「LLMsとHugging Faceを使用して独自の翻訳ツールを作成しましょう」
Create your own translation tool using LLMs and Hugging Face.
イントロダクション
言語の壁はグローバルなコミュニケーションを妨げることがありますが、AIと自然言語処理は解決策を提供します。広範なテキストデータでトレーニングされた言語モデル(LLM)は、深い言語理解を持ち、異なる言語を話す人々の間でシームレスな翻訳を可能にします。LLMは従来のルールベースの方法を超え、精度と品質を向上させます。この記事では、LLMと著名な自然言語処理プラットフォームであるHugging Faceを使用して翻訳システムを構築する方法を説明します。
![]()
ライブラリのインストールから使いやすいウェブアプリまで、翻訳システムの作成方法を学びます。LLMを取り入れることで、相互につながった世界で効果的なクロスリンガルコミュニケーションの無限の可能性が開かれます。
学習目標
この記事の終わりまでに、以下のことができるようになります:
- 「ワーグナーのフェスティバルで、新技術がリーダーシップの亀裂を明らかにする」
- 「World of WarcraftのプレイヤーがAIを騙してゲームのウェブサイトにフェイクニュースを掲載させることに成功」
- 「OpenAI、Microsoft、Googleが協力してAI開発の規制を支援する団体を設立」
- Hugging Face transformersとOpenAI Modelsをインポートしてタスクを実行する方法を理解する。
- ユーザーのニーズに合わせて、任意の言語で翻訳システムを構築し、調整することができる。
この記事は、データサイエンスブロガソンの一環として公開されました。
翻訳ツールとその重要性の理解
翻訳ツールは、意味と文脈を保持しながら、テキストを一つの言語から別の言語に変換するツールやシステムです。これらは、異なる言語を話す人々の間のギャップを埋め、グローバルなスケールで効果的なコミュニケーションを可能にします。
翻訳ツールの重要性は、ビジネス、旅行、教育、外交などの様々な領域で明らかです。文書、ウェブサイト、会話の翻訳など、翻訳ツールは文化的な交流を促進し、相互理解を育んでいます。
私は最近、自分の言語が理解できず、相手の言語も理解されないツアーに参加した際に同じ問題に直面しましたが、最終的にはGoogle翻訳でなんとかなりました(笑)
OpenAIとHugging Faceの概要
OpenAIについては説明は不要ですが、人工知能に焦点を当てた研究グループとしてよく知られています。彼らはGPTシリーズや言語モデルAPIなどの言語モデルを作成しました。これらのモデルは、翻訳やその他のNLPの仕事のやり方を変えました。
![]()
Hugging Faceという別のプラットフォームもあり、さまざまなNLPモデルやツールを提供しています。翻訳などの作業には、事前学習済みモデル、ファインチューニングオプション、シンプルなパイプラインなどを提供しています。Hugging Faceは、NLPの開発者や研究者にとって頼りになる情報源として台頭しています。
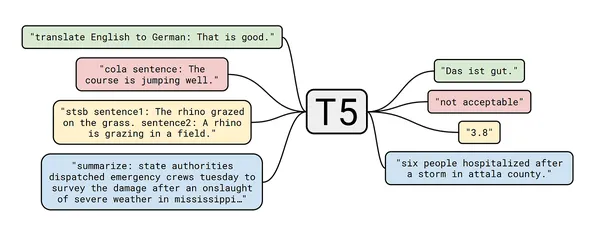
翻訳にLLMを使用する利点
OpenAIのGPTやHugging FaceのT5などの言語モデルは、翻訳の分野を革新しました。翻訳にLLMを使用することのいくつかの利点は以下の通りです:
- 文脈理解:LLMは膨大なテキストデータでトレーニングされており、微妙な意味や文脈を把握することができます。
- 精度向上:LLMは従来のルールベースの方法と比べて翻訳品質が大幅に向上しています。
- 多言語対応:LLMは複数の言語間の翻訳を処理できるため、汎用性があり適応性があります。
- 継続的な学習:LLMは新しいデータでファインチューニングやアップデートが可能であり、翻訳品質を継続的に改善することができます。
それでは、LLMとHugging Faceを使用して翻訳システムを構築する手順について、ステップバイステップで見ていきましょう。
翻訳システムの構築
必要なライブラリのインストール
まず始めに、タスクを実行するために必要なライブラリをインストールする必要があります。
お好きなPython環境を開いてください(私はこれをベース環境で行っています)。python -m venv “env name” と入力して新しい環境を作成することもできます。Hugging Faceから読み込むために、transformersとdatasetsをインストールします。これらのコマンドをJupyterノートブックやターミナルで実行することができます。
%pip install sacremoses==0.0.53
%pip install datasets
%pip install transformers
%pip install torch torchvision torchaudio
%pip install "transformers[sentencepiece]"Hugging Faceを使用したT5-Smallモデルのセットアップ
前述の通り、このプロジェクトではHugging Faceのモデルを使用します。具体的には、テキスト翻訳にT5-Smallモデルを使用します。Hugging FaceのTranslatorモデルには他のモデルもありますが、ここではT5-Smallモデルに焦点を当てます。以下のコードを使用してセットアップします:
T5-Smallのセットアップ前に、インストールしたライブラリをいくつかインポートします。
# ライブラリをインポートする
from datasets import load_dataset
from transformers import pipelineモデルをcache_dirに保存しており、繰り返しダウンロードする必要はありません。
# T5-smallモデルのパイプラインを作成し、cache_dirに保存する
t5_small_pipeline = pipeline(
task="text2text-generation",
model="t5-small",
max_length=50,
model_kwargs={"cache_dir": '/Users/tarakram/Documents/Translate/t5_small' },
)T5-Smallを使用したテキストの翻訳
さあ、T5-Smallモデルを使用してテキストを翻訳しましょう:
注意:T5-Smallモデルの欠点は、すべての言語をサポートしていないことです。ただし、このガイドではプロジェクトで翻訳モデルを使用するプロセスをデモンストレーションします。
# 英語からルーマニア語へ
t5_small_pipeline(
"translate English to Romanian : Hey How are you ?"
)
# 英語からスペイン語へ
t5_small_pipeline(
"translate English to Spanish: Hey How are you ?"
)
# モデルが多くの言語に対応していないことを知っているので、
# 一部の言語に限定されていますt5_small_pipelineは、指定されたターゲット言語で指定されたテキストの翻訳を生成します。
OpenAIのLLMsを使用した翻訳の向上
T5-Smallモデルは複数の言語をカバーしていますが、OpenAIのLLMsを活用することで翻訳の品質を向上させることができます。これを行うには、OpenAIのAPIキーが必要です。キーを取得したら、以下のコードを使用して進めることができます:
# ライブラリをインポートする
import openai
from secret_key import openapi_key
import os
# ここにOpenAIキーを入力してください
os.environ['OPENAI_API_KEY'] = openapi_key
# テキストを入力し、ソース言語とターゲット言語を尋ねる関数を作成する
def translate_text(text, source_language, target_language):
response = openai.Completion.create(
engine='text-davinci-002',
prompt=f"Translate the following text from {source_language} to {target_language}:\n{text}",
max_tokens=100,
n=1,
stop=None,
temperature=0.2,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
)
translation = response.choices[0].text.strip().split("\n")[0]
return translation
# ユーザー入力を取得する
text = input("翻訳するテキストを入力してください:")
source_language = input("ソース言語を入力してください:")
target_language = input("ターゲット言語を入力してください:")
translation = translate_text(text, source_language, target_language)
# 翻訳されたテキストを表示する
print(f'翻訳されたテキスト:{translation}')提供されたコードは、OpenAIのLLMsを使用した翻訳関数を設定しています。翻訳のためにOpenAI APIにリクエストを送信し、翻訳されたテキストを取得します。
Streamlitを使用した翻訳Webアプリケーションの作成
翻訳をユーザーフレンドリーなインターフェースで利用できるようにするために、Streamlitを使用して翻訳Webアプリケーションを作成することができます。以下はコードの例です:
# ライブラリをインポートする
import streamlit as st
import os
import openai
from secret_key import openapi_key
# ここにOpenAIキーを入力してください
os.environ['OPENAI_API_KEY'] = openapi_key
# 利用可能な言語のリストを定義する
languages = [
"英語",
"ヒンディー語",
"フランス語",
"テルグ語",
"アルバニア語",
"ベンガル語",
"ボージュプリ語",
# 必要に応じて他の言語を追加することができます
]
# 関数を作成する。
def translate_text(text, source_language, target_language):
response = openai.Completion.create(
engine='text-davinci-002',
prompt=f"Translate the following text from {source_language}
to {target_language}:\n{text}",
max_tokens=100,
n=1,
stop=None,
temperature=0,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0
)
translation = response.choices[0].text.strip().split("\n")[0]
return translation
# Streamlitウェブアプリ
def main():
st.title("テキストを翻訳する")
# テキスト入力
text = st.text_area("翻訳するテキストを入力してください")
# ソース言語のドロップダウンで言語を選択する
source_language = st.selectbox("ソース言語を選択してください", languages)
# ターゲット言語のドロップダウンで言語を選択する
target_language = st.selectbox("ターゲット言語を選択してください", languages)
# 翻訳ボタンで翻訳する
if st.button("翻訳する"):
translation = translate_text(text, source_language, target_language)
st.markdown(f'<p style="color: blue; font-size: 25px;">
{translation}</p>', unsafe_allow_html=True)
if __name__ == '__main__':
main()このコードは、Streamlitライブラリを使用してWebアプリケーションを作成します。ユーザーは翻訳するテキストを入力し、ソース言語とターゲット言語を選択し、「翻訳」ボタンをクリックして翻訳を取得することができます。以下は、慣れるためのいくつかの出力例です。
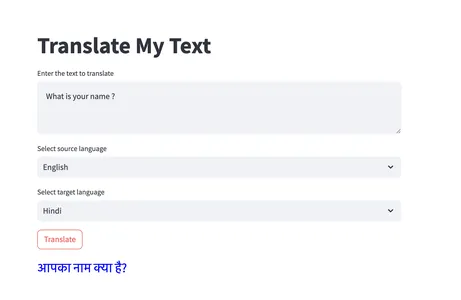
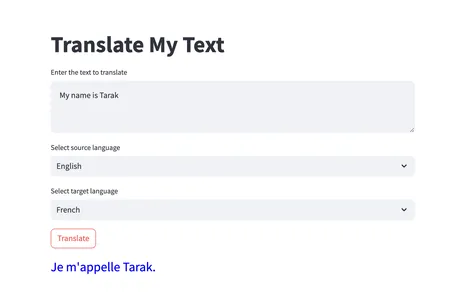
翻訳は様々な方法で使用されています。以下は、実世界のアプリケーションにおける翻訳の成功事例の一部です:
- Google翻訳は、LLMを利用して複数の言語間で正確な翻訳を提供する広く利用されている翻訳サービスです。
- DeepL翻訳は、高品質な翻訳で知られており、LLMを活用して正確で自然な結果を実現しています。
- Facebookの翻訳システムは、プラットフォーム上の異なる言語間でのシームレスなコミュニケーションを実現するためにLLMを利用しています。
- 自動音声翻訳システムは、LLMを活用してリアルタイムの口頭言語翻訳を実現し、国際会議やテレビ会議などに利益をもたらしています。
結論
この記事では、Hugging FaceとOpenAIのLLMを使用して翻訳システムを作成する手順をまとめています。それは現代の世界における翻訳者の価値と、言語の壁を取り払い効率的なグローバルコミュニケーションを促進する利点を強調しています。あなたもHugging FaceのようなLLMとプラットフォームを活用して、自分自身の翻訳システムを開発することができます。
重要なポイント
- OpenAIのGPT-3や4、Hugging FaceのT5などの言語モデルは、翻訳の分野を変革しました。これらのモデルは、文脈理解、改善された精度、多言語サポート、および文脈に基づいた学習と適応能力を提供します。
- Hugging Faceを使用すると、事前学習済みモデルに簡単にアクセスし、特定のタスクに適応させることができます。また、翻訳を含むさまざまなNLPタスクに対して使用できるパイプラインも利用できます。
- LLMを活用して翻訳システムを構築することで、グローバルな理解を促進し、異文化間のコミュニケーションを容易にし、さまざまな領域での協力と交流を促進することができます。
プロジェクトのリンクはこちら – GitHub
私との連絡先はこちら – Linkedin
よくある質問
この記事に表示されているメディアはAnalytics Vidhyaの所有ではありません。著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- アマゾンは、医師の診察内容を要約し、ファイルを管理するための新しい生成型AIツール、HealthScribeを発表しました
- スポティファイはAIを取り入れる:個人に合わせたプレイリストからオーディオ広告まで
- 「アマゾン対Google対マイクロソフト:AIで医療を革新する競争」
- 「LangChainとOpenAI APIを使用した生成型AIアプリケーションの構築」
- OpenAIのCEOであるSam Altman氏:AIの力が証明されるにつれて、仕事に関するリスクが生じる
- 「4つのテック巨人 – OpenAI、Google、Microsoft、Anthropicが安全なAIのために結集」
- 「Amazon SageMaker StudioでAmazon SageMaker JumpStartを使用して安定したDiffusion XLを利用する」





