「DAE Talking 高忠実度音声駆動の話し相手生成における拡散オートエンコーダー」
DAE Talking Diffusion Autoencoder in High-Fidelity Speech-Driven Conversation Generation
拡散モデル + 大量のデータ = 実質的に完璧なトーキングヘッド生成
今日は新しい論文と、私が見てきた中で最も高品質な音声駆動のディープフェイクモデルについて話します。Microsoft ResearchからのDAE-talkerは、Diffusion Auto-Encoder(DAE)をベースにした個人特定のフルヘッドモデルです。モデルは単一のデータセットでしか表示されていませんが、その結果は非常に印象的です。
DAE-talkerプロジェクトページ(https://daetalker.github.io/)からのデモビデオ。
この論文の成功の鍵は2つあります。まず、ランドマークや3DMM係数などの手作業の特徴に依存しないことです。特に3DMMは個人特定のモデルに非常に役立つものの、制約があり、思い通りに表現力を持っていません。ただし、著者たちは、ポーズモデリングを使用することで、ポーズを他の属性から分離する利点を依然として活用することができます。このモデルの成功の第二の理由は、拡散モデルの使用です。拡散モデルは、Stable Diffusionなどのモデルの駆動力であり、「生成AI」を一般化させてきました。
拡散オートエンコーダ
拡散モデルは、優れた多様性を持つ超高品質の画像を生成する能力でよく知られています。これらのモデルは、画像と同じ形状のノイズの潜在ベクトルを使用し、複数のステップでそれらを除去します。ただし、拡散モデルのよく知られた制限の1つは、潜在ベクトルに意味をもたせることができないということです。GANやVAE(拡散モデルの通常の競合モデル)では、潜在空間での編集が出力画像に予測可能な変化をもたらすことが可能です。一方、拡散モデルにはこの品質がありません。拡散オートエンコーダは、代わりに2つの潜在ベクトル、セマンティックコードと標準の画像サイズの潜在ベクトルを使用することで、この問題を克服します。
- 「FlexGenに会おう:GPUメモリが限られている場合に大規模な言語モデル(LLM)を実行するための高スループットな生成エンジン」
- このAI論文は、拡散モデルのコンセプトを自身の知識を使って消去するためのモデルの重みを微調整する新しい方法を提案しています
- このAI論文では、一般的なソース分布とターゲット分布の間の連続時間確率生成モデルの学習のための新しいクラスのシミュレーションフリーな目的を紹介しています
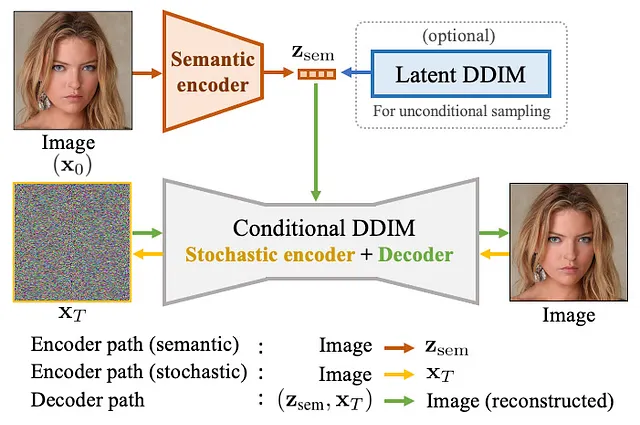
DAEはオートエンコーディングモデルであり、エンコーダとデコーダから構成され、自己回帰的にトレーニングされます。DAEのエンコーダは画像をその画像のセマンティック表現にエンコードします。デコーダは、セマンティック潜在ベクトルとノイズ画像を取り、拡散プロセスを実行して画像を再構築します。
結果として、これにより拡散レベルの品質の画像生成がセマンティック制御で可能になります
DAE-Talkerの場合、DAEモデルは対象の俳優の約10分間のデータでトレーニングされます。
潜在空間の制御
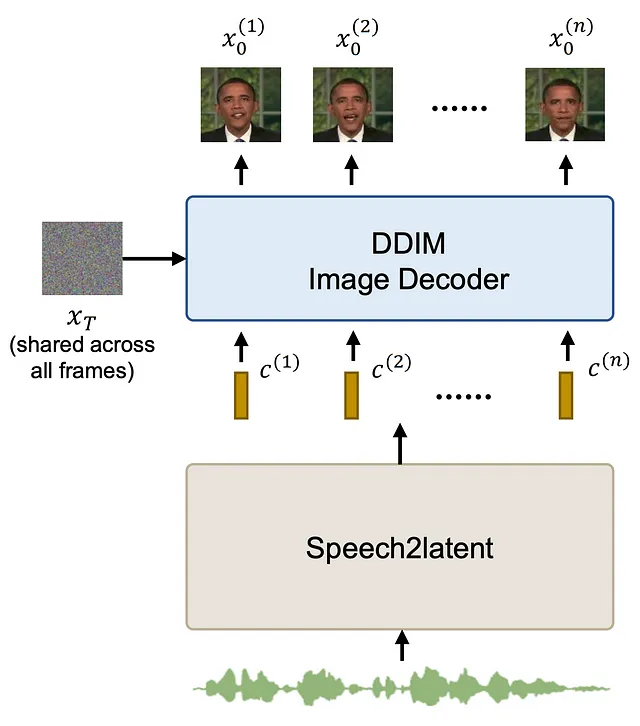
訓練済みのDAEを使用することで、セマンティック潜在ベクトルを使用して生成された画像を制御することが可能になり、潜在ベクトルのみを操作してビデオを生成することが可能になります。これがこの論文のspeech2latentコンポーネントの目的です。入力として音声を与えると、後でDAEによって復号化される潜在ベクトルのシーケンスが出力されます。
ここで重要なポイントは、生成されたビデオの各フレームでランダムノイズ画像が固定されているということです。これにより、最終的なビデオに時間的な不整合を生じさせるランダムノイズが削減されます。

speech2latentコンポーネントは、いくつかのレイヤーから構成されています。最初のレイヤーは、Wav2Vec2モデルからの凍結特徴抽出器です。Wav2Vec2は音声認識に使用されるトランスフォーマーベースのモデルです。特徴抽出器を取ることで、音声の豊かな潜在特徴を抽出することができます。これは、FaceFormerやImitatorなど、音声から信号を生成しようとするいくつかの論文で行われています。この一連の特徴は、畳み込みとコンフォーマーブロック(CNNとトランスフォーマーレイヤーの組み合わせ)を使用してさらに処理されます。その後、ポーズ適応レイヤーが適用されます(これについては後で説明します)、最終的な一連のコンフォーマーレイヤーとDAE潜在空間への線形投影が行われます。
ポーズアダプター
音声駆動アニメーションの問題は、一対多の問題です。特に、ヘッドポーズの場合は、同じ音声が多くの異なるポーズに対応することが容易です。この問題を軽減するために、著者らはスピーチ2ラテントネットワークにポーズをモデル化する特定のコンポーネントの追加を提案しています。ポーズ予測器はスピーチからポーズを予測し、ポーズプロジェクタはポーズをネットワークの中間特徴に戻します。この段階でポーズ損失を追加することで、ポーズがより良くモデル化されます。ポーズが特徴に投影されるため、予測されたポーズまたはグラウンドトゥルースのポーズのいずれかを使用することができます。
ディスカッション
これは、話す顔生成に拡散モデルを使用する最初の手法ではありませんが、非常に成功した方法を見つけたようです。結果は、私の意見では、既存のモデルの中で最高の品質です。また、ポーズを制御または生成できる能力により、モデルは特に柔軟性があります。
しかしながら、このモデルは完璧ではありません。この手法は、個人の特異性を極端に高めています。このモデルは、単一のスピーカーからの12分のデータで訓練されており、背景、照明、カメラの変化はありません。これは、他のほとんどの手法で使用されるデータ量よりも桁違いに多いです。おそらくこの理由により、実験は1つのデータセットに制限されています。Obama以外の人々に対する実験を見ない限り、このモデルがほとんどの人に適用できることを確認するのは難しいです。さらに、このモデルは訓練が容易ではありません。DAEコンポーネントのみでも、8つのV100 GPUで3日間訓練されましたが、speech2latentはそれ以上の時間を要します。現在のGCPの価格によると、訓練には最大で1500ドル以上かかる可能性があります!推論も時間がかかるでしょう。フレームごとに100回のノイズ除去ステップが必要です。
結論
全体的に、これは現在利用可能な最高の結果を示す非常に有望な手法ですが、訓練に関連する莫大なコストを気にしないのであればです。もし誰かがこのモデルの汎用版を開発する方法を見つけることができれば(それに費用をかけることができるならば)、話す顔生成の問題を完全に解決に近づけることができると思います。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 2023年の最高のオープンソースインテリジェンス(OSINT)ツール
- 「機械学習における特徴エンジニアリングへの実践的なアプローチ」
- 機械学習(ML)の実験トラッキングと管理のためのトップツール(2023年)
- Google AIは、アーキテクチャシミュレータにさまざまな種類の検索アルゴリズムを接続するための、マシンラーニングのためのオープンソースのジム「ArchGym」を紹介しました
- 「生成型AIとMLOps:効率的で効果的なAI開発のための強力な組み合わせ」
- CarperAIは、コードと自然言語の両方で進化的な検索を可能にするために設計されたオープンソースライブラリ、OpenELMを紹介します
- AIによる生産性向上 生成AIが様々な産業において効率の新たな時代を開く






