Substraを使用してプライバシーを保護するAIの作成
Create AI with Substra to protect privacy.
最近、生成技術の台頭により、機械学習はその歴史の中でも非常に興奮する時期にあります。この台頭を支えるモデルは、効果的な結果を生み出すためにさらに多くのデータを必要とします。そのため、データの倫理的な収集方法を探求することがますます重要になってきています。また、データのプライバシーとセキュリティを最優先にすることも重要です。
医療などの機密情報を扱う多くの領域では、データハングリーなモデルを訓練するために十分な高品質なデータにアクセスできることがしばしばありません。データセットは異なる学術センターや医療機関に分断され、患者情報や独自の情報のプライバシー上の懸念から、公開共有することが難しい状況にあります。HIPAAなどの患者データを保護する規制は、個人の健康情報を保護するために不可欠ですが、データサイエンティストがモデルを効果的に訓練するために必要なデータのボリュームにアクセスできないため、機械学習の研究の進展を制限することがあります。既存の規制と協調して患者データを積極的に保護する技術は、これらの分断を解除し、これらの領域での機械学習の研究と展開のスピードを加速するために重要となります。
ここでフェデレーテッドラーニングが登場します。Substraと共に作成したこのスペースをチェックして、詳細をご覧ください!
フェデレーテッドラーニングとは何ですか?
フェデレーテッドラーニング(FL)は、複数のデータプロバイダを使用してモデルを訓練できる分散型の機械学習技術です。すべてのソースからデータを単一のサーバーに収集するのではなく、データはローカルサーバーに残り、結果のモデルの重みのみがサーバー間を移動します。
- トランスフォーマーによるグラフ分類
- AWS Inferentia2を使用してHugging Face Transformersを高速化する
- 中国語話者向けのHuggingFaceブログをご紹介します:中国のAIコミュニティとの協力の促進
データが元のソースから出ないため、フェデレーテッドラーニングは自然にプライバシーを最優先とするアプローチです。この技術はデータのセキュリティとプライバシーを向上させるだけでなく、データ科学者が異なるソースのデータを使用してより良いモデルを構築することも可能にします。これにより、データの量の増加だけでなく、データキャプチャ技術や装置によるわずかな違い、または患者集団の人口統計の違いなど、基になるデータセットのバリエーションによるバイアスのリスクを軽減することができます。複数のデータソースを持つことで、現実の世界でより優れた性能を発揮するより汎用性のあるモデルを構築することができます。フェデレーテッドラーニングについての詳細については、Googleの説明漫画をチェックすることをお勧めします。

Substraは、現実のプロダクション環境向けに構築されたオープンソースのフェデレーテッドラーニングフレームワークです。フェデレーテッドラーニングは比較的新しい分野であり、過去10年間にのみ確立されてきましたが、既に医学研究の進展を以前にも増して可能にしています。たとえば、10の競合するバイオファーマ企業が、通常は互いにデータを共有しないような状況で、MELLODDYプロジェクトで協力し、世界最大の既知の生化学的または細胞活性を持つ小分子のコレクションを共有しました。これにより、関係するすべての企業が薬剤探索のためのより正確な予測モデルを構築することができました。これは医学研究における重要なマイルストーンです。
Substra x HF
フェデレーテッドラーニングの能力に関する研究は急速に進んでいますが、最近の作業の大部分はシミュレートされた環境に限定されています。実世界の例や実装は、フェデレーテッドネットワークの展開と設計の難しさのためにまだ限られています。フェデレーテッドラーニング展開のためのリーディングオープンソースプラットフォームとして、Substraは多くの複雑なセキュリティ環境とITインフラストラクチャで戦闘テストされ、乳がん研究での医学的なブレークスルーを実現しています。
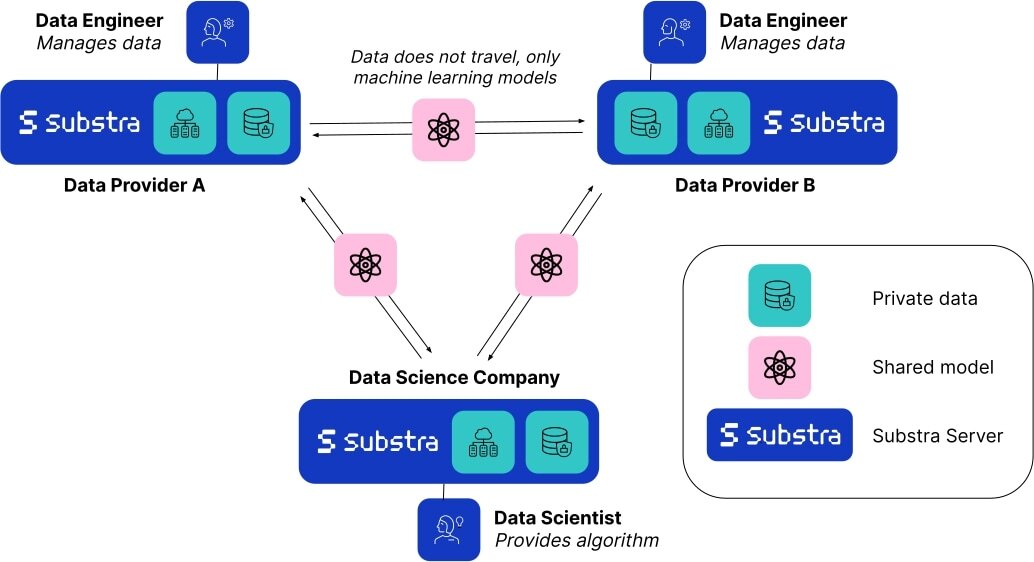
Hugging Faceは、Substraを管理しているチームと協力して、このスペースを作成しました。これは、研究者や科学者が直面する現実の課題、つまり「AIに適した」集中化された高品質データの不足を理解するためのものです。これらのサンプルの分布を制御できるため、単純なモデルがデータの変化にどのように反応するかを確認することができます。その後、フェデレーテッドラーニングで訓練されたモデルが、単一のソースのデータから訓練されたモデルと比較して、ほとんど常に検証データで優れたパフォーマンスを発揮するかどうかを調べることができます。
結論
フェデレーテッドラーニングがリードをしているものの、セキュアなエンクレーブやマルチパーティ計算などのさまざまなプライバシー強化技術(PET)もあり、フェデレーションと組み合わせてマルチレイヤのプライバシー保護環境を作成することができます。これらが医療分野での協力を可能にしている方法に興味がある場合は、こちらをご覧ください。
使用される方法に関係なく、データプライバシーは私たち全員の権利であることに注意することが重要です。AIブームをプライバシーと倫理に念頭に置いて前進することが重要です。
もしSubstraを試してみて、プロジェクトでフェデレーテッドラーニングを実装したい場合は、こちらのドキュメントをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






