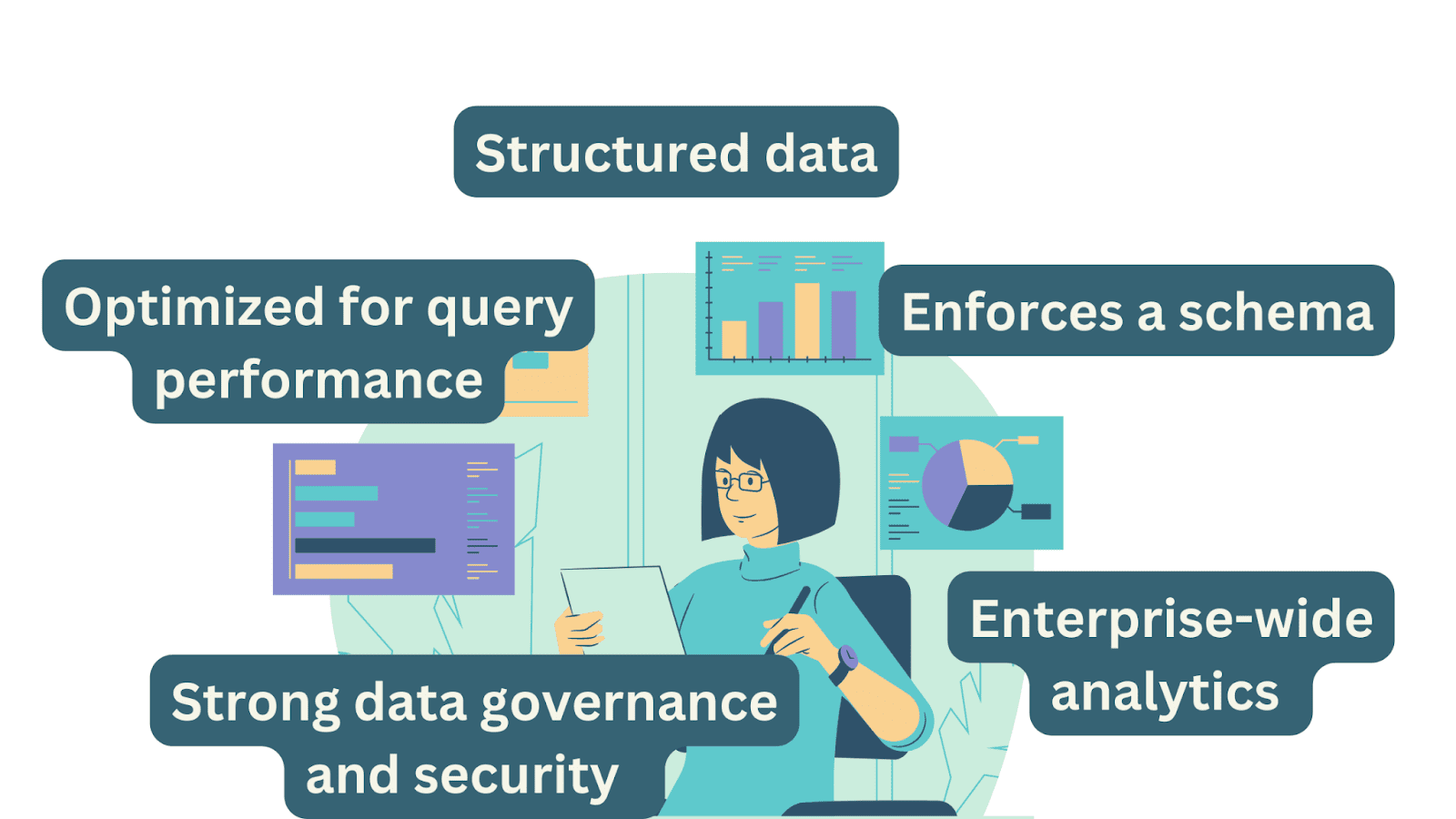
データの種類、アクセスパターン、および利点
データウェアハウスは主に構造化データを保管します。構造化データとは、行と列で明確に定義されたテーブルに整理されたデータのことです。この構造化形式により、データの取得や分析が簡素化され、レポート作成やクエリに適しています。
データウェアハウスは、クエリのパフォーマンスとレポート生成を最適化しています。データの取得を加速するために、インデックスやキャッシュメカニズムを使用することがよくあります。これにより、分析者やビジネスユーザーが必要な情報に迅速にアクセスできます。
データの統合
データウェアハウスは、さまざまなソースシステムからのデータの統合を中央集権化します。これには、ソースシステムからデータを抽出し、一貫性のある形式に変換し、ウェアハウスにロードする作業が含まれます。
データウェアハウスでは、データ統合において一般的にETLプロセスが使用されます。これらのパイプラインは、ソースシステムからデータを抽出し、データをクリーン化および構造化するための変換を適用し、それからデータをウェアハウスのデータベーステーブルにロードします。ETLプロセスにより、データウェアハウス内のデータ品質と一貫性が確保されます。
スキーマ
データウェアハウスでは、データの一貫性のためにスキーマが強制されます。スキーマは、テーブル、列、データ型、関係などのデータの構造を定義します。このスキーマの強制により、データが一貫しており、分析に信頼できるものになります。
データウェアハウスでは、データを組織するためにスターやスノーフレークスキーマがよく使用されます。スタースキーマでは、中央のファクトテーブルにトランザクションデータがあり、それを囲む次元テーブルがコンテキストと属性を提供します。スノーフレークスキーマでは、次元テーブルが正規化されて冗長性が減少します。これらのスキーマの選択は、特定のデータウェアハウジングの要件に依存します。
データガバナンスとセキュリティ
データウェアハウスは、堅牢なガバナンスとセキュリティコントロールで知られています。構造化データに適しており、データの検証、データ品質チェック、アクセス制御、監査能力などの機能を提供します。
ユースケースとビジネスユニット
データウェアハウスは主に企業全体の分析とレポートに使用されます。さまざまなソースからデータを1つのリポジトリに統合し、組織全体での分析とレポートのためにアクセス可能にします。決定者のための標準化されたレポートとアドホッククエリをサポートします。
データレイク
データレイクは、現代の組織の多様なニーズに対応した、柔軟でスケーラブルなデータストレージと管理の手法を表しています。
データレイクとは何ですか?
データレイクは、事前に定義されたスキーマの制約なしで情報を保存して管理するための集中リポジトリであり、大量の生データ、構造化データ、半構造化データ、非構造化データを格納します。
データレイクの主な目的は、さまざまなデータタイプを格納し、管理するための柔軟かつ費用効果の高いソリューションを提供することです:
- データレイクはデータをその生の状態で保持します。
- データレイクは従来の分析から高度な機械学習やAIアプリケーションまで、さまざまなユースケースをサポートします。
- ユーザーはデータの構造やスキーマを事前定義せずに、探索や分析を行うことができます。
データレイクは、現在の組織が生成するデータのボリューム、速度、およびバラエティの増加によって引き起こされる課題に対処するために設計されています。
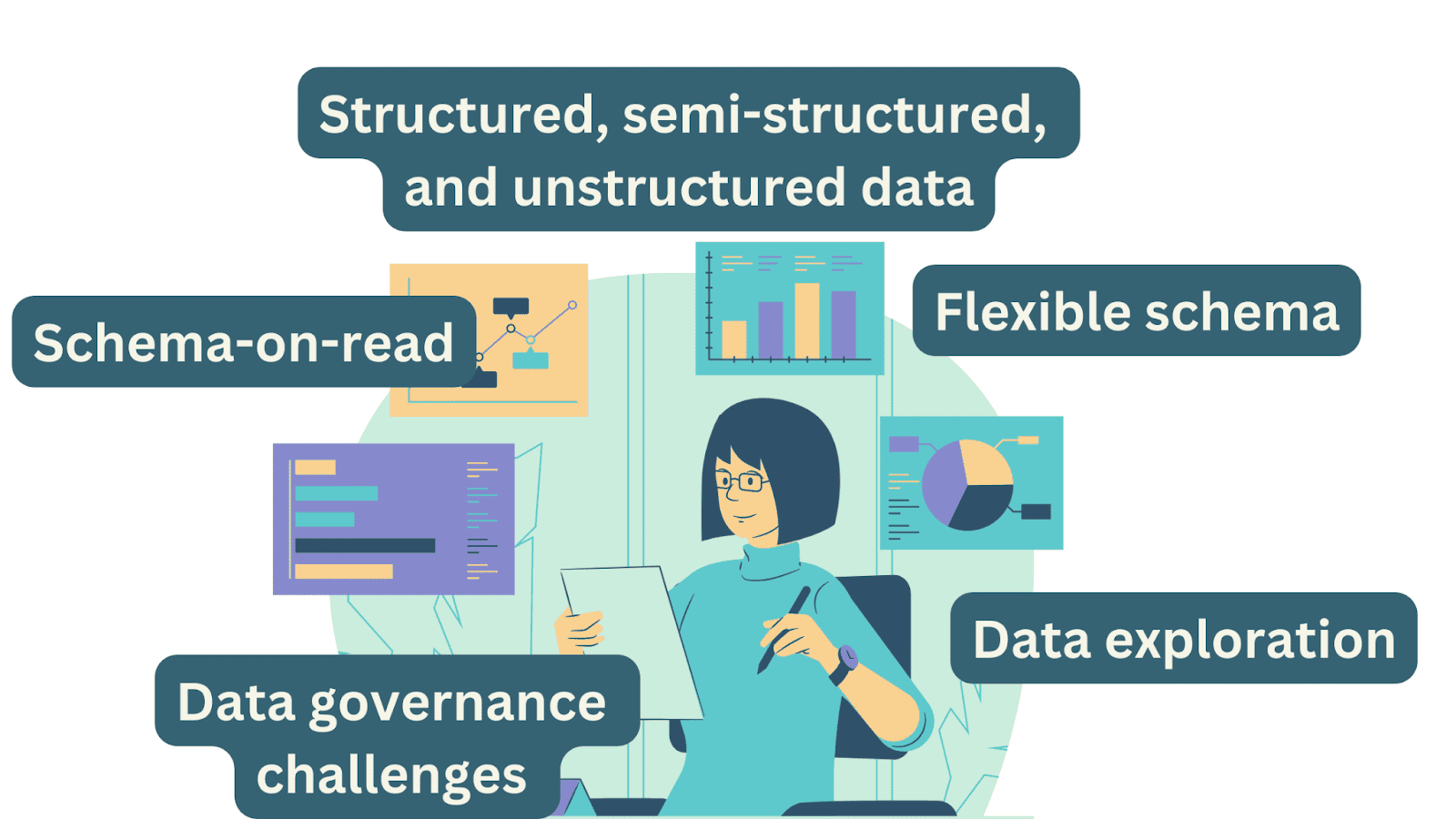
データタイプ、アクセスパターン、および利点
データレイクは、関係データベースからの構造化データ、JSON、XMLなどの半構造化データ、テキストドキュメント、画像、ビデオなどの非構造化データなど、多様なデータタイプを格納することができます。これにより、データレイクは生の状態でデータを処理するのに適しています。
データ統合
データレイクへのデータの取り込みは、バッチまたはリアルタイムのデータ取り込みの両方で行われる場合があります。バッチプロセスでは、定期的に大量のデータをロードしますが、リアルタイムのデータ取り込みではさまざまなソースからのデータが連続的に流れ込みます。この柔軟性により、データレイクはさまざまなデータ速度の要件を処理できます。
データレイクは読み取り時のスキーマアプローチを取っています。データウェアハウスとは異なり、データレイクのデータには事前に定義されたスキーマはありません。代わりに、スキーマは分析時に定義され、ユーザーは自分の特定のニーズに基づいてデータを解釈して構造化することができます。このスキーマの柔軟性は、データレイクの特徴的な特徴です。
スキーマ
データレイクはスキーマの柔軟性を提供し、事前に定義されたスキーマなしでデータを取り込むことができます。この柔軟性により、データの構造が時間の経過とともに変わることを受け入れ、ユーザーは分析に必要なスキーマを必要に応じて定義できます。
データレイクのデータは、分析時に構造と意味が付けられます。このアプローチにより、ユーザーはデータを解釈して構造化し、分析要件に合わせることができます。
データガバナンスとセキュリティ
データレイクはしばしばガバナンスに関する課題に直面します。なぜなら、データレイクは構造化および非構造化のデータをその生の形式で格納するためです。メタデータの管理、データ品質の強制、統一されたデータカタログの維持などが難しくなるため、データの検出とコンプライアンスに関連する問題が発生する可能性があります。
ユースケースとビジネスユニット
データレイクはデータの探索と実験に理想的です。生の非構造化データを大量に保存できるため、データプロフェッショナルが事前に定義されたスキーマなしで探索や実験を行うのに適しています。
データマート
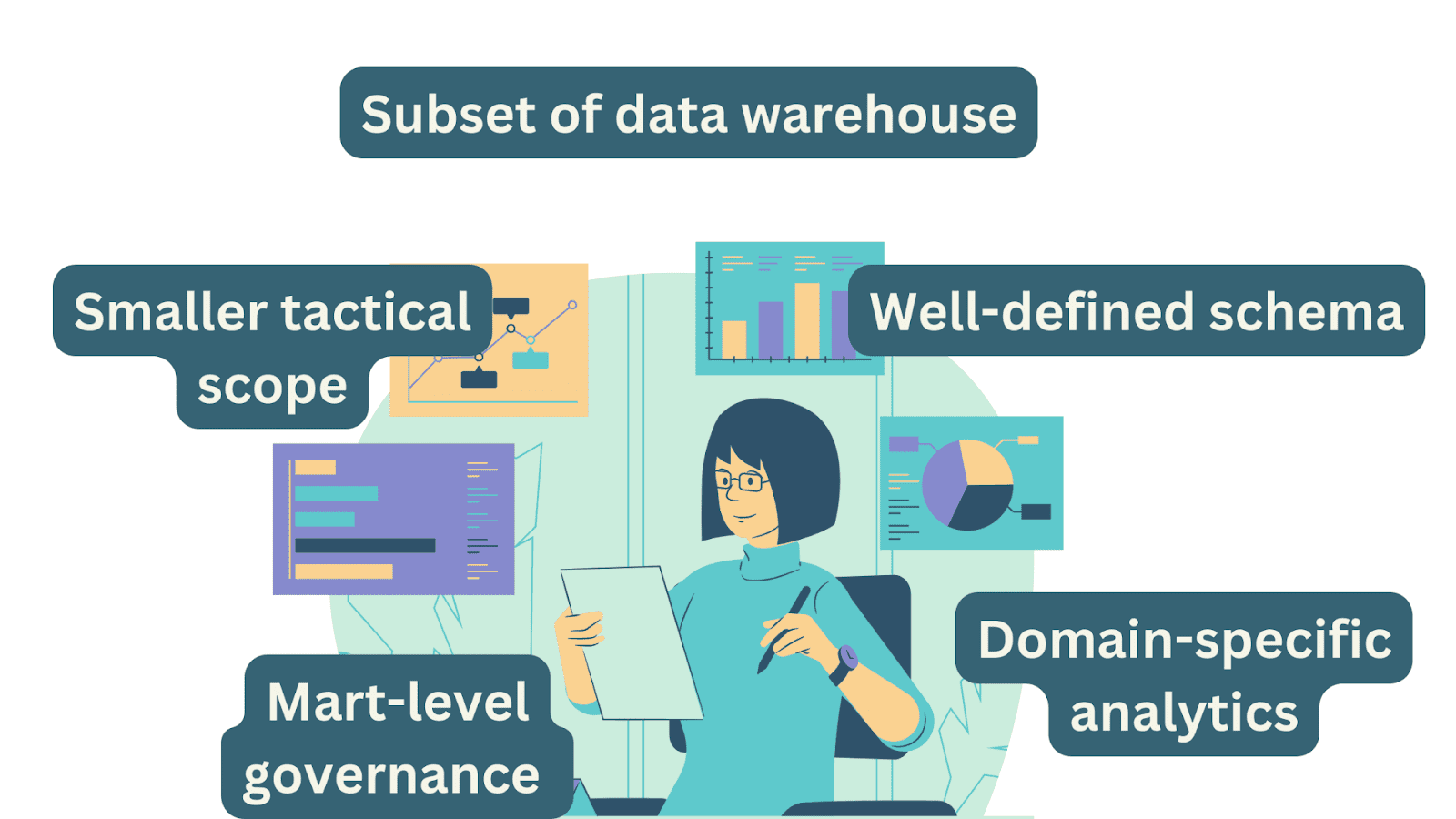
データマートは、組織内の特定のビジネスユニットや機能に対応するエンタープライズデータウェアハウスのサブセットです。
データマートとは何ですか?
データマートは、組織内の特定のビジネスユニット、部門、または機能エリアのニーズに合わせて特化したサブセットのデータウェアハウスまたはデータレイクであり、構造化データを格納します。
データマートの主な目的は、特定の分析およびレポートのニーズに対して、焦点を絞った効率的なデータアクセスを提供することです。主な目標は次のとおりです:
- 特定のビジネスユニットのサポート:データマートは、営業、マーケティング、ファイナンス、または業務など、個別のビジネスユニットの要件に対応するために設計されています。
- データアクセスの簡素化:関連するデータへの容易なアクセスを提供することにより、データマートは特定のドメイン内のユーザーが必要とする情報にアクセスして分析することを容易にします。
- 洞察までの時間短縮:データマートは、処理する必要があるデータの量を減らすことにより、クエリとレポートのパフォーマンスを向上させることができます。
したがって、データマートは組織内のさまざまな部分の意思決定者が関連データにいつでもアクセスできるようにするために重要な役割を果たしています。
データタイプ、アクセスパターン、および利点
データマートは、特定のビジネスユニットまたは機能に関連する構造化データを主に保存します。この構造化形式により、データの一貫性とドメインの分析ニーズに関連性が保たれます。
データマートは、エンタープライズデータウェアハウスやデータレイクに比べて、より焦点を絞ったデータへのアクセスが提供されます。この焦点を絞ったアプローチにより、ユーザーは自分のドメインに直接関連するデータに素早くアクセスして分析することができます。
データ統合
データマートは通常、データウェアハウスなどの中央リポジトリからデータを抽出します。この抽出プロセスでは、特定のビジネスユニットまたは機能に関連するデータを特定し選択します。
抽出されたデータは、マートのニーズに合わせて特定の変換が行われます。これには、データのクレンジング、集計、またはカスタマイズなどが含まれます。これにより、データはドメインの分析要件に合わせたものとなります。
スキーマ
データマートは、中央データウェアハウスで定義されたスキーマに従う場合と、特定のマートの分析ニーズに合わせてカスタムスキーマを使用する場合があります。選択は、データの一貫性とマートの自律性などの要素によって異なります。
データガバナンスとセキュリティ
データマートは通常、特定のビジネスドメインやユニットに焦点を当てたデータウェアハウスのサブセットです。ガバナンスの取り組みは主にマートレベルで行われ、特定のビジネスユニットがデータウェアハウスによって設定されたエンタープライズ全体のガバナンス基準に準拠していることを保証します。
ユースケースとビジネスユニット
データマートは、組織内のビジネスユニットやドメインの具体的なニーズに合わせて作成されます。これは、特定のビジネス領域に関連するデータウェアハウスからのデータのサブセットを提供します。これにより、ビジネスユニットは、企業全体のデータセットを処理する複雑さなしに、専門の分析とレポートを実行することができます。
データウェアハウス vs. データレイク vs. データマート:包括的な比較
データウェアハウス、データレイク、およびデータマートの主な違いをまとめましょう:
| 特徴 | データウェアハウス | データレイク | データマート |
| データの種類と柔軟性 | 構造化データ、固定スキーマ | さまざまなデータタイプ、スキーマの柔軟性 | 構造化データ、明確に定義されたスキーマ |
| データ統合 | ETLパイプライン | 柔軟なデータ取り込み、スキーマの読み取り時 | ドメインのための抽出と変換 |
| クエリパフォーマンス | クエリに最適化 | パフォーマンスは異なる | 最適なパフォーマンス |
| データガバナンス | 堅固なデータガバナンスとセキュリティコントロール | データガバナンスの課題 | マートレベルのガバナンス |
| ユースケース | 企業向け分析 | 膨大なデータの探索 | 特定ドメインの分析 |
結論
データウェアハウス、データレイク、そしてマートの概要を理解していただけたことを願っています。アーキテクチャの選択は、組織の特定の要件とデータおよびビジネスニーズに対するガバナンスと柔軟性のバランスに依存します:
- データウェアハウスは、厳格なガバナンスとセキュリティコントロールがあり、企業全体の分析とレポート作成に適しています。
- データレイクは、データの探索とビッグデータ分析に適していますが、ガバナンスとセキュリティに課題を抱えることがあります。
- データマートは、データウェアハウスのガバナンス基準に準拠しつつ、ビジネスユニットのニーズに合わせた特定のドメイン向けの分析を提供します。
また、最近の進化しているアーキテクチャであるデータレイクハウスを探索することもできます。データレイクハウスは、データウェアハウスとデータレイクの間のギャップを埋めることを目指し、データのストレージと分析の統一アプローチを提供します。
[Bala Priya C](https://twitter.com/balawc27)は、インドの開発者兼テクニカルライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での仕事が好きです。彼女の関心と専門知識の領域には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、そしてコーヒーが好きです!現在、彼女はチュートリアル、ハウツーガイド、意見記事などの執筆を通じて、開発者コミュニティとの知識共有と学習を目指して取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
