「Juliaでスクラッチから作成するゲート付き再帰ニューラルネットワーク」
Creating a gated recursive neural network from scratch with Julia
ゼロからGRUセルを使ったRNNを構築するためにJuliaを探索しましょう
1. イントロダクション
しばらく前から、私は科学的プログラミングとデータサイエンスのためにJuliaを学び始めました。Juliaの持つ統計的なパワー、Pythonの表現力と明確な構文、そしてC++のようなコンパイル言語の高いパフォーマンスの組み合わせにより、Juliaの採用は続いています。
何かを学ぶ最良の方法は、それを常に実践することです。この「単純な」方法は、テックフィールドでは明らかに効果的です。コーディングと実践を通じて、プログラマーやコーダーは構文、データ型、関数、メソッド、変数、メモリ管理、制御フロー、エラーハンドリング、ベストプラクティスと規約を含むライブラリなど、すべてを理解し探求することができます。
この信念に強く結びついて、私は最新のGated Recurrent Units(GRU)アーキテクチャを使ったRecurrent Neural Network(RNN)を構築する個人プロジェクトを立ち上げました。さらにJuliaの理解を深めるために、このRNNをゼロから構築しました。このアイデアは、株式市場に関連する時系列予測のためにRNNとGRUを使用することです。
Juliaでゼロから密度ベースのクラスタリングアルゴリズムを実装する
データサイエンスにおけるPythonの代替としてJuliaでコーディングしましょう
pub.towardsai.net
- 「Great Expectationsを始めよう Pythonにおけるデータ検証ガイド」
- 「データサイエンティストになる夢を諦めなかった8つの理由と、あなたも諦めるべきではない理由」
- 「すべてのデータを理解する」
この投稿の概要は次のとおりです:
- GRUアーキテクチャの理解
- プロジェクトのセットアップ
- GRUネットワークの実装
- 結果と洞察
- 結論
このプロジェクトのために作成されたGitHubリポジトリを開始し、フォークし、共有し、最も重要なことに、実験してください👇。
GitHub – jodhernandezbe/post-gru-julia: これは、Juliaコードを作成するためのリポジトリです…
これは、株式のためにゼロからGated Recurrent Neural Networkを作成するためのJuliaコードを含むリポジトリです…
github.com
2. GRUアーキテクチャの理解
このセクションの目的は、GRUアーキテクチャの詳細な説明をすることではなく、ゼロからGRUセルを使ったRNNのコーディングに必要な要素を提示することです。初心者に言えることは、RNNはテキスト、株価、センサーデータなどの連続データを扱うことができるモデルの一部です。
隠れマルコフモデルの解明:概念、数学、および実際の応用
隠れマルコフチェーンを探索しましょう
VoAGI.com
GRUのアイデアは、バニラRNNの勾配消失問題を克服することです。Chi-Feng Wangによる投稿は、この問題の簡単な説明を提供してくれます👇。GRUについてさらに詳しく知りたい場合は、以下の読みやすくオープンソースの論文を読むことをおすすめします:
- On the Properties of Neural Machine Translation: Encoder–Decoder Approaches
- Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
勾配消失問題
問題、原因、重要性、および解決策
towardsdatascience.com
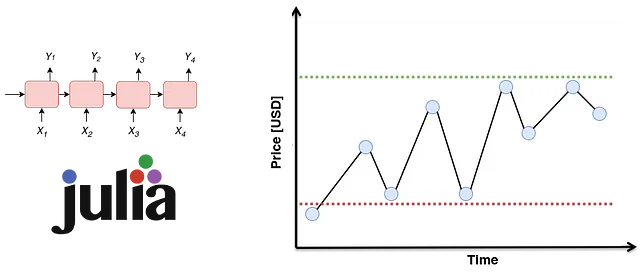
この記事では、深さも双方向もないRNNを実装しています。Julia統合関数はこの動作をキャプチャできる必要があります。図1に示すように、GRUセルの付いたRNNは連続的なフェーズの系列から構成されています。各ステージtでは、直前のステージの隠れ状態(hₜ₋₁)に対応する要素が供給されます。同様に、要素はサンプル系列のtᵗʰ要素(つまり、xₜ)を表します。各GRUセルの出力は、次のフェーズ(つまり、hₜ)に供給されるその時点の隠れ状態を示します。さらに、hₜはSoftmaxのような関数を通じて望ましい出力を得るために使用できます(たとえば、テキスト内の単語が形容詞かどうか)。
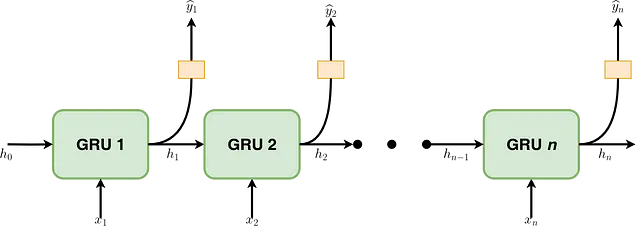
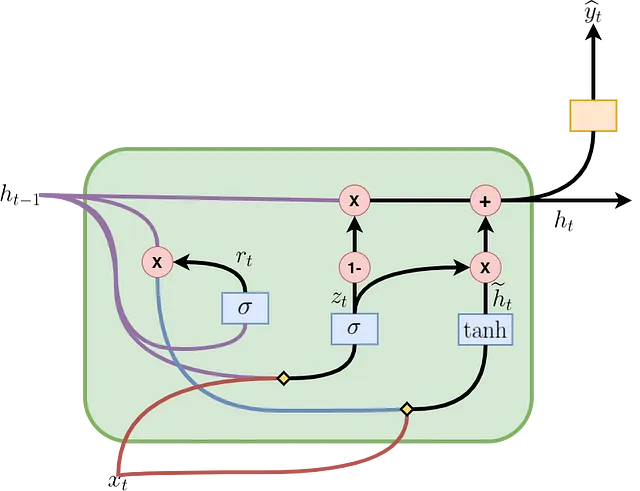
図2は、GRUセルがどのように形成され、情報が流れ、数学的な操作が発生するかを示しています。時間ステップtのセルには、次のステップに渡される前の情報のどの部分を決定する更新ゲート(zₜ)と、前の情報のどの部分を忘れるべきかを決定するリセットゲート(rₜ)が含まれています。rₜ、hₜ₋₁、xₜを使用して、現在のステップの候補の非表示状態(ĥₜ)が計算されます。その後、zₜ、hₜ₋₁、ĥₜを使用して、実際の非表示状態(hₜ₋₁)が計算されます。これらの操作は、GRUセル内の順方向パスを構成し、図3に示される式で要約されています。ここで、Wᵣₕ、Wᵣₓ、Wₕₕ、Wₕₓ、W₂ₓ、W₂ₕ、bᵣ、bₕ、およびb₂は学習可能なパラメータです。” * “は行列の掛け算を示し、”・”は要素ごとの掛け算を示します。
文献では、図4に示すような順方向パスの式が一般的です。この図では、行列の連結が使用され、図3に示される式を短くするために使用されます。Wᵣ、Wₕ、およびW₂は、それぞれWᵣₕとWᵣₓ、WₕₕとWₕₓ、およびW₂ₓとW₂ₕの垂直連結です。角括弧内の要素は水平方向に連結されていることを示しています。両方の表現は有用であり、図4の表現は式を短縮するのに適しており、図3の表現は逆伝播の式を理解するのに役立ちます。
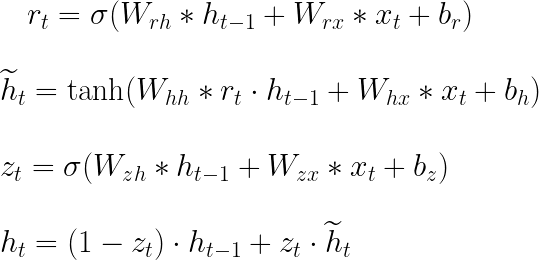
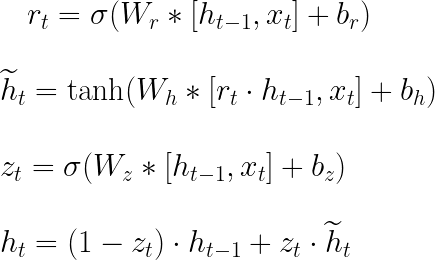
図4は、モデルトレーニングのためにJuliaプログラムに含める必要がある逆伝播の式を示しています。式中の”T”は行列の転置を示します。これらの式は、多変数関数の全微分の定義と連鎖律を使用して得ることができます。また、図形的なアプローチを使用することで、自分自身をガイドすることもできます👇:
GRUでの順方向および逆伝播 – 導出 | ディープラーニング
ゲート型リカレントユニット(GRU)の説明と、損失が時間を逆伝播する数学的な背後についての説明。
VoAGI.com
GRUユニット
GRUユニットを使用してBPTTを実行するには、トップレイヤーからのエラー(\(\delta 1\))と、未来の非表示…
cran.r-project.org

3. プロジェクトのセットアップ
プロジェクトを実行するには、ドキュメントの指示に従ってコンピュータにJuliaをインストールしてください。
公式バイナリのプラットフォーム固有の指示
Julia言語の公式ウェブサイトです。Juliaは高速で動的で使いやすいオープンソースの言語です…
julialang.org
Pythonと同様に、Juliaカーネルを使用したJupyter Notebookを使用することができます。その場合は、以下の記事をご覧ください。Dr Martin McGovern博士による執筆です。
JupyterでJuliaを最大限に活用する方法
JuliaコードをJupyterノートブックに追加し、同じノートブックでPythonとJuliaを同時に使用する方法についての記事です…
towardsdatascience.com
3.1. プロジェクトの構成
Githubリポジトリのプロジェクトは以下のツリー構造を持っています:
.├── data│ ├── AAPL.csv│ ├── GOOG.csv│ └── IBM.csv├── plots│ ├── residual_plot.png│ └── sequence_plot.png├── Project.toml├── .pre-commit-config.yaml├── src│ ├── data_preprocessing.jl│ ├── main.jl│ ├── prediction_plots.jl│ └── scratch_gru.jl└── tests (unit testing) ├── test_data_preprocessing.jl ├── test_main.jl └── test_scratch_gru.jlフォルダー:
data: このフォルダーには、モデルのトレーニングに使用するデータが含まれる.csvファイルがあります。ここには株価ファイルが保存されています。plots: モデルトレーニング後に得られるプロットを保存するためのフォルダーです。src: このフォルダーはプロジェクトのコアであり、データの前処理、モデルのトレーニング、RNNアーキテクチャの構築、GRUセルの作成、プロットの作成に必要な.jlファイルが含まれています。tests: このフォルダーには、コードの正確性を確認しバグを検出するためにJuliaで作成されたユニットテストが含まれています。このフォルダーの内容の説明はこの記事の範囲外です。参考にしていただき、もしTestパッケージについての記事が必要であればお知らせください。
ユニットテスト
Base.runtests(tests=[“all”]; ncores=ceil(Int, Sys.CPU_THREADS / 2), exit_on_error=false, revise=false, [seed])は、…
docs.julialang.org
3.2. 必要なパッケージ
ゼロから始めることになりますが、以下のパッケージが必要です:
CSV(0.10.11):CSVはComma-Separated Values(CSV)ファイルを扱うためのJuliaのパッケージです。DataFrames(1.5.0):DataFramesは、タブularデータを扱うためのJuliaのパッケージです。LinearAlgebra(標準):LinearAlgebraは、線形代数のルーチンのコレクションを提供するJuliaの標準パッケージです。Base(標準):Baseは、基本的な機能とコアデータ型を提供するJuliaの標準モジュールです。Statistics(標準):Statisticsは、データ分析のための統計関数とアルゴリズムを提供するJuliaの標準モジュールです。ArgParse(1.1.4):ArgParseは、Juliaでコマンドライン引数を解析するためのパッケージです。Juliaスクリプトやアプリケーションのためのコマンドラインインターフェイスを簡単かつ柔軟に定義する方法を提供します。Plots(1.38.16):Plotsは、データの可視化を作成するための高レベルなインターフェイスを提供するJuliaの人気のあるプロットパッケージです。Random(標準):Randomは、ランダムな数値の生成やランダムプロセスの操作に使用する関数を提供するJuliaの標準モジュールです。Test(標準、ユニットテストのみ):Testは、ユニットテストの作成に役立つユーティリティを提供するJuliaの標準モジュールです(この記事の範囲を超えます)。
上記のパッケージが含まれる環境を作成するために、Project.tomlを使用することができます。このファイルは、Pythonのrequirements.txtやCondaのenvironment.ymlのようなものです。以下のコマンドを実行して依存関係をインストールしてください:
julia --project=. -e 'using Pkg; Pkg.instantiate()'3.3. 株価
データサイエンスの実践者として、データは機械学習や統計モデルを動かすための燃料であることを理解しています。この例では、ドメイン固有のデータは株式市場から取得します。Yahoo Financeは一般に利用可能な株式市場の統計情報を提供しています。ここでは特にGoogle Inc.(GOOG)の過去の統計情報を見ていきますが、IBMやAppleなど他の企業のデータも検索してダウンロードすることができます。
Alphabet Inc.(GOOG)の株価履歴データ – Yahoo Finance
Yahoo FinanceでGOOGの株価の過去のデータを見つけることができます。日次、週次、月次の形式で遡ることができます…
finance.yahoo.com
4. GRUネットワークの実装
srcフォルダの中には、セクション5で示されるプロットを生成するために使用されるファイル(prediction_plots.jl)、モデルトレーニングの前に株価を処理するためのファイル(data_preprocessing.jl)、GRUネットワークをトレーニングして構築するためのファイル(scratch_gru.jl)、および上記のすべてのファイルを一度に統合するファイル(main.jl)があります。このセクションでは、GRUネットワークアーキテクチャの中核を構成する4つの関数に詳しく触れます。これらの関数はトレーニング中の順方向および逆方向の伝播を実装するために使用されます。
4.1. gru_cell_forward関数
以下のコードスニペットはgru_cell_forward関数に対応します。この関数は現在の入力(x)、前の隠れ状態(prev_h)、およびパラメータの辞書(parameters)を入力として受け取ります。これらのパラメータを使用して、この関数はGRUセルの順伝播の1ステップを可能にし、更新ゲート(z)、リセットゲート(r)、新しいメモリセルまたは候補の隠れ状態(h_tilde)、および次の隠れ状態(next_h)をsigmoid関数およびtanh関数を使用して計算します。また、GRUセルの予測(y_pred)も計算します。この関数の内部では、図3と図4に示された式が実装されています。
4.2. gru_forward関数
gru_cell_forwardとは異なり、gru_forwardはGRUネットワークの順伝播、つまり時系列の順伝播を実行します。この関数は、入力テンソル(x)、初期隠れ状態(ho)、および辞書を入力として受け取ります(parameters)。
シーケンシャルモデルについて初めて学ぶ場合、時間ステップとイテレーションを混同しないでください。モデルの誤差を最小化するためです。
gru_cell_forwardが受け取るxとgru_forwardが受け取るxを混同しないでください。gru_forwardでは、xは2次元ではなく3次元です。3次元目は、RNN層が持つGRUセルの総数に対応します。つまり、gru_cell_forwardは図2に関連しており、gru_forwardは図1に関連しています。
gru_forwardは、シーケンス内の各時間ステップを繰り返し、gru_cell_forward関数を呼び出してnext_hとy_predを計算します。結果はそれぞれhとyに格納されます。
4.3. gru_cell_backward 関数
gru_cell_backwardは、単一のGRUセルの逆伝播を行います。 gru_cell_forwardは、入力として非表示状態の勾配(dh)を受け取り、図4で導出するために必要な要素を含むキャッシュ(next_h、prev_h、z、r、h_tilde、x、およびparameters)を伴います。このように、gru_cell_backwardは重み行列(Wz、Wr、およびWh)とバイアス(bz、br、およびbh)の勾配を計算し、すべての勾配をJuliaの辞書(gradients)に格納します。
4.4. gru_backward 関数
gru_backwardは、完全なGRUネットワークに対してバックプロパゲーションを実行します。つまり、時間ステップの完全なシーケンスに対して実行します。この関数は非表示状態テンソル(dh)とcachesを受け取ります。 gru_cell_backwardの場合とは異なり、gru_backwardのdhには、シーケンス内の時間ステップの合計数またはGRUネットワークレイヤーのGRUセルに対応する三次元があります。この関数は逆順に時間ステップを繰り返し、各時間ステップの勾配を計算するためにgru_cell_backwardを呼び出し、ループ全体で勾配を蓄積します。
この段階で重要な点は、このプロジェクトはGRUネットワークのパラメータを更新するために勾配降下法のみを使用し、学習率やモメンタムを導入する機能は含まれていないことです。さらに、実装は回帰の問題を考慮して作成されました。ただし、実装されたモジュール化のため、異なる動作を取得するにはわずかな変更のみが必要です。
5. 結果と洞察
では、GRUネットワークのトレーニングのためにコードを実行しましょう。 ArgParseパッケージの統合により、コマンドライン引数を使用してコードを実行できます。Pythonに慣れている場合は、手順は同じです。この実験では、トレーニング分割率を0.7(split_ratio)、シーケンスの長さを10(seq_length)、非表示サイズを70(hidden_size)、エポック数を1000(num_epochs)、および学習率を0.00001(learning_rate)とします。なぜなら、このプロジェクトの目的はハイパーパラメータを最適化することではなく(それには追加のモジュールの使用が必要です)、そのために次のコマンドを実行してトレーニングを開始します:
julia --project src/main.jl --data_file GOOG.csv --split_ratio 0.7 --seq_length 10 --hidden_size 70 --num_epochs 1000 --learning_rate 0.00001モデルは1000エポックでトレーニングされますが、
train_gru関数にはパラメータの最良値を保存するフロー制御があります。
図5はトレーニングイテレーションのコストを示しています。観察できるように、曲線は減少傾向を示し、モデルは最後のイテレーションの周辺で収束しているように見えます。曲線の曲率のため、GRUネットワークのトレーニングのためのエポック数を増やすことでさらなる改善が得られる可能性があります。テストセットの外部評価では、平均二乗誤差(MSE)がおおよそ6.57になります。この値はゼロに近づいているわけではありませんが、ベンチマーク値の比較がないため、最終的な結論を出すことはできません。
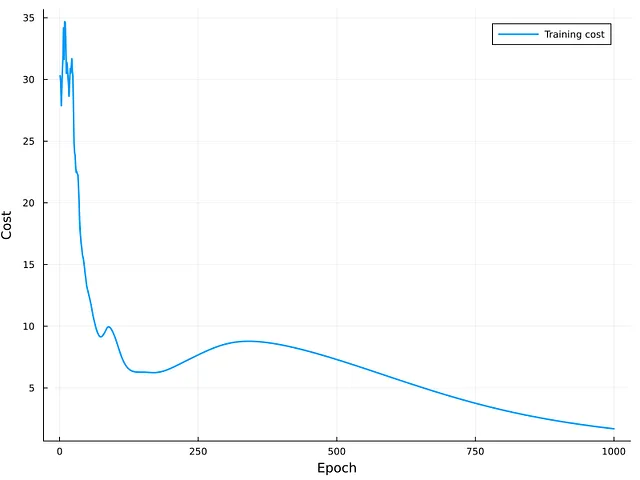
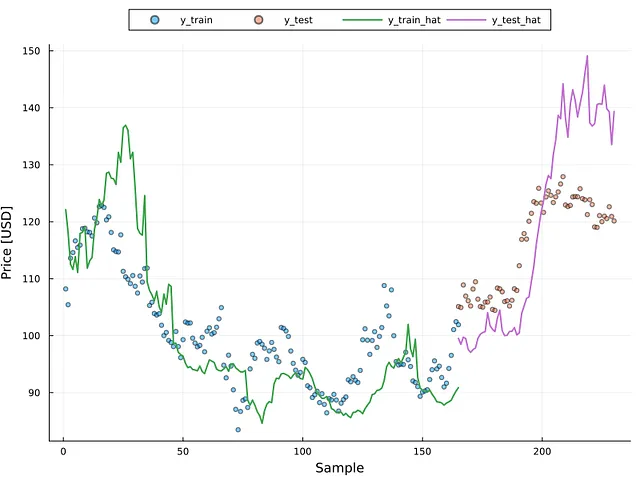
図6は、散布図としてトレーニングデータセットとテストデータセットの実際の値を示し、予測値を連続した線で表示しています(詳細については図の凡例を参照してください)。モデルが実際のポイントの傾向に一致していることは明らかですが、GRUネットワークの性能を向上させるためにはさらなるトレーニングが必要です。それにもかかわらず、特にトレーニング側で、モデルがいくつかのサンプルに過学習していることがいくつかの部分でわかります。トレーニングセットのMSEが約1.70であったことから、モデルには過学習が生じている可能性があります。
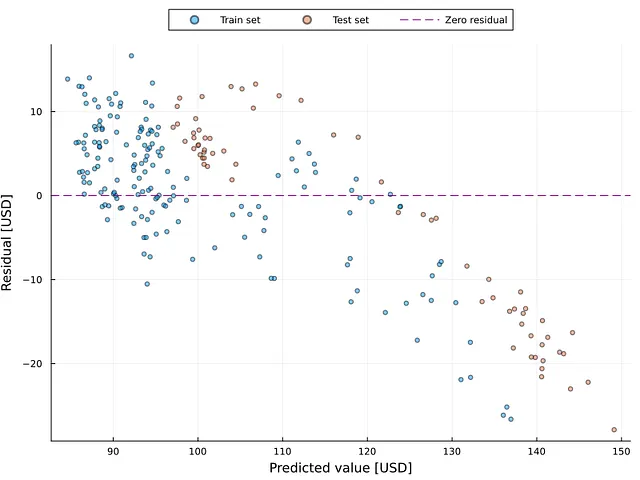
誤差の変動や不安定さは、時系列予測を含む回帰分析の難しさとなる場合があります。データサイエンスや統計学では、これを異分散性と呼びます(詳細については、以下の記事を参照してください👇)。残差プロットは、異分散性を検出するための一つの方法です。図7は、残差プロットを示しており、x軸は予測値を、y軸は残差を表しています。
回帰学習における異分散性と均一分散性
回帰分析における残差の変動性
pub.towardsai.net
ゼロの周りに均等に配置された点は均一分散性(つまり、安定した残差)の存在を示しています。この図は、このシナリオでの異分散性の存在を示しており、高性能なモデルを作成するために問題を修正する方法(例:対数変換)の使用が必要です。図7は、サンプルがトレーニングデータセットからであろうとテストデータセットからであろうと、120ドル以上の範囲で異分散性の存在が明らかであることを示しています。図6はこの点を補強します。図6は、120を超える値が実際の数字から大きく外れていることを示しています。
結論
この記事では、Juliaプログラミング言語を使用してゼロからGRUネットワークを構築しました。プログラムが考慮する数学の方程式や、GRUの実装が成功するための最も重要な理論的な問題を調査しました。データを処理するためのJuliaプログラムの初期設定の作成方法、GRUアーキテクチャの構築方法、モデルのトレーニング方法、モデルの評価方法について説明しました。モデルアーキテクチャの設計に使用される最も重要なコードスニペットについて説明しました。結果を分析するためにプログラムを実行しました。この特定のプロジェクトで異分散性の存在を検出し、この問題を克服し高性能なGRUネットワークを作成するための戦略の調査をお勧めしました。
GitHub上のコードを確認して、Juliaや他のデータサイエンスやプログラミングのトピックに関して何か他のことを見てみたいかどうか教えてください。皆さんの意見やフィードバックは私にとって非常に役立ちます🚀…
追加資料
- ゲート付きリカレントユニット(GRU)
- シーケンスモデルの完全なコース
もし私の記事がお気に入りでしたら、VoAGIで私をフォローして、さらに思考を刺激するコンテンツをお楽しみください。また、この資料を同僚と共有してください。

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
