RGBビデオから3Dビデオを作成する
Creating 3D video from RGB video
任意のRGBビデオから一貫したデプスマップとポイントクラウドのビデオを生成する手順

私たちはデジタルな思い出を2D形式の写真やビデオで保存していますが、それらは鮮明さにもかかわらず、捉えた経験の深さや没入感を欠いています。機械学習モデルが写真やビデオの3D性を理解するほど強力になった現代において、この制限は任意のもののように思えます。
画像やビデオからの3Dデータは、私たちが思い出をより鮮明かつ対話的に体験するだけでなく、編集や後処理の新たな可能性を提供します。シーンからオブジェクトを簡単に削除したり、背景を切り替えたり、さらに視点を変えて瞬間を見ることができると想像してみてください。深度認識処理は、機械学習アルゴリズムに視覚データを理解し操作するための豊かな文脈を提供します。
一貫したビデオのデプスを生成する方法を探している中で、興味深いアプローチを提案した研究論文を見つけました。このアプローチでは、入力ビデオ全体を使用して2つのニューラルネットワークをトレーニングします。デプスを予測する畳み込みニューラルネットワーク(CNN)と、シーン内の動きまたは「シーンフロー」を予測するMLPです。このフローネットワークは、時間の異なる期間に反復的に適用される特別な方法で使用されます。これにより、シーン内の小さな変化と大きな変化の両方を把握できます。小さな変化は、次の瞬間からの移動が3D上でスムーズになるように保証するのに役立ちます。一方、大きな変化は、異なる視点から見た場合にビデオ全体が一貫していることを確認するのに役立ちます。これにより、局所的にもグローバルにも正確な3Dビデオを作成できます。
論文のコードリポジトリは一般に公開されていますが、任意のビデオを処理するためのパイプラインは完全に説明されていませんし、少なくとも私にとっては提案されたパイプラインでどのようにビデオを処理するかが不明でした。このブログ投稿では、そのギャップを埋め、パイプラインをビデオに適用する手順をステップバイステップで説明します。
- 「HuggingFace Diffusersにおける拡散モデルの比較と説明」
- AIに関する最高のコースは、YouTubeのプレイリストを持つ大学から提供されています
- 「NVIDIAの収益報告書がAI革命での優位性を明らかに」
GitHubページで私のコードバージョンを確認することができます。参照してください。
ステップ1:ビデオからフレームを抽出する
パイプラインで最初に行うことは、選択したビデオからフレームを抽出することです。この目的のためにスクリプトを追加しました。スクリプトはscripts/preprocess/custom/extract_frames_from_video.pyで見つけることができます。コードを実行するには、ターミナルで次のコマンドを使用してください:
python extract_frames_from_video.py ^ -- video_path = 'ここにビデオのパスを入力' ^ -- output_dir = '../../../datafiles/custom/JPEGImages/640p/custom/' ^ -- resize_factor = 0.5resize_factor引数を使用すると、フレームをダウンサンプリングまたはアップサンプリングできます。
私はテスト用にこのビデオを選びました。最初は解像度が1280×720でしたが、後続のステップで処理を高速化するために0.5のresize_factorを使用して640×360に縮小しました。
ステップ2:ビデオ内の前景オブジェクトをセグメント化する
プロセスの次のステップでは、ビデオ内の主要な前景オブジェクトのセグメント化または分離が必要です。これは、ビデオ内のカメラの位置と角度を推定するために重要です。なぜなら、カメラに近いオブジェクトは、遠くにあるオブジェクトよりも姿勢推定に大きな影響を与えるからです。例えば、1メートル先のオブジェクトが10センチメートル移動した場合、これは画像で大きな変化をもたらします。しかし、同じオブジェクトが10メートル先にあり、同じ距離を移動した場合、画像の変化はほとんど目立ちません。そのため、ポーズ推定に関連する領域に焦点を当てた「マスク」ビデオを生成し、計算を簡略化します。
私はフレームのセグメンテーションにMask-RCNNを選びました。他のセグメンテーションモデルでも構いません。私のビデオでは、ビデオ全体でフレーム内にいる右側の人物をセグメント化することにしました。
マスクのビデオを生成するには、ビデオ固有の手動調整が必要です。私のビデオでは2人の人物が含まれているため、まずそれぞれの人物のマスクをセグメンテーションしました。その後、右側の人物のマスクをハードコーディングで抽出しました。選択した前景オブジェクトとビデオ内での位置に応じて、アプローチは異なる場合があります。マスクを作成するスクリプトは./render_mask_video.pyにあります。私がマスク選択プロセスを指定しているスクリプトのセクションは次の通りです:
file_names = next(os.walk(IMAGE_DIR))[2] for index in tqdm(range(0, len(file_names))): image = skimage.io.imread(os.path.join(IMAGE_DIR, file_names[index])) # 検出を実行 results = model.detect([image], verbose=0) r = results[0] # 次のforループでは、抽出したフレームが16000ピクセルより大きいか、 # 水平軸で最小の位置が250ピクセル以上かどうかをチェックします。 # そうでない場合、次のマスクを「person」マスクで確認します。 current_mask_selection = 0 while(True): if current_mask_selection<10: if (np.where(r["masks"][:,:,current_mask_selection]*1 == 1)[1].min()<250 or np.sum(r["masks"][:,:,current_mask_selection]*1)<16000): current_mask_selection = current_mask_selection+1 continue elif (np.sum(r["masks"][:,:,current_mask_selection]*1)>16000 and np.where(r["masks"][:,:,current_mask_selection]*1 == 1)[1].min()>250): break else: break mask = 255*(r["masks"][:,:,current_mask_selection]*1) mask_img = Image.fromarray(mask) mask_img = mask_img.convert('RGB') mask_img.save(os.path.join(SAVE_DIR, f"frame{index:03}.png"))元のビデオとマスクされたビデオは、以下のアニメーションで並べて表示されます:

ステップ3:カメラの姿勢と内部パラメータの推定
マスクフレームを作成した後、カメラの姿勢と内部パラメータの計算を行います。これには、Colmapというツールを使用します。これは複数の画像からメッシュを作成し、カメラの動きと内部パラメータを推定するマルチビューステレオビジョンツールです。GUIとコマンドラインインターフェースの両方があります。このリンクからツールをダウンロードできます。
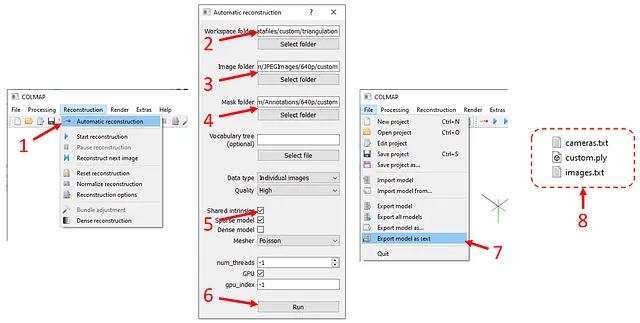
ツールを起動したら、上部バーで「Reconstruction」を押し(以下の図を参照)、次に「Automatic reconstruction」を押します。ポップアップウィンドウで、
- 「Workspace folder」に
./datafiles/custom/triangulationを入力 - 「Image folder」に
./datafiles/custom/JPEGImages/640p/customを入力 - 「Image folder」に
./datafiles/custom/JPEGImages/640p/customを入力 - 「Mask folder」に
./datafiles/custom/Annotations/640p/customを入力 - 「Shared intrinsics」オプションにチェックを入れる
- 「Run」をクリックします。
計算には、画像の数と解像度によって時間がかかる場合があります。計算が終了したら、「File」の下にある「Export model as text」をクリックし、出力ファイルを./datafiles/custom/triangulationに保存します。2つのテキストファイルと1つのメッシュ(.ply)ファイルが作成されます。
このステップはまだ終わっていません、Colmapの出力を処理する必要があります。それを自動化するためにスクリプトを書きました。単純に、ターミナルで次のコマンドを実行してください:
python scripts/preprocess/custom/process_colmap_output.pyこれにより、「custom.intrinsics.txt」、「custom.matrices.txt」、および「custom.obj」が作成されます。
これで、トレーニングのためのデータセット生成に進む準備が整いました。
ステップ4:トレーニング用のデータセットの準備
トレーニングには、各フレームのMiDasによる深度推定、フレーム間のクロスフレームフロー推定、および深度シーケンスを含むデータセットが必要です。これらを作成するためのスクリプトは元のリポジトリで提供されましたが、それらの入力と出力ディレクトリを変更しました。以下のコマンドを実行することで、必要なすべてのファイルが作成され、適切なディレクトリに配置されます:
python scripts/preprocess/custom/generate_frame_midas.py &python scripts/preprocess/custom/generate_flows.py &python scripts/preprocess/custom/generate_sequence_midas.py トレーニングの前に、datafiles/custom_processed/frames_midas/custom、datafiles/custom_processed/flow_pairs/custom、およびdatafiles/custom_processed/sequences_select_pairs_midas/customに.npzファイルと.ptファイルがあるかどうかを確認してください。確認後、トレーニングを進めることができます。
ステップ5:トレーニング
トレーニング部分は簡単です。カスタムデータセットでニューラルネットワークをトレーニングするには、ターミナルで次のコマンドを実行してください:
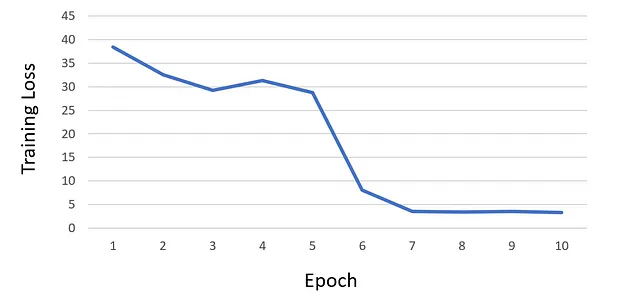
python train.py --net scene_flow_motion_field ^ --dataset custom_sequence --track_id custom ^ --log_time --epoch_batches 2000 --epoch 10 ^ --lr 1e-6 --html_logger --vali_batches 150 ^ --batch_size 1 --optim adam --vis_batches_vali 1 ^ --vis_every_vali 1 --vis_every_train 1 ^ --vis_batches_train 1 --vis_at_start --gpu 0 ^ --save_net 1 --workers 1 --one_way ^ --loss_type l1 --l1_mul 0 --acc_mul 1 ^ --disp_mul 1 --warm_sf 5 --scene_lr_mul 1000 ^ --repeat 1 --flow_mul 1 --sf_mag_div 100 ^ --time_dependent --gaps 1,2,4,6,8 --midas ^ --use_disp --logdir 'logdir/' ^ --suffix 'track_{track_id}' ^ --force_overwrite10エポックのトレーニング後、損失が飽和し始めたため、追加のエポックのトレーニングを続けないことにしました。以下は私のトレーニングの損失曲線グラフです:
トレーニング中、すべてのチェックポイントはディレクトリ./logdir/nets/に保存されます。さらに、各エポック後にトレーニングスクリプトはディレクトリ./logdir/visualizeにテストの可視化を生成します。これらの可視化は、トレーニング中に発生した潜在的な問題を特定するのに特に役立ちます。
ステップ6:トレーニング済みモデルを使用して各フレームの深度マップを作成する
最新のチェックポイントを使用して、test.pyスクリプトで各フレームの深度マップを生成します。ターミナルで次のコマンドを実行してください:
python test.py --net scene_flow_motion_field ^ --dataset custom_sequence --workers 1 ^ --output_dir .\test_results\custom_sequence ^ --epoch 10 --html_logger --batch_size 1 ^ --gpu 0 --track_id custom --suffix custom ^ --checkpoint_path .\logdirこれにより、各フレームごとに1つの.npzファイル(RGBフレーム、深度、カメラポーズ、次の画像へのフローなどで構成される辞書ファイル)と、各フレームの3つの深度レンダリング(正解データ、MiDaS、トレーニングされたネットワークの推定)が生成されます。
ステップ7:ポイントクラウドビデオの作成
最後のステップでは、バッチ処理された.npzファイルをフレームごとに読み込み、深度とRGB情報を使用してカラーのポイントクラウドを作成します。私はPythonでopen3dライブラリを使用してポイントクラウドを作成し、レンダリングします。これは3D空間で仮想カメラを作成し、それらでポイントクラウドのキャプチャを取ることができる強力なツールです。また、ポイントクラウドを編集/操作することもできます。私はopen3dの組み込みの外れ値除去関数を使用して、フリッカーとノイズのあるポイントを除去しました。
このブログ投稿を簡潔に保つため、open3dの具体的な使用方法には深入りしませんが、自己説明的であるはずのrender_pointcloud_video.pyスクリプトを含めました。質問やさらなる説明が必要な場合は、遠慮なくお尋ねください。
以下は、私が処理したビデオのポイントクラウドと深度マップのビデオの見た目です。

このアニメーションの高解像度バージョンはYouTubeにアップロードされています。
深度マップとポイントクラウドは素晴らしいですが、それらをどのように活用できるか疑問に思うかもしれません。深度に応じた効果は、従来の効果の追加方法と比較して非常に強力です。たとえば、深度に応じた処理により、それ以外には難しいさまざまな映画的効果を作成することができます。ビデオの推定深度を使用すると、合成カメラの焦点と非焦点をシームレスに組み込むことができ、リアルで一貫性のあるボケ効果が得られます。
さらに、深度に応じた技術は、「ドリーズーム」と呼ばれる動的効果の実装を可能にします。仮想カメラの位置と内部パラメータを操作することで、この効果を適用して驚くべきビジュアルシーケンスを生成することができます。また、深度に応じたオブジェクトの挿入により、仮想オブジェクトがビデオ内で現実的に固定され、シーン全体で一貫した位置を保ちます。
深度マップとポイントクラウドの組み合わせは、魅力的なストーリーテリングと想像力に満ちたビジュアル効果の世界を解き放ち、映画製作者やアーティストの創造的な可能性を新たな高みに押し上げます。
この記事の「公開」ボタンをクリックした直後に、私は袖をまくってそのような効果を作り始めます。
素晴らしい一日をお過ごしください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





