「データの成熟度ピラミッド:レポートから先進的なインテリジェントデータプラットフォームへ」
Data Maturity Pyramid From Reports to Advanced Intelligent Data Platforms
今日、組織は競争力を得るために情報に基づいた意思決定とデータに頼っています。データドリブンの組織になるためには、データ能力を進歩的に向上させ、AIとMLの技術を活用し、堅牢なデータガバナンスの実践を採用するという数多くのステップが必要です。
この記事では、報告とデータガバナンスからAI/MLの基盤となるデータ製品、そして積極的なインテリジェントデータプラットフォーム(PIDP)へと詳細に探求します。また、この旅におけるデータエンジニアの役割も掘り下げています。
企業環境におけるデータの成熟度
- 「大規模な言語モデルは本当に複雑な構造化データを生成するのに優れているのか?このAI論文では、Struc-Benchを紹介し、LLMの能力を評価し、構造に注意したFine-Tuningの解決策を提案します」
- 「BComを修了後、どのようにデータサイエンティストになるか?」
- 「AIコントロールを手にして、サイバーセキュリティシステムに挑戦しましょう」
企業環境では、データの成熟度の複数の階層を区別することができ、それは企業がデータ資産を利用する進歩の度合いを示しています。この文脈では、データの成熟度モデルという概念が自然に浮かび上がり、異なるレイヤーからなる階層的なピラミッドとして構成されます。さらに、より高いデータの成熟度への旅は、より高度なレベルに到達するだけでなく、既に達成された能力を洗練させ、最適化するための継続的な改善のサイクルです。
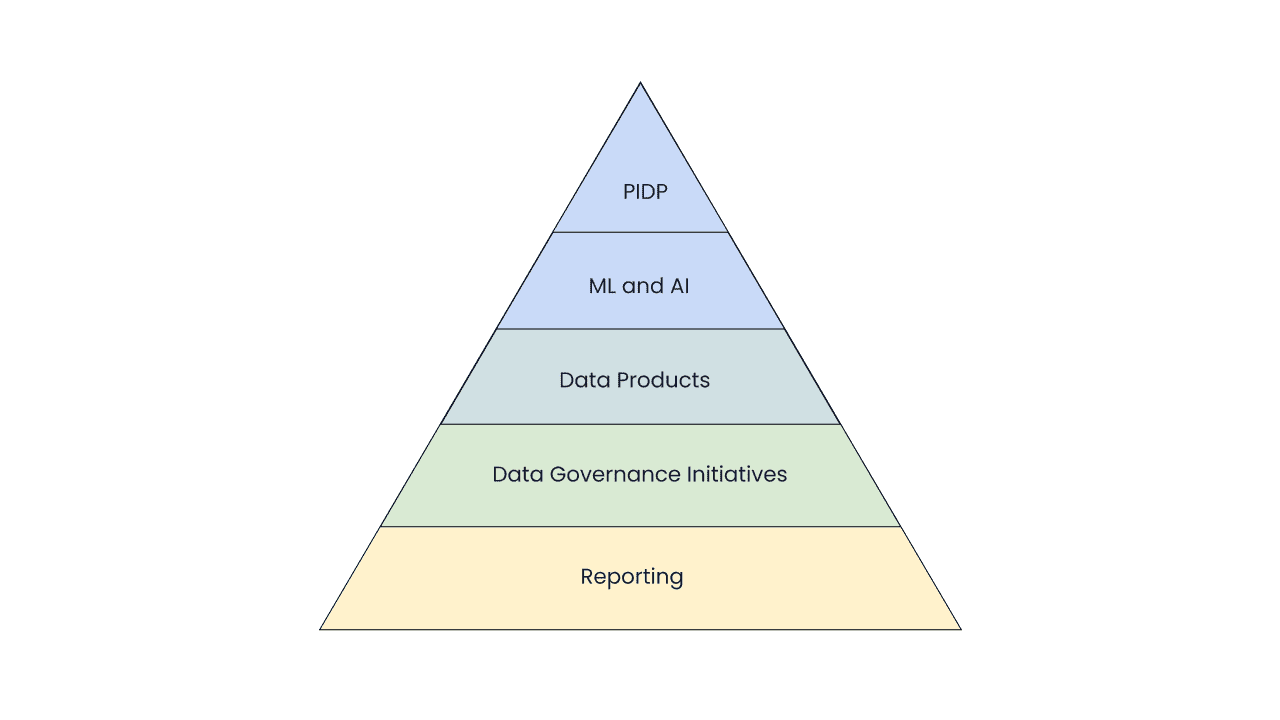
ピラミッドを使用することで、2つの特徴を同時に示すことができます:
- 次のレベルは前のレベルの上に配置されること。
- 次のレベルの拡大は、それ以下のレベルの拡大を必然的にもたらすこと。
これはつまり、組織内でデータ製品が進化するにつれて、データ管理のアプローチと技術も改善されていくということです。信頼性、探索性、セキュリティ、一貫性などのデータの特性は段階的に改善されるため、各レベルでの改善がもたらされます。
次に、AIとMLを導入し実装する過程での企業のシナリオを説明しましょう。
様々なソースからの企業データを深く理解している通信会社があるとします。
- 信頼性のある一貫した企業レベルの報告を維持しています。
- リアルタイムデータに依存するマーケティングキャンペーン管理システムを使用しています。
この会社は、顧客に最適な次のプランを提供するために、高度なAI/ML駆動のシステムを導入することを決定します。この動きにより、データの活用の新しいレベルが解放され、ピラミッドの以前のすべてのレベルが改善されます:報告のための新鮮なデータが導入され、データのセキュリティとコンプライアンスに関する新たな課題が生じ、マーケティングに対する貴重な洞察が提供されます。
データの取り組みは必ずしも下から上に始まる必要はありません。組織があるレベルで十分に熟達すると、次のレベルに進むことができます。ただし、ピラミッドの一部のレベルは、まったく異なるデータ変換の段階にある場合があります。たとえば、ビジネスの観点から最も大きな機会に見えるAIの領域でデータ変換を開始することを組織が決定するかもしれません。
組織がAIとMLを使用して、列車やバスの乗り換え、その他の旅の詳細を考慮して最も安価な航空券を迅速に見つけることを目指すとします。このケースを解決するには、比較的具体的かつ限られたデータセットが必要です。ただし、組織の報告やデータ管理のレベルは、既存のデータでこの機能をサポートするのに十分に進化していないかもしれません。この場合、データピラミッドではなく、AI/MLのレベルが浮遊しているということになります。分析システムを「浮遊」させることは非常に困難ですが、市場投入までの時間を短縮し、特定のAIユースケースを迅速にテストする手段として可能です。基盤となるピラミッドのレベルの高度な開発はおそらく遅れるでしょうが、システムは最終的に持続可能なピラミッド形態を獲得します。
データ駆動の能力と競争上の優位性
データの成熟度を向上させる利点について話す際、改善すればするほど報酬も大きくなることを注目することが重要です。簡単に言えば、現在のデータの成熟度レベルが高ければ高いほど、次の小さな改善から得られる価値も大きくなります。このような利益の急速な成長は、「指数関数」として説明されるものであり、成長率は現在の状態に関連しています。
この関係は分析システムでは簡単に気づくことができます。それぞれのレベルは前のレベルに基づいて構築することができ、同時に以前の段階では利用できなかった全く新しい利点や機能を解放します。 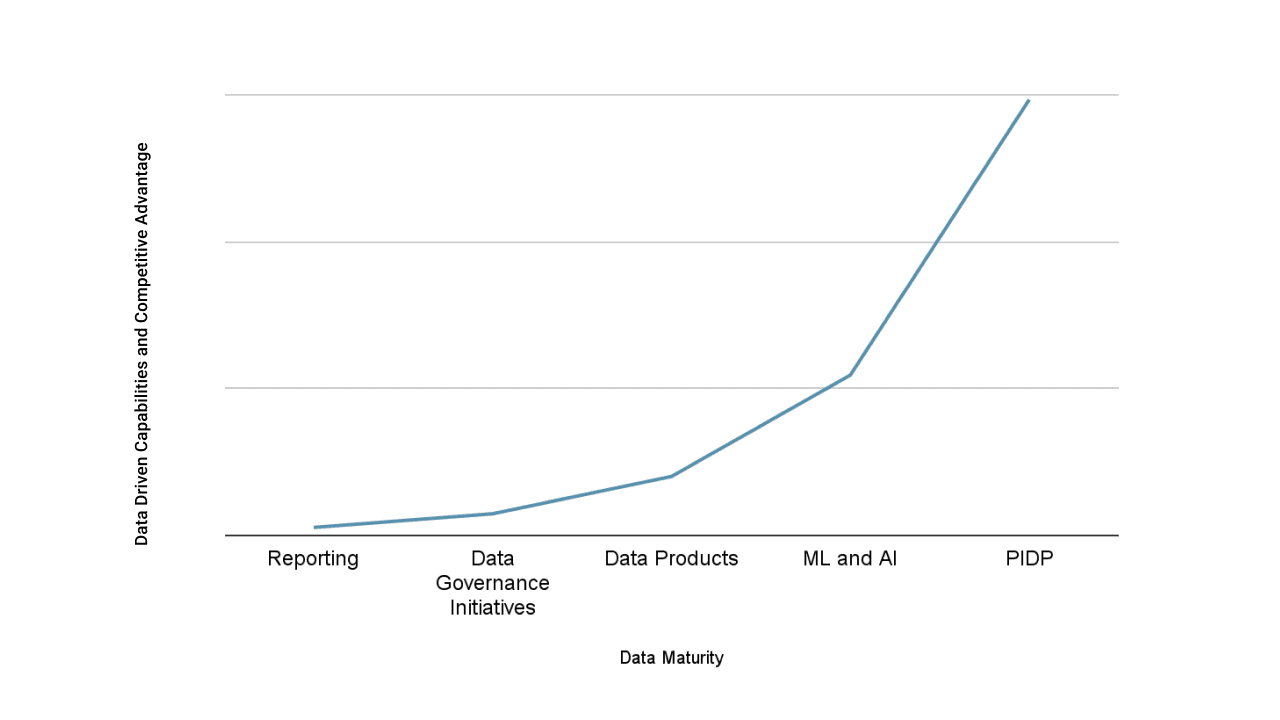
これがどのように機能するかを示すために、組織が新しいデータ製品、つまり電子商取引プラットフォーム向けの顧客推奨エンジンを開発したと仮定しましょう。このエンジンは、過去の顧客の行動データを処理してユーザーに個別の製品の推奨を提案します。最初の段階では、システムはルールベースであり、事前に定義されたヒューリスティックを使用して推奨を行います。
AI / MLレベルへの移行では、チームは機械学習モデルを実装することを決定します。例えば、協調フィルタリングモデルや深層学習ベースの推奨システムなどです。モデルは大量のデータを分析し、データ内の複雑なパターンを特定し、すべてのユーザーに対して正確で個別の製品の推奨を行うことができます。
推奨システムが展開されると、ユーザーの相互作用からさらに多くのデータを収集し続けます。ユーザーがプラットフォームと推奨を利用するほど、システムが蓄積するデータ量も増加します。このデータの成長により、MLモデルは継続的に学習し、推奨を洗練させることができます。これにより、推奨エンジンの正確性と効果がますます向上します。
注: これらの各移行については後で詳しく説明します。この段階では、新しい成熟度レベルへの移行はシステムの複雑さの全体的な成長と関連していることを念頭に置いておきましょう。この成長は、新しいツールの使用、新しいチームのスキルの獲得、システムとチームの間の追加の接続の構築(サイロを避けながら)などを意味します。そして、最も重要なことは競争上の優位性を獲得することです。あなたの組織は各レベルでより多くの利益を得る一方、競合他社は遅れを取ることになります。
複雑なシステムは単純なシステムよりも開発が困難です。さらに、すべての企業がアイデア出しから実装、スケールでの採用、サポートまでの開発プロセスを管理するためのリソースを持っているわけではありません。
例えば、需要の予測、在庫の最適化、物流の非効率性の特定にいくつかの機械学習モデルを実装している供給チェーン管理会社を想像してみてください。高度な分析と予測洞察を活用するこのようなデータ駆動型のソリューションは、大きな競争上の優位性です。
さて、この会社はジェネレーティブAIの機能を備えたプロアクティブインテリジェントデータプラットフォーム(PIDP)に向けてさらなる進歩を遂げたいと考えているとしましょう。このようなシステムは、データからリスクと機会を特定することから、Large Language Models(LLMs)を使用してこのデータに基づいたアクションプランを積極的に生成するまで進化します。今では、潜在的な問題についてステークホルダーに通知するだけでなく、インテリジェントかつ緻密に作成されたアクションプランを提供します。ジェネレーティブAIは、プロセスを開始し、内部またはサードパーティのAPIを呼び出し、生成された計画を自律的に実行するために活用することができます。
供給チェーン管理システムの場合、この移行により、在庫の不足だけでなく、サプライヤーと積極的に連携し、発注を行い、物流を調整することも可能になります。すべての操作はリアルタイムで人間の介入なしに行われます。このようなシステムは結果を評価し、それから学び、次のアクションを洗練させることができます。人間のフィードバックは重要であり、戦略的ゴールに合わせて連携し、継続的な改善を確保します。
ジェネレーティブAIをプロアクティブインテリジェントデータプラットフォームに組み込むことは、単なる技術的な飛躍にとどまらず、戦略的な変革でもあります。供給チェーンの領域では、これによりリードタイムの短縮、在庫切れの最小化、資産の最大利用が実現され、実際のビジネス価値につながります。
競合他社がルールベースのシステムや従来の機械学習アルゴリズムに苦しんでいる間、PIDPレベルで運営している企業は、現代の供給チェーンの複雑さに対して機敏さと先見性を持って対処しています。
データピラミッドの各レベルを詳しく探って、報告からPIDPへの旅での役割を理解しましょう。
レベル1 – 報告
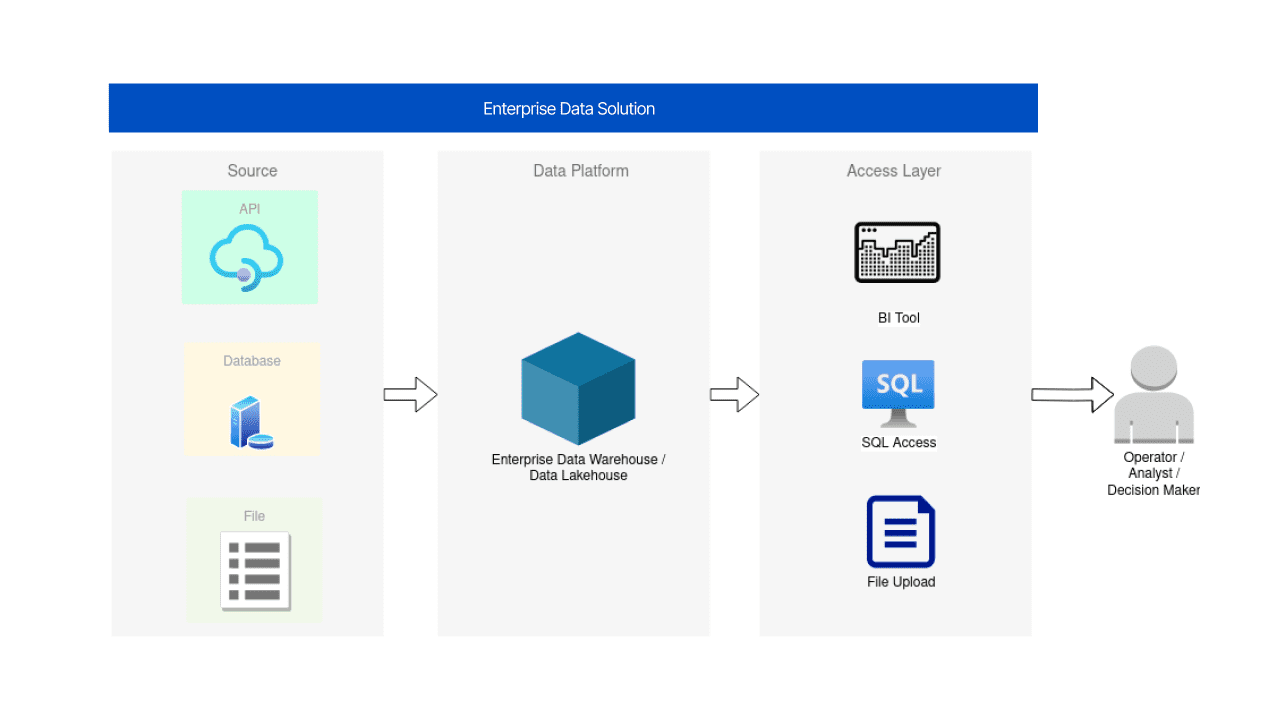
報告はデータエンジニアにとって重要なドメインです。これには、分析や他のデータ駆動型のサブシステムやソリューションの基盤となる基本的なデータプラットフォームの設計と構築が含まれます。データエンジニアは、頑強なデータパイプラインとインフラストラクチャを確立し、データを効率的かつ安全に収集、保存、処理できるようにする責任があります。これらの基礎となるデータプラットフォームは、データエンジニアがビジネスに対してデータが容易にアクセス可能で、整理され、さらなる分析や報告のために準備されていることを保証するのに役立ちます。
歴史的な文脈を考えると、5年前まで、リアルタイムツールの使用はバッチプラットフォームと比較してより成熟したデータプラットフォームを示していました。今日では、いくつかの例外を除いて、境界線はより曖昧になっています。バッチ処理とストリーミング処理の複雑さはほとんど変わりません。唯一の例外はデータの系譜、セキュリティ、およびディスカバリーであり、一般的にはデータガバナンスと呼ばれるものです。これらの領域では、リアルタイム処理によって多くの変化が起きており、今後さらなる改善が期待されています。
そうは言っても、ほとんどのソースからほぼリアルタイムのデータ統合を実現することが可能であり、イベントゲートウェイは一貫したデータ取り込みに適した選択肢です。組織内の他のデータソースよりも著しく大量のデータを持つ一部のデータソースについては、バッチ取り込みが好まれる場合もあります。たとえば、VoAGIサイズのオンライン企業のGoogle Analyticsからの生データは、すべての処理済みデータの半分を占めるかもしれません。このデータをトランザクションシステムのデータと同じ速度で取り込むことが、高いコストを伴う可能性があるかどうかは議論の余地があります。ただし、技術の進歩に伴い、バッチとリアルタイムの選択肢の間で選択する必要性は減るかもしれません。
リアルタイムのデータ製品では、バッチ処理と比較してデータガバナンスの機能とメンテナンスのオーバーヘッドにはまだ大きな差があります。そのため、データの新鮮さがデータの品質よりも重要な広告入札や不正検出などの一部のユースケースにおいてのみ、リアルタイムのデータ処理に頼ることをおすすめします。
一部の製品は、速度よりも透明性と品質のレベルの向上によってより多くの利益を得ることができます。これらの製品は、マイクロバッチでのデータ処理や伝統的なバッチモード(たとえば、財務報告)に依存することができます。詳細については、LinkedInのDan Taylorの記事をお読みください。
レベル2 – データガバナンスイニシアチブ
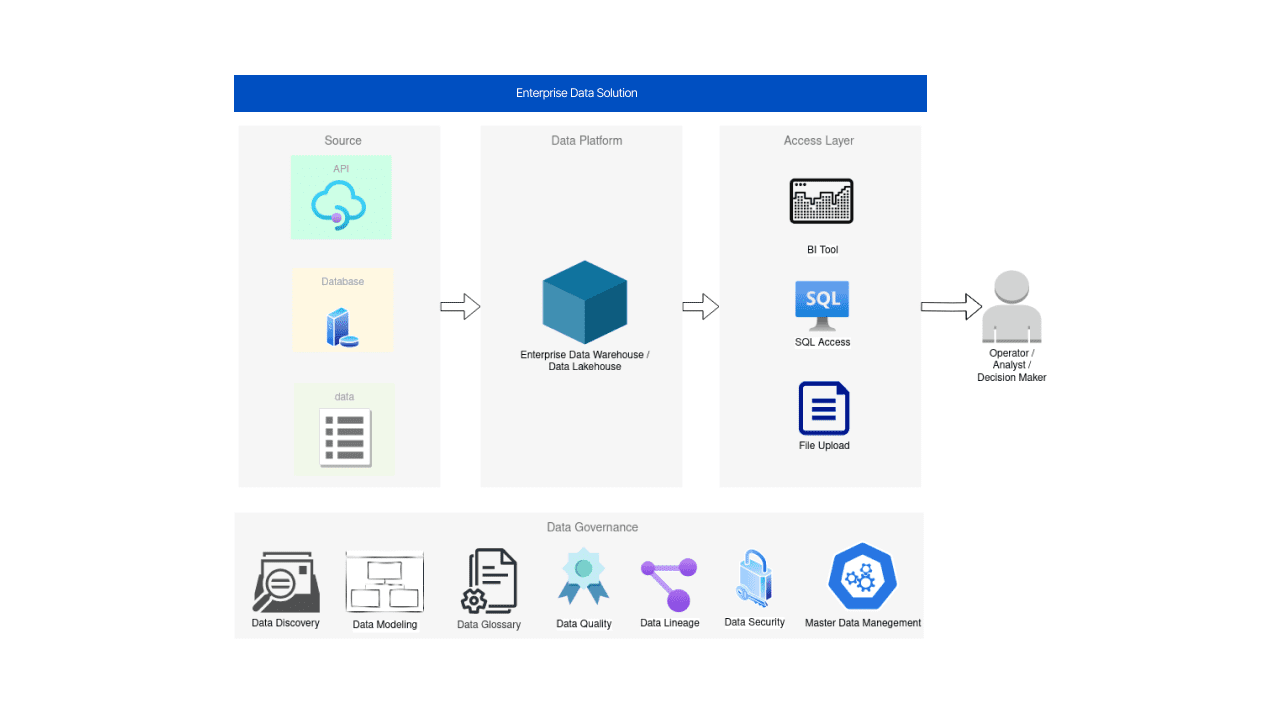
データガバナンスは広範な用語であり、定義もさまざまです。しかし、データガバナンスイニシアチブとは、データの発見、データモデリング、データ用語集、データ品質、データ系統、データセキュリティ、マスターデータ管理(MDM)などの構成要素、特徴、および慣行を指すことになります。
データガバナンスの意識的かつ体系的な実践への移行は、データリテラシー、スピード、信頼性、セキュリティの驚異的な向上をもたらす可能性があります。これらは、簡単なレポートから企業のデータ管理システムへの移行によって実現される利点の一部に過ぎません。
データ民主化の需要は、より効率的なデータアクセス管理の要件を必然的に増加させます。会社レベルでの指標の統一により、用語集の作成、統一されたレポートの作成、データの断片化と重複の管理などが必要になります。そのようなデータソリューションと製品は、データの発見可能性、より詳細なカタログ化、およびデータの使用法の需要を推進します。
データガバナンスのレベルでは、データエンジニアは通常、ソフトウェア開発チームと密接に連携して、参照データ管理ツールなどのシステムを構築および維持します。データの可観測性インストルメンテーション(OpenLineageなど)についても同様です。理想的には、あらゆるタイプのデータガバナンスイニシアチブに統一されたプラットフォームである、Open Data Discoveryプラットフォームの目指すところです。
レベル3 – データ製品
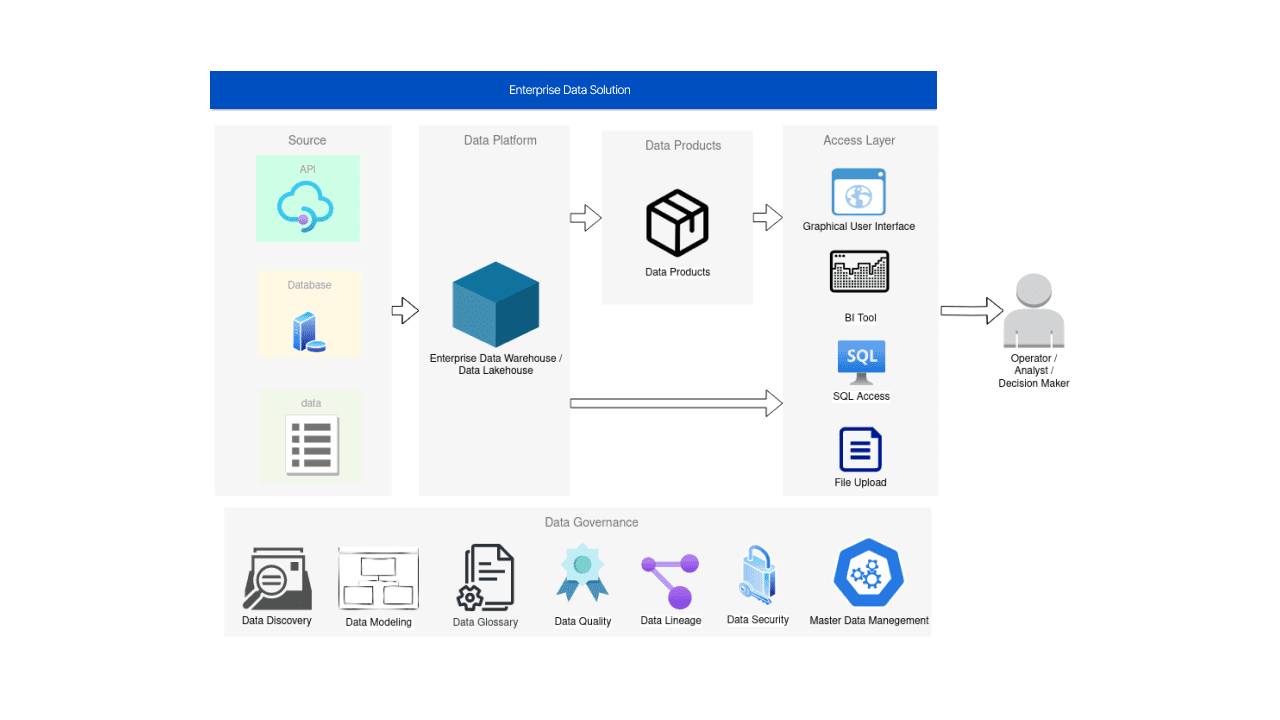
基本的なデータ製品は、AI/MLの技術やユースケースに関連付けられていません。また、高度な分析も必要ありません。なぜなら、企業のデータプラットフォームに格納されている統合されたデータだけで広範な問題やタスクを解決できるからです。以下が該当します。
- 過去のデータを用いたほぼすべての操作
- データのロードを削除することによって実現されるトランザクションシステムのサポート
- 大量のデータに対する高速かつスケーラブルな計算
より具体的な例としては、営業&マーケティングシステム、A/Bテスト、課金システムなどで使用されるシステムやツールがあります。
データ製品の段階では、ソフトウェアおよびアプリケーション開発チームも重要な役割を果たします。ビジネスの目標を念頭に置きながら、データ製品の技術的な側面について彼らとのコミュニケーションを行うことが成功するための鍵となります。
データのAPIやエンドツーエンドのソリューションの開発は、常に企業の開発の一般的なアプローチの一部であるべきです。クロスファンクショナルな開発チームが最も利益をもたらし、データに関しては、データメッシュという概念について話すことが意味があります。
データメッシュは、組織がデータを管理する方法を革新します。データを単一のエンティティとして見るのではなく、データメッシュは組織にデータを製品として扱うよう奨励します。これにより、データの所有権を分散化し、各チームが独自のデータ製品を開発および維持できるようにし、集中型のデータチームへの依存とボトルネックを減らすことができます。
レベル4 – AIとMLソリューション
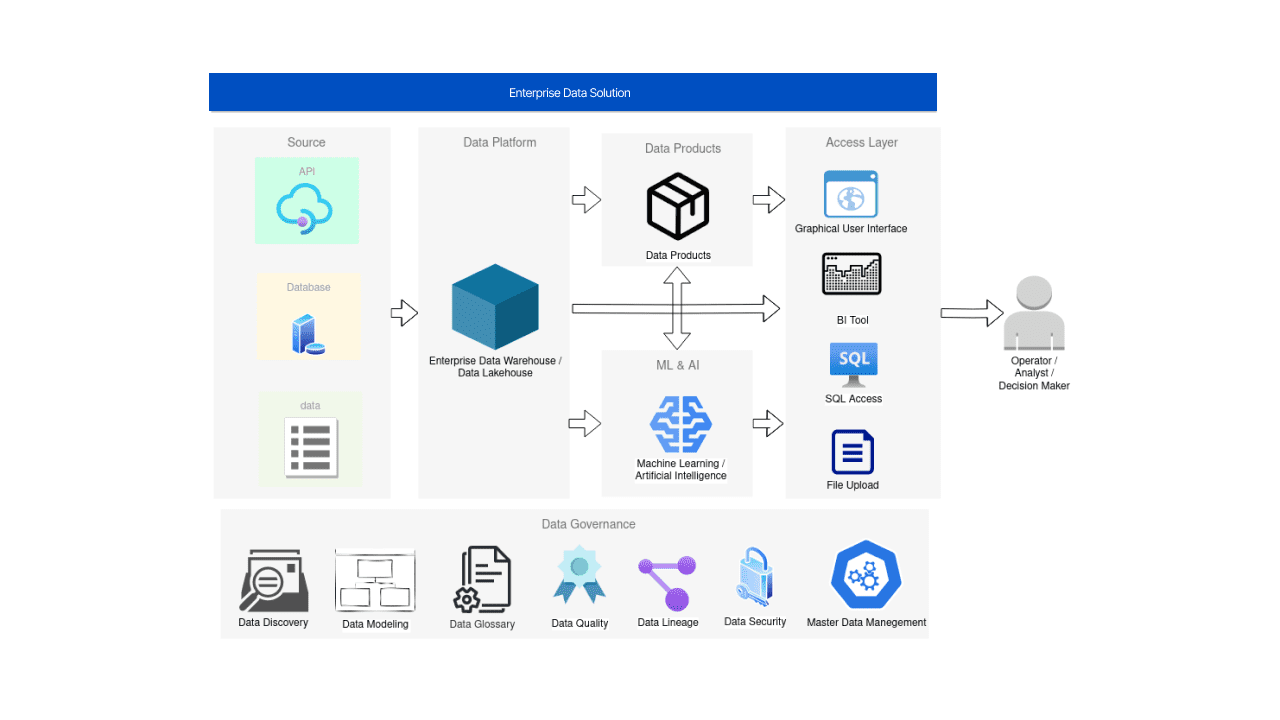
AIは新しい電力です。しかし、私たちはまだ中間期にいます。AIのポテンシャルは明確ですが、まだ多くの企業がビジネスモデルを見直し、AIを最大限に活用するまでには至っていません。
Stephen Brobst氏のスピーチで完璧に述べられているように、AIの主な価値はAIが普及しているときに実現されます。これまで、最終的な利益を得る人々は普及の要素に注意を払っておらず、現実世界に持ち込めないユースケースに取り組むことがよくあります。
データエンジニアリングの観点から見ると、AIはデータによって駆動されます。そのため、私たちは常にフィーチャーストアとMLモデルの運用化について思い出すべきです。これらのコンポーネントは、データをAI/MLソリューションに連続的かつ繰り返し変換するのに役立つものです。詳細については、Databricksの「The Big Book of MLOps」でこれらのコンポーネントと関連する役割が説明されています。この包括的なガイドは、5つの主要な役割(データエンジニア、データサイエンティスト、MLエンジニア、ビジネスステークホルダー、データガバナンスオフィサー)の具体的な機能と、データの前処理、探索的データ分析(EDA)、特徴エンジニアリング、モデルトレーニング、モデルの検証、デプロイメント、モニタリングという7つの重要なプロセスを概説しています。
また、AIの真のポテンシャルは、そのモジュールが企業全体のインフラストラクチャ、プロセス、さらには文化に統合されたときに完全に発揮されます。さまざまなシステムと個人がシームレスに協力して一体となるとき、Proactive Intelligent Data Platformへの移行が組織全体で意味を持つようになります。
レベル5 – Proactive Intelligent Data Platform(PIDP)
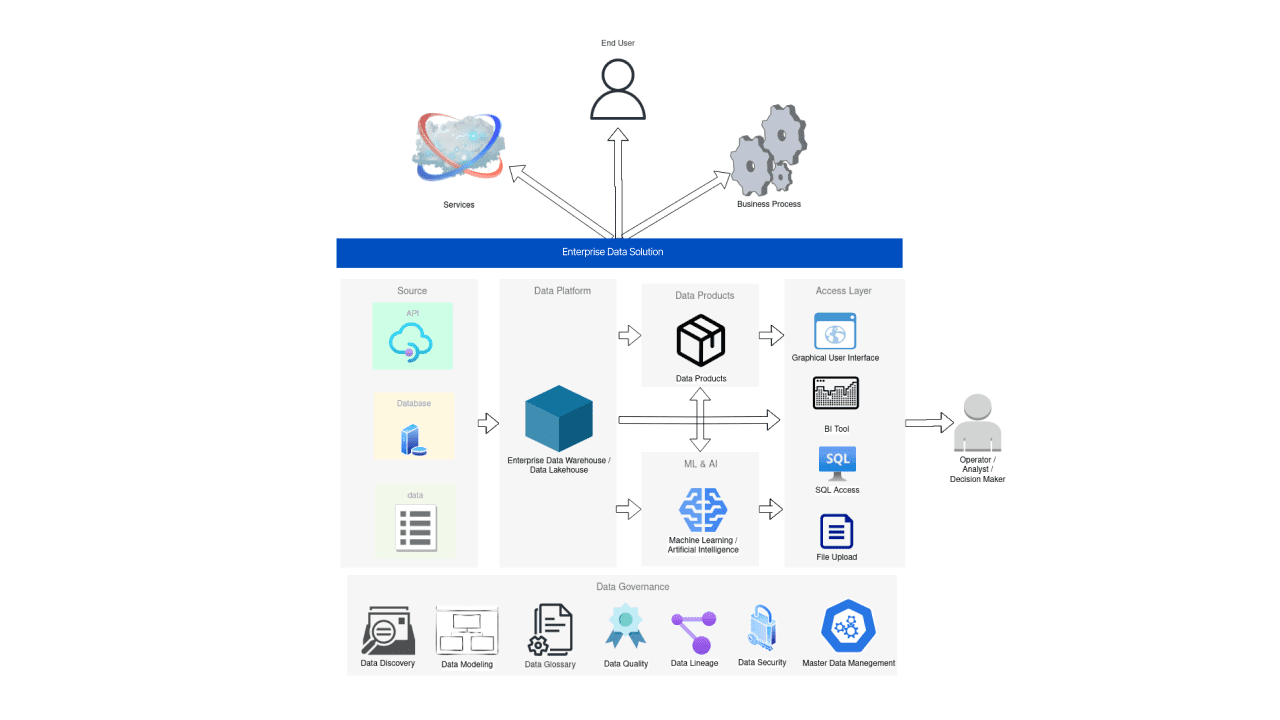
Proactive Intelligent Data Platform(PIDP)は、データ成熟度ピラミッドの最上位レベルです。その核心は、AI/ML技術と高度な分析をビジネスアズユーズアル(BAU)プロセス全体にシームレスに統合することです。
PIDPを最近登場したAIのニッチである生成AIの文脈で詳しく見てみましょう。具体的には、デジタルツイン、コントロールタワー、コマンドセンターという3つのドメインを探求します。これらのドメインにおいて、生成AIの変革的な潜在能力が最も明白です。
例えば、大規模な工場では設備のデジタルツインを開発して運用効率を向上させています。このような高度なセットアップでは、オペレーターはすべての重要な制御を持っているにもかかわらず、継続的な意思決定という非常に困難な課題に直面しています。自然言語でデジタルツインとコミュニケーションを取ることができる生成AIエージェントを導入することで、日常のタスク、リスク評価、機会分析の自動化や意思決定のサポートが行われます。
同様に、通信業界のコントロールタワーは、世界中のオペレーターが最適化、タイムリーな問題検出、事故予防に投資するという最新のトレンドに適しています。これらのセンターはさまざまな権限レベルから膨大なデータを受け取ります。人間のオペレーターは効果的なタスク管理のために高度なスキルと情報を持つ責任を負っています。生成AIを組み込むことで、彼らの業務のルーチンや複雑な側面を軽減することができます。
さらに、サプライチェーン部門内のコマンドセンターを考えてみてください。ここでは、サプライチェーンユニット、財務部門、法務部門など、部門間の多角的な協力がしばしば必要とされる運用上の決定が行われます。これらのチームは、異なる専門知識と一部の洞察を持っており、共同で行動を決定する必要があります。この文脈では、生成AIの企業全体の統合管理プラットフォームの一部としての有用性が明確になります。これらのGen AIモデルはリスクや機会を特定し、それらの企業全体への影響を評価し、潜在的な解決策を分析するなど、さまざまなことができます。
データはこれらのドメインのそれぞれで重要な役割を果たしています。それは、時計のようにスムーズに動作するために、組織全体を巻きつける冠です。
PIDPは、組織が積極的に課題に対応し、データに基づいた意思決定を行い、競争の先を行くことを可能にする強力なツールです。
このステージでは、データエンジニアの役割が最も重要であり、同時にあまり目立たないかもしれません。企業は既にデータ駆動型の製品から主な利益を得ているため、シンプルな分析ダッシュボードから企業のさまざまな部門間の協調した相互作用まで、意思決定プロセスにAIをシームレスに統合することが重要です。組織は、データによって駆動される生活必需品から、非専門的で非技術的な環境でスムーズにビジネス価値を生み出すことができる使いやすいアプリケーションへと進化していきます。
ただし、ほとんどのノードにおいてリンクはデータ、その管理および処理であることを理解することが重要です。もちろん、これはデータエンジニアの仕事の主な長所です。
結論
積極的なインテリジェントデータプラットフォームへの道のりは、データおよびAIによる世界で成功を目指す現代の組織にとって困難ですが、重要です。さまざまなデータの成熟度レベルを進化しながら、データ駆動型の能力を受け入れ、堅牢なデータガバナンスの取り組みを確立し、AIとMLのポテンシャルを活用することで、組織はさまざまな重要な競争上の優位性を解き放つことができ、常に先を行くことができます。
積極的なインテリジェントデータプラットフォームは、この旅の集大成であり、データの成熟度ピラミッドの最終レベルです。これにより、組織は急速に変化するビジネスの景色でリードし、革新し、成功することができます。 Raman Damayeuは、従来のデータウェアハウジングと最新のクラウドソリューションの両方に精通しています。一流のデータガバナンスの熱心な支持者であるRamanは、オープンデータの探索に似たプラットフォームに特別な親近感を抱いています。Provectus内で彼は常にデータ駆動型のイニシアチブを前進させ、業界を次のデータ処理のレベルに引き上げるお手伝いをしています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
