模倣学習を用いたインタラクティブエージェントの作成
Creating Interactive Agents Using Imitation Learning
人間は対話的な生物です。私たちは物理的な世界と他の人々と対話します。人工知能(AI)が一般的に役立つためには、人間とその環境と適切に対話できる能力が必要です。この作業では、視覚知覚、言語理解と生成、ナビゲーション、操作を組み合わせて人間との長い間、そしてしばしば驚きのある身体的および言語的対話を行うためのマルチモーダルインタラクティブエージェント(MIA)を紹介します。

私たちは、エージェントを訓練するために主に模倣学習を使用した Abramson らの手法を基にしています(2020)。訓練後、MIAはいくつかの初歩的な知的行動を示し、後の人間のフィードバックを使用して洗練させることを望んでいます。この作業では、この知的行動の事前設定の作成に焦点を当て、フィードバックに基づいた学習は将来の作業に任せます。
私たちは、Playhouse 環境を作成しました。これはランダムな部屋のセットと多くの家庭用インタラクティブオブジェクトから構成された3D仮想環境であり、人間とエージェントが一緒に対話するためのスペースと設定を提供します。人間とエージェントは、仮想ロボットを制御して移動し、オブジェクトを操作し、テキストを介してコミュニケーションすることでPlayhouseで対話することができます。この仮想環境では、単純な指示(例:「床から本を取り上げて青い本棚に置いてください」)から創造的な遊び(例:「食べるために食べ物をテーブルに持ってきてください」)まで、幅広い状況における対話が可能です。
私たちは、言語ゲームを使用してPlayhouseの対話の人間の例を収集しました。言語ゲームは、特定の行動を即興で行うように人間に促すための手がかりのコレクションです。言語ゲームでは、1人のプレーヤー(セッター)が他のプレーヤー(ソルバー)に提案するタスクの種類を示す予め書かれたプロンプトを受け取ります。たとえば、セッターは「他のプレーヤーにオブジェクトの存在に関する質問をしてください」というプロンプトを受け取り、いくつかの探索の後、セッターは「家具のない部屋に青いアヒルがあるかどうか教えてください」と尋ねることができます。十分な行動の多様性を確保するために、自由形式のプロンプトも含めました。これにより、セッターは即興で対話を行うことを自由に選択することができます(例:「好きなオブジェクトを取って、テニスボールをスツールから転がして時計の近く、またはその近くに置いてください」)。合計で、私たちはPlayhouseで2.94年分のリアルタイムの人間の対話を収集しました。
.jpg)
私たちの訓練戦略は、人間の行動の予測(行動クローニング)と自己教師あり学習の組み合わせです。人間の行動を予測する際に、階層制御戦略を使用すると、エージェントのパフォーマンスが大幅に向上することがわかりました。この設定では、エージェントはおおよそ1秒に4回の新しい観測を受け取ります。各観測に対して、エージェントはオープンループの移動アクションのシーケンスを生成し、必要に応じて言語アクションのシーケンスを出力します。行動クローニングに加えて、エージェントには自己教師あり学習の形式も使用しており、特定の視覚と言語の入力が同じエピソードに属するか異なるエピソードに属するかを分類する課題を与えています。
エージェントのパフォーマンスを評価するために、人間の参加者にエージェントと対話し、エージェントが指示を正常に実行したかどうかを示すバイナリフィードバックを提供してもらいました。MIAは、人間によるオンライン対話で70%以上の成功率を達成し、ソルバーとしてプレーする人間自身が達成する成功率の75%を表しています。MIAのさまざまなコンポーネントの役割をよりよく理解するために、視覚や言語の入力、自己教師あり損失、階層制御などを除いた一連の削除実験も行いました。
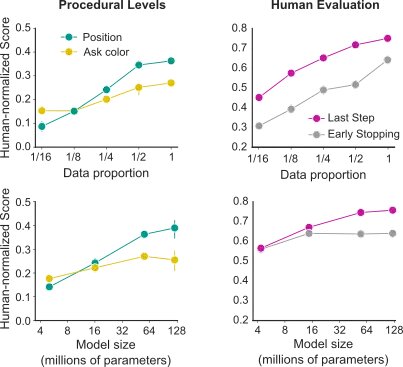
現代の機械学習の研究では、異なるスケールパラメータに関するパフォーマンスの顕著な規則性が明らかにされています。特に、モデルのパフォーマンスは、データセットのサイズ、モデルのサイズ、および計算量に対してべき乗則でスケールします。これらの効果は、データセットのサイズが非常に大きく、進化したアーキテクチャとトレーニングプロトコルが特徴的な言語ドメインで最も鮮明に観察されています。しかし、この作業では、比較的小規模なデータセットと多モーダル、マルチタスクの目的関数を持つ異種アーキテクチャでトレーニングしています。それにもかかわらず、スケーリングの明確な効果を示しています。データセットとモデルのサイズを増やすと、パフォーマンスが著しく向上します。
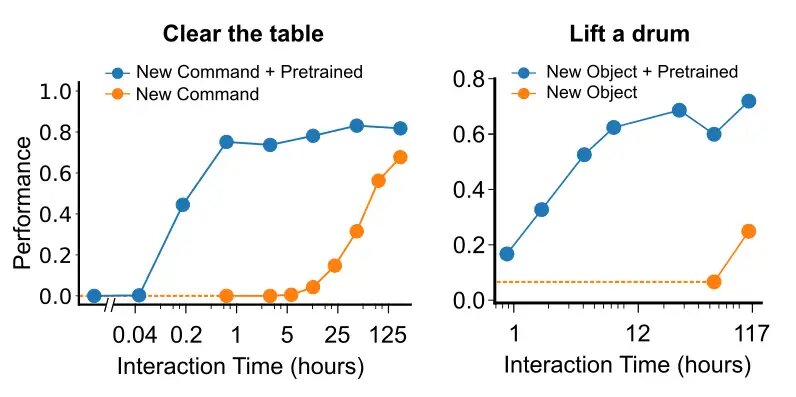
理想的な場合、データセットが十分に大きい場合、トレーニングは効率的になります。なぜなら、知識は経験間で転送されるからです。私たちの状況がどれだけ理想的かを調査するために、新しい、以前に見たことのないオブジェクトと新しい、以前に聞いたことのないコマンド/動詞との相互作用を学習するためにどれだけのデータが必要かを調べました。データは、オブジェクトまたは動詞に関する言語指示を含む背景データとデータに分割しました。新しいオブジェクトに関するデータを再導入すると、人間との対話時間が12時間未満で天井パフォーマンスを獲得するのに十分であることがわかりました。同様に、新しいコマンドまたは動詞「クリア」(つまり、表面からすべてのオブジェクトを取り除くこと)を導入すると、1時間の人間のデモンストレーションだけで、この単語を含むタスクの天井パフォーマンスに到達するのに十分であることがわかりました。
MIAは驚くほど豊かな行動を示し、研究者によって事前に考えられていなかった様々な行動、例えば部屋を片付ける、複数の特定のオブジェクトを見つける、指示が曖昧な場合には質問をするなどがあります。これらのインタラクションは私たちを絶えずインスパイアしています。しかし、MIAの行動の無限の可能性は、定量的な評価にとって非常に大きな課題を提供します。人間とエージェントの相互作用におけるオープンエンドの行動を捉え、分析するための包括的な方法論を開発することは、私たちの将来の仕事の重要な焦点となるでしょう。
作業の詳細な説明については、私たちの論文をご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




