大規模言語モデルを使用したアプリを作成するためのデータパイプラインの構築
ビューティー&ファッションの専門家による大規模な言語モデルを活用したアプリ開発のためのデータパイプライン構築

現在の企業は、LLMを利用したアプリに対して、次の2つのアプローチを追求しています – Fine tuning(微調整)とRetrieval Augmented Generation(RAG)。大まかなレベルで説明すると、RAGは入力を取り、ソース(たとえば、企業のウィキ)から関連する/サポートするドキュメントのセットを検索します。これらのドキュメントは元の入力のプロンプトと共にコンテキストとして結合され、LLMモデルに供給されて最終的な応答を生成します。RAGは、特にリアルタイム処理のシナリオでLLMを市場に導入するための最も人気のあるアプローチのようです。このような場合、ほとんどの場合、効果的なデータパイプラインの構築がLLMアーキテクチャに含まれます。
本記事では、デベロッパーがデータと連動する製品レベルのシステムを実装するためにLLMのデータパイプラインの異なるステージを探ります。GenAIアプリを駆動するデータの収集、準備、エンリッチメント、提供方法を学びましょう。
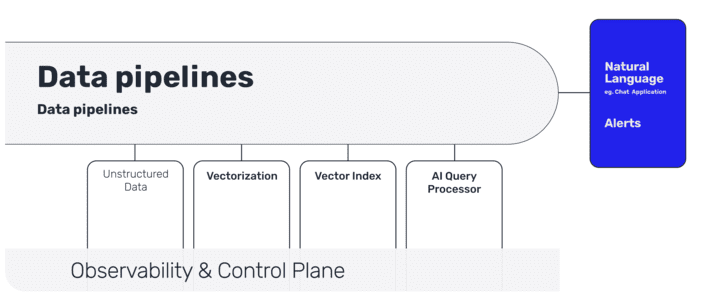
LLMパイプラインの異なるステージとは?
LLMパイプラインの異なるステージは次のとおりです。
非構造化データのデータ取り込み
(メタデータを使用した)ベクトル化
(リアルタイム同期を含む)ベクトル索引付け
AIクエリプロセッサ
自然言語のユーザーインタラクション(チャットまたはAPIを使用して)
非構造化データのデータ取り込み
最初のステップは、ビジネスの目標に役立つ適切なデータを収集することです。もし、消費者向けのチャットボットを構築しているなら、使用されるデータに特に注意を払う必要があります。データのソースは、企業ポータル(たとえばSharepoint、Confluent、ドキュメントストレージ)から内部APIまでさまざまなものです。理想的には、これらのソースから指標へのプッシュメカニズムを持っていることが望まれます。これにより、LLMアプリは最終ユーザーのために最新の状態になります。
組織は、コンテキスト学習のためのテキストデータを抽出する際に、データガバナンスポリシーとプロトコルを実施するべきです。組織は、文書データソースを監査して重要度レベル、ライセンス条件、および原産地情報をカタログ化することから始めることができます。データセットから抹消または除外する必要がある制限されたデータを特定します。
これらのデータソースには、品質も評価する必要があります – 変動性、サイズ、ノイズレベル、冗長性など。品質の低いデータセットはLLMアプリからの応答を希釈します。さらに、パイプライン内で後続の適切なストレージ手段をサポートするために、早い段階でドキュメントの分類を行う必要があるかもしれません。
LLM開発の速度が速くても、データガバナンスを固定することでリスクを低減できます。ガバナンスを最初に確立することで、後の段階で多くの問題を軽減し、コンテキスト学習のためのテキストデータの抽出をスケーラブルかつ堅牢に行うことができます。
Slack、Telegram、またはDiscordのAPIを介してメッセージを取得することで、リアルタイムデータへのアクセスが可能になり、RAGが役立ちますが、生の対話データにはノイズが含まれています – タイプミス、エンコードの問題、奇妙な文字。リアルタイムで、攻撃的な内容や個人情報とされる機微な詳細を過激なコンテンツとしてフィルタリングすることは、データクレンジングの重要な部分です。
メタデータを使用したベクトル化
著者、日付、および会話のコンテキストなどのメタデータは、データをさらに豊かにします。外部知識をベクトルに埋め込むことは、よりスマートでターゲットされた検索に役立ちます。
ドキュメントに関連する一部のメタデータは、ポータルまたはドキュメントのメタデータ自体に存在するかもしれませんが、文書がビジネスオブジェクト(例:ケース、顧客、従業員情報)にアタッチされている場合は、関連する情報をリレーショナルデータベースから取得する必要があります。データアクセスに関するセキュリティ上の懸念がある場合、この場所で検索段階でのセキュリティメタデータを追加することもできます。
ここで重要なステップは、LLMの埋め込みモデルを使用してテキストと画像をベクトル表現に変換することです。ドキュメントの場合は、まずチャンキングを行い、次にオンプレミスのゼロショット埋め込みモデルを使用してエンコードを行う必要があります。
ベクトル索引付け
ベクトル表現はどこかに保存する必要があります。これが、ベクトルデータベースまたはベクトルインデックスが埋込みとしてこの情報を効率的に保存およびインデックス化するために使用される場所です。
これはあなたの「LLMの真実のソース」となり、これはデータソースと文書と同期している必要があります。リアルタイムインデックス化は、LLMアプリが顧客にサービスを提供したりビジネス関連情報を生成している場合に重要になります。データソースと同期していないLLMアプリを避けたいからです。
クエリプロセッサによる高速検索
何百万もの企業文書がある場合、ユーザークエリに基づいて適切な内容を取得することは難しくなります。
これが、パイプラインの初期段階で価値を追加し始める場所です:クレンジングおよびメタデータの追加によるデータの充実、さらに重要なのはデータのインデックス化です。これにより、迅速なエンジニアリングが強化されます。
ユーザーのインタラクション
従来のパイプライン環境では、データをデータウェアハウスにプッシュし、分析ツールがデータウェアハウスからレポートを抽出します。LLMパイプラインでは、エンドユーザーインターフェースは通常、ユーザーのクエリを受け取り、クエリに応答するチャットインターフェースです。
要約
この新しいタイプのパイプラインの課題は、プロトタイプを作成するだけでなく、これを本番環境で動作させることです。これが、パイプラインとベクトルストアを監視するためのエンタープライズグレードのモニタリングソリューションの重要性です。構造化および非構造化データソースからビジネスデータを取得する能力は、重要なアーキテクチャ上の決定となります。LLMsは自然言語処理の最先端を表し、LLMパワードアプリのためのエンタープライズグレードのデータパイプラインの構築は、常に最新の状態に保つことができます。
こちらはリアルタイムストリーム処理フレームワークへのアクセスです。
[Anup Surendran](https://www.linkedin.com/in/anupsurendran/)は、AI製品を市場に導入することに特化した製品および製品マーケティングの副社長です。彼はSAPとKrollに成功裏に売却されたスタートアップと共に働いており、AI製品が組織内で生産性を向上させる方法について他の人々に教えることを楽しんでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Pythonのオブジェクト指向プログラミング、そしてrepr()とstr()の重要性」
- 「Google Brainの共同創設者は、テック企業がAIのリスクを大げさに報じている」と主張しています
- チャットGPTを使用して複雑なシステムを構築する
- 「グーグルのAI研究によると、グラフデータのエンコーディングが言語モデルのパフォーマンスを複雑なタスクに向上させることが明らかになりました」
- 「ジュニアデータサイエンティストのための3つのキャリアの重要な決断」
- アップル M2 Max GPU vs Nvidia V100、P100、およびT4
- 「5つのシンプルなステップシリーズ:Python、SQL、Scikit-learn、PyTorch、Google Cloudをマスターする」
