「CutLER(Cut-and-LEaRn):人間の注釈なしで物体検出とインスタンスセグメンテーションモデルをトレーニングするためのシンプルなAIアプローチによる出会い」
CutLER A Simple AI Approach for Training Object Detection and Instance Segmentation Models without Human Annotations


オブジェクト検出と画像セグメンテーションは、コンピュータビジョンと人工知能の重要なタスクです。これらは、自動車、医療画像、セキュリティシステムなど、さまざまなアプリケーションで重要です。
オブジェクト検出は、画像やビデオストリーム内のオブジェクトのインスタンスを検出することを目的としています。オブジェクトのクラスと画像内の位置を特定することから成り立っています。目標は、オブジェクトの周囲に境界ボックスを生成し、さらなる分析やビデオストリーム内でのオブジェクトの追跡に使用することです。オブジェクト検出アルゴリズムは、ワンステージとツーステージの2つのカテゴリに分けることができます。ワンステージの方法は速いですが正確性は低く、ツーステージの方法は遅いですが正確性が高いです。
一方、画像セグメンテーションは、画像を複数のセグメントまたは領域に分割することで、各セグメントが異なるオブジェクトまたはオブジェクトの一部に対応するようにすることを目的としています。目標は、画像内の各ピクセルにセマンティッククラス(「人」、「車」、「空」など)をラベル付けすることです。画像セグメンテーションアルゴリズムは、セマンティックセグメンテーションとインスタンスセグメンテーションの2つのカテゴリに分けることができます。セマンティックセグメンテーションは、各ピクセルにクラスラベルを付けることを目的としていますが、インスタンスセグメンテーションは、画像内の個々のオブジェクトを検出してセグメント化することを目的としています。
- 「PyTorchにおける複数GPUトレーニングとそれに代わる勾配蓄積」
- 「夢の彫刻:DreamTimeは、テキストから3Dコンテンツ生成の最適化戦略を改善するAIモデルです」
- 「大規模言語モデルのランドスケープをナビゲートする」
オブジェクト検出と画像セグメンテーションの両方のアルゴリズムは、深層学習のアプローチによって最近大きく進化しています。ピクチャ入力の階層的表現を学習する能力があるため、畳み込みニューラルネットワーク(CNN)はこれらの問題に対する選択肢となっています。ただし、これらのモデルのトレーニングには、オブジェクトボックス、マスク、ローカライズされたポイントなどの専門的な注釈が必要であり、これは困難で時間がかかる作業です。オーバーヘッドを考慮しない場合、COCOデータセットの164K枚の画像に対して、80のクラスのマスク付きの手動注釈を行うには28K時間以上が必要でした。
新しいアーキテクチャであるCut-and-LEaRn(CutLER)を用いて、著者たちはこれらの問題に対処しようとします。CutLERは、人間のラベルなしでトレーニングできる教師なしのオブジェクト検出とインスタンスセグメンテーションモデルを研究することを目的としています。この手法は、3つのシンプルなアーキテクチャとデータに依存しないメカニズムで構成されています。提案されたアーキテクチャのパイプラインを以下に示します。
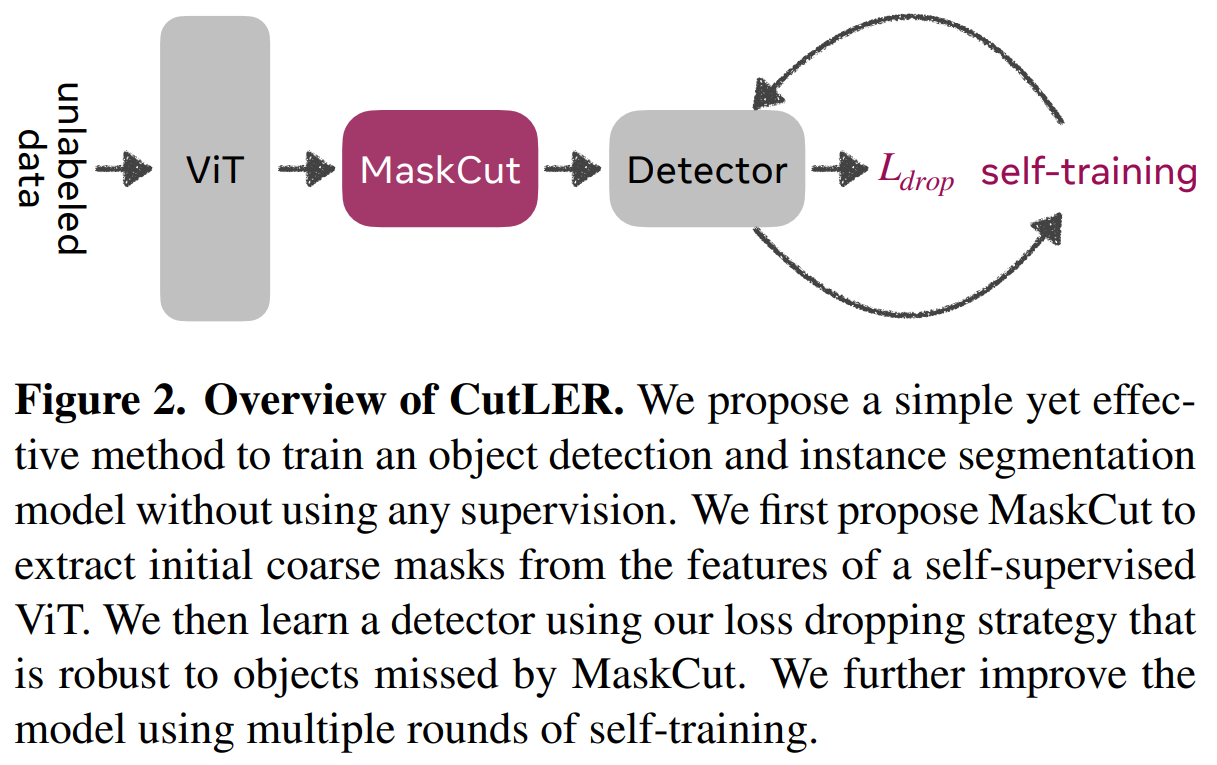
CutLERの著者は、まず、自己教師ありの事前学習ビジョントランスフォーマーViTによって計算された特徴に基づいて、各画像に対して複数の初期ラフマスクを自動生成するツールであるMaskCutを紹介しています。MaskCutは、Normalized Cuts(NCut)などの現在のマスキングツールの制限に対処するために開発されました。実際、NCutの応用は画像内の単一のオブジェクト検出に制限されることが多く、これは大きな制約となる場合があります。そのため、MaskCutは、マスクされた類似度行列に反復的にNCutを適用することで、画像ごとに複数のオブジェクトを発見するように拡張しています。
次に、著者たちは、これらのラフマスクを使用してディテクタをトレーニングするための簡単なロスドロップ戦略を実装しています。これらのラフマスクでトレーニングされたディテクタは、地面の真実を洗練し、より正確なマスク(およびボックス)を生成することができます。したがって、モデルの予測に対する自己トレーニングの複数のラウンドにより、モデルは局所的なピクセルの類似性に焦点を当てることから、全体的なオブジェクトのジオメトリを考慮することに進化し、より正確なセグメンテーションマスクを生成することができます。
以下の図は、提案されたフレームワークと最先端のアプローチとの比較を示しています。

これは、正確で一貫性のある物体検出と画像セグメンテーションのための新しいAIツール、CutLERの概要でした。
このフレームワークに興味がある場合や詳細を知りたい場合は、論文とプロジェクトページへのリンクを見つけることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






