「Amazon SageMaker JumpStart、Llama 2、およびAmazon OpenSearch Serverless with Vector Engineを使用して、金融サービス向けのコンテキスト重視のチャットボットを構築する」
「金融サービス向けのコンテキスト重視チャットボットを構築:Amazon SageMaker JumpStart、Llama 2、およびAmazon OpenSearch Serverless with Vector Engineを活用」
金融サービス(FinServ)業界は、ドメイン固有のデータ、データセキュリティ、規制管理、業界のコンプライアンス基準に関連する独自の生成型AI要件を持っています。さらに、顧客は、最もパフォーマンスが高く費用効果の高い機械学習(ML)モデルを選択し、必要なカスタマイズ(ファインチューニング)を行うための選択肢を求めています。Amazon SageMaker JumpStartは、必要なデータセキュリティコントロールを提供し、コンプライアンス基準要件を満たしているため、FinServ顧客向けの生成型AIユースケースに理想的な製品です。
本記事では、SageMaker JumpStartを使用して、大規模言語モデル(LLM)と情報検索(IR)システムを組み合わせたリトリーバル増強生成(RAG)ベースのアプローチを使用して、質問応答タスクを実証します。 RAGは、LLMとIRシステムを組み合わせることでテキスト生成の品質を向上させるためのフレームワークです。 LLMが生成したテキストは、IRシステムによってナレッジベースから関連情報を取得します。 取得された情報は、モデルが生成したテキストの精度と関連性を向上させるのに役立ちます。 RAGは、質問応答や要約など、さまざまなテキスト生成タスクで効果があることが示されています。 テキスト生成モデルの品質と正確さを向上させる有望な手法です。
SageMaker JumpStartの利点
SageMaker JumpStartでは、コンテンツ作成、画像生成、コード生成、質問応答、コピーライティング、要約、分類、情報検索などのユースケースに対して、幅広い先進的なモデルから選択できます。MLプラクティショナーは、SageMakerを使用してモデルのトレーニングと展開を行い、ネットワーク隔離環境から専用のAmazon SageMakerインスタンスに基本モデルを展開することができます。
SageMaker JumpStartは、次のような生成型AIユースケースに理想的です。
- 「カスタムレンズを使用して、優れたアーキテクチャのIDPソリューションを構築する – パート1:運用の優秀さ」
- AIパワードテックカンパニーが、食品小売業者に供給チェーン管理での新たなスタートを支援します
- 音声合成:進化、倫理、そして法律
- カスタマイズ可能性 – SageMaker JumpStartは、基礎モデルのドメイン適応に関するステップバイステップのガイダンスや詳細な記事の例ノートブックを提供しています。 これらのリソースに従って、ファインチューニング、ドメイン適応、および基礎モデルの指導を行うか、RAGベースのアプリケーションを構築することができます。
- データのセキュリティ – 推論ペイロードデータのセキュリティを確保することが最優先事項です。 SageMaker JumpStartを使用すると、シングルテナンシーのエンドポイントプロビジョンでネットワーク隔離されたモデルを展開できます。 さらに、プライベートモデルハブ機能を通じて、選択したモデルへのアクセス制御を管理することができ、個々のセキュリティ要件に合わせることができます。
- 規制コントロールとコンプライアンス – HIPAA BAA、SOC123、PCI、HITRUST CSFなどの基準を満たすことは、SageMakerの核となる機能であり、金融業界の厳格な規制環境に合致しています。
- モデルの選択肢 – SageMaker JumpStartは、業界で認識されるHEL Mベンチマークで常にトップにランクされる最先端のMLモデルの選択肢を提供しています。 これには、Llama 2、Falcon 40B、AI21 J2 Ultra、AI21 Summarize、Hugging Face MiniLM、BGEモデルなどが含まれます。
本記事では、Llama 2基本モデルとHugging Face GPTJ-6B-FP16埋め込みモデルを使用して、SageMaker JumpStartで金融サービス組織のためのコンテキストチャットボットを構築する方法を探ります。 ベクトルデータストアとして、SageMaker JumpStartで利用できるVector EngineおよびAmazon OpenSearch Serverless(現在プレビュー中)も使用します。
大規模言語モデルの制約事項
LLMは膨大な量の非構造化データで訓練され、一般的なテキスト生成で優れた性能を発揮します。このトレーニングにより、LLMは事実の知識を獲得して保存します。ただし、既製のLLMには以下の制約があります:
- オフライントレーニングにより、最新の情報には気付かないことがあります。
- 一般化されたデータでのトレーニングにより、ドメイン固有のタスクでの効果が低下します。 たとえば、金融機関は、最新の内部文書から回答を取得するQ&Aボットを好む場合があります。これにより、正確性とビジネスルールとのコンプライアンスが確保されます。
- 埋め込まれた情報に依存するため、解釈可能性が低下します。
LLMsの特定のデータを使用するためには、3つの主要な方法が存在します:
- モデルのプロンプト内にデータを埋め込み、出力生成中にこのコンテキストを利用することができます。これはゼロショット(例なし)、フューショット(限られた例)、またはマニーショット(豊富な例)で行うことができます。このようなコンテキストプロンプティングによって、モデルはより微妙な結果に向かいます。
- プロンプトとコンプリーションのペアを使用してモデルをファインチューニングします。
- RAGは、外部データ(非パラメトリック)を取得し、これをプロンプトに統合してコンテキストを豊かにします。
ただし、最初の方法はコンテキストのサイズに関するモデル制約に苦しんでおり、長いドキュメントを入力するのが困難になり、コストが増加する可能性があります。ファインチューニングアプローチは強力ですが、リソースが多く必要であり、特に進化し続ける外部データの場合は展開が遅れ、コストが増加します。RAGはLLMsと組み合わせることで、先に述べた制限に対する解決策を提供します。
検索増強生成
RAGは、外部データ(非パラメトリック)を取得し、MLプロンプトにこのデータを統合してコンテキストを豊かにします。Lewisらは2020年にRAGモデルを導入し、これを事前トレーニングされたシーケンス・トゥ・シーケンスモデル(パラメトリックメモリ)とWikipediaの密なベクトルインデックス(非パラメトリックメモリ)の融合として概念化しました。これには神経リトリーバーを介してアクセスされます。
RAGの動作は次のようになります:
- データソース – RAGはドキュメントリポジトリ、データベース、またはAPIなど、さまざまなデータソースから引用することができます。
- データのフォーマット – ユーザーのクエリとドキュメントは、関連性の比較に適した形式に変換されます。
- 埋め込み – この比較を容易にするために、クエリとドキュメントコレクション(または知識ライブラリ)は、言語モデルを使用して数値の埋め込みに変換されます。これらの埋め込みはテキストの概念を数値的に表現します。
- 関連性検索 – ユーザークエリの埋め込みは、ドキュメントコレクションの埋め込みと比較され、埋め込み空間での類似性検索によって関連するテキストが特定されます。
- コンテキストの充実 – 特定された関連するテキストは、ユーザーの元のプロンプトに追加され、そのコンテキストが強化されます。
- LLM処理 – 充実したコンテキストを使用して、プロンプトはLLMに供給され、関連性の高い正確な出力が生成されます。
- 非同期の更新 – 参照ドキュメントが最新であることを保証するため、埋め込み表現とともに非同期にアップデートすることができます。これにより、将来のモデルの応答が最新の情報に基づいていることが保証され、正確性が確保されます。
要するに、RAGはリアルタイムかつ関連性の高い情報をLLMsに注入するための動的な手法を提供し、正確でタイムリーな出力を生成します。
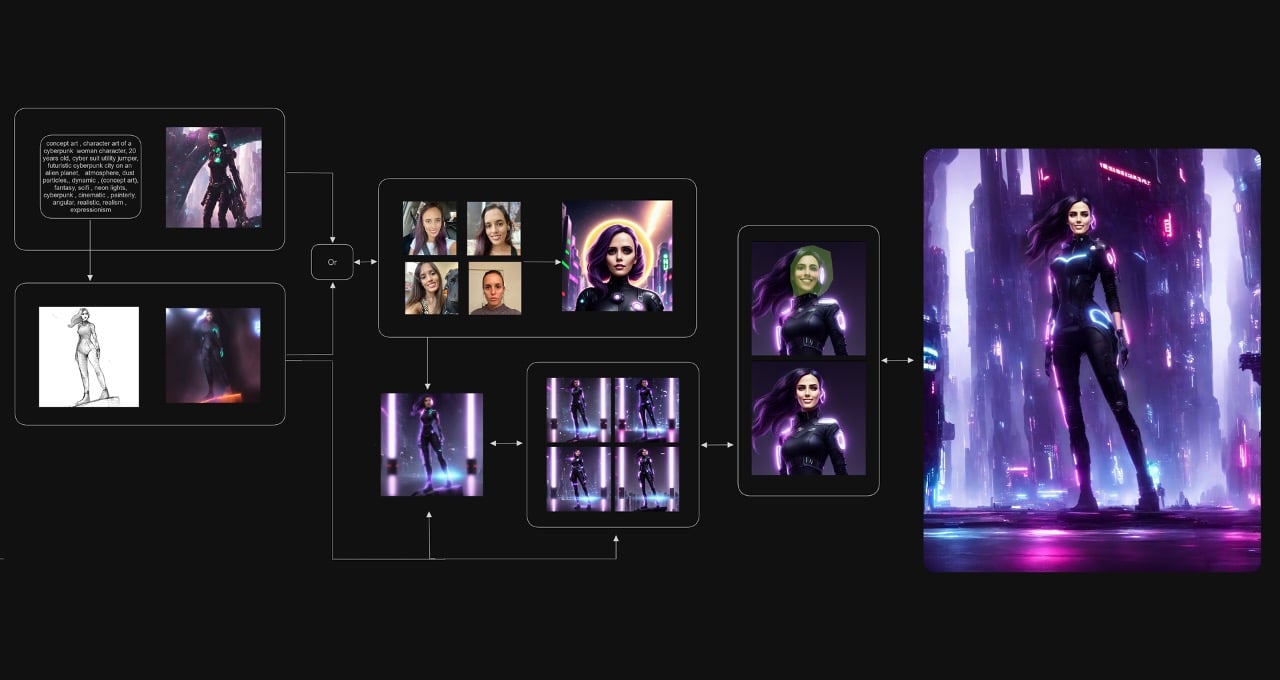
次の図は、LLMsとRAGを使用した概念的なフローを示しています。

ソリューションの概要
金融サービスアプリケーションのためのコンテキストに基づいた質問応答チャットボットを作成するには、次のステップが必要です:
- SageMaker JumpStart GPT-J-6B埋め込みモデルを使用して、Amazon Simple Storage Service(Amazon S3)のアップロードディレクトリ内の各PDFドキュメントに対して埋め込みを生成します。
- 次の手順を使用して関連するドキュメントを特定します:
- 同じモデルを使用してユーザーのクエリの埋め込みを生成します。
- OpenSearch Serverlessとベクトルエンジン機能を使用して、埋め込み空間で最も関連性の高いドキュメントインデックスの上位K個を検索します。
- 特定されたインデックスを使用して対応するドキュメントを取得します。
- 取得したドキュメントをユーザーのプロンプトと質問とともにコンテキストとして組み合わせ、SageMaker LLMに転送して応答を生成します。
このプロセスを調整するために、一般的に使用されているLangChainフレームワークを使用します。LangChainは、LLMsによって強化されたアプリケーションを支援するために特別に設計されており、さまざまなLLMsに対して汎用のインターフェースを提供します。これにより、複数のLLMsの統合が効率化され、コール間の状態の永続性が確保されます。さらに、カスタマイズ可能なプロンプトテンプレート、包括的なアプリケーションビルディングエージェント、および検索とリトリーバルのための特化したインデックスなどの機能により、開発者の効率が向上します。詳細については、前提条件
以下の前提条件を満たす必要があります:
- AWSのアカウントと適切なAWS Identity and Access Management (IAM) の権限。
- Amazon SageMaker Studio ドメインとユーザー。セットアップ手順については、クイックセットアップを使用したAmazon SageMakerドメインへの参加を参照してください。
- OpenSearchサーバーレスのコレクション。
- OpenSearchサーバーレスへのアクセス権を持つSageMaker実行ロール。
OpenSearchサーバーレスのベクトルエンジンのセットアップ方法については、Amazon OpenSearchサーバーレスのベクトルエンジンをご紹介します(プレビュー版)を参照してください。
このソリューションの包括的な手順については、GitHubリポジトリをクローンし、Jupyterノートブックを参照してください。
SageMaker JumpStartを使用してMLモデルをデプロイする
MLモデルをデプロイするには、以下の手順を実行します:
-
SageMaker JumpStartからLlama 2 LLMをデプロイします:
from sagemaker.jumpstart.model import JumpStartModel llm_model = JumpStartModel(model_id = "meta-textgeneration-llama-2-7b-f") llm_predictor = llm_model.deploy() llm_endpoint_name = llm_predictor.endpoint_name -
GPT-J埋め込みモデルをデプロイします:
embeddings_model = JumpStartModel(model_id = "huggingface-textembedding-gpt-j-6b-fp16") embed_predictor = embeddings_model.deploy() embeddings_endpoint_name = embed_predictor.endpoint_name
データをチャンク化し、ドキュメント埋め込みオブジェクトを作成する
このセクションでは、データを小さなドキュメントに分割します。チャンク化は、大きなテキストを小さなチャンクに分割する技術です。検索クエリの関連性を最適化し、それによってチャットボットの品質を向上させるために、このステップは重要です。チャンクサイズは、ドキュメントの種類や使用するモデルなどの要素に応じて決定されます。パラグラフの大きさに近いサイズであるチャンクchunk_size=1600を選択しました。モデルが改善されるにつれて、コンテキストウィンドウサイズが大きくなり、より大きなチャンクサイズが可能になります。
完全なソリューションについては、GitHubリポジトリのJupyterノートブックを参照してください。
-
カスタム埋め込み関数を使用し、gpt-j-6b-fp16 SageMakerエンドポイントを使用するLangChainの
SageMakerEndpointEmbeddingsクラスを拡張します(これは、埋め込みモデルを使用するために以前に作成したエンドポイントの一部です):from langchain.embeddings import SagemakerEndpointEmbeddings from langchain.embeddings.sagemaker_endpoint import EmbeddingsContentHandler logger = logging.getLogger(__name__) # LangChainを拡張してカスタム埋め込み機能を提供するためにSagemakerEndpointEmbeddingsクラスを拡張します class SagemakerEndpointEmbeddingsJumpStart(SagemakerEndpointEmbeddings): def embed_documents( self, texts: List[str], chunk_size: int = 1 ) → List[List[float]]: """SageMaker Inference Endpointを使用してドキュメントの埋め込みを計算します。 Args: texts: 埋め込みを行うテキストのリスト。 chunk_size: リクエストとしてまとめて送信されるテキストの数を指定します。Noneの場合、クラスで指定されたチャンクサイズが使用されます。 Returns: テキストごとの埋め込みのリスト。 """ results = [] _chunk_size = len(texts) if chunk_size > len(texts) else chunk_size st = time.time() for i in range(0, len(texts), _chunk_size): response = self._embedding_func(texts[i : i + _chunk_size]) results.extend(response) time_taken = time.time() - st logger.info( f"got results for {len(texts)} in {time_taken}s, length of embeddings list is {len(results)}" ) print( f"got results for {len(texts)} in {time_taken}s, length of embeddings list is {len(results)}" ) return results # リクエスト/レスポンスをシリアライズ/デシリアライズするためのクラス class ContentHandler(EmbeddingsContentHandler): content_type = "application/json" accepts = "application/json" def transform_input(self, prompt: str, model_kwargs={}) → bytes: input_str = json.dumps({"text_inputs": prompt, **model_kwargs}) return input_str.encode("utf-8") def transform_output(self, output: bytes) → str: response_json = json.loads(output.read().decode("utf-8")) embeddings = response_json["embedding"] if len(embeddings) == 1: return [embeddings[0]] return embeddings def create_sagemaker_embeddings_from_js_model( embeddings_endpoint_name: str, aws_region: str ) → SagemakerEndpointEmbeddingsJumpStart: content_handler = ContentHandler() embeddings = SagemakerEndpointEmbeddingsJumpStart( endpoint_name=embeddings_endpoint_name, region_name=aws_region, content_handler=content_handler, ) return embeddings -
埋め込みオブジェクトを作成し、ドキュメント埋め込みの作成をバッチ処理します:
embeddings = create_sagemaker_embeddings_from_js_model(embeddings_endpoint_name, aws_region) -
これらの埋め込みは、LangChain
OpenSearchVectorSearchを使用してベクトルエンジンに保存されます。これらの埋め込みをOpenSearch Serverlessのドキュメント埋め込みに保存します。チャンクされたドキュメントを反復処理し、埋め込みを作成し、これらの埋め込みをベクトルサーチコレクションで作成したOpenSearch Serverlessベクトルインデックスに保存します。次のコードを参照してください:docsearch = OpenSearchVectorSearch.from_texts(texts = [d.page_content for d in docs],embedding=embeddings,opensearch_url=[{'host': _aoss_host, 'port': 443}],http_auth=awsauth,timeout = 300,use_ssl = True,verify_certs = True,connection_class = RequestsHttpConnection,index_name=_aos_index)
ドキュメントの質問と回答
これまで、大きなドキュメントを小さなドキュメントに分割し、ベクトル埋め込みを作成し、ベクトルエンジンに保存しました。これにより、このドキュメントデータに関する質問に答えることができます。データの索引を作成したため、意味的な検索ができます。この方法では、質問に答えるために必要な関連性の高いドキュメントのみがプロンプト経由でLLMに渡されます。これにより、関連するドキュメントのみをLLMに渡すことで、時間とお金を節約することができます。ドキュメントチェーンの詳細については、ドキュメントを参照してください。
次の手順を実行して、ドキュメントを使用して質問に答えます:
-
SageMaker LLMエンドポイントをLangChainと一緒に使用するには、
langchain.llms.sagemaker_endpoint.SagemakerEndpointを使用します。これにより、SageMaker LLMエンドポイントが抽象化されます。以下のコードのように、リクエストとレスポンスのペイロードの変換を実行します。ただし、使用するLLMモデルのcontent_typeとaccepts形式に応じて、ContentHandler内のコードを調整する必要がある場合があります。content_type = "application/json"accepts = "application/json"def transform_input(self, prompt: str, model_kwargs: dict) → bytes: payload = { "inputs": [ [ { "role": "system", "content": prompt, }, {"role": "user", "content": prompt}, ], ], "parameters": { "max_new_tokens": 1000, "top_p": 0.9, "temperature": 0.6, }, } input_str = json.dumps( payload, ) return input_str.encode("utf-8")def transform_output(self, output: bytes) → str: response_json = json.loads(output.read().decode("utf-8")) content = response_json[0]["generation"]["content"] return contentcontent_handler = ContentHandler()sm_jumpstart_llm=SagemakerEndpoint( endpoint_name=llm_endpoint_name, region_name=aws_region, model_kwargs={"max_new_tokens": 300}, endpoint_kwargs={"CustomAttributes": "accept_eula=true"}, content_handler=content_handler, )
これで、金融ドキュメントと対話する準備が整いました。
-
次のクエリとプロンプトテンプレートを使用して、ドキュメントに関する質問をします:
from langchain import PromptTemplate, SagemakerEndpointfrom langchain.llms.sagemaker_endpoint import LLMContentHandlerquery = "Summarize the earnings report and also what year is the report for"prompt_template = """Only use context to answer the question at the end. {context} Question: {question}Answer:"""prompt = PromptTemplate( template=prompt_template, input_variables=["context", "question"]) class ContentHandler(LLMContentHandler): content_type = "application/json" accepts = "application/json" def transform_input(self, prompt: str, model_kwargs: dict) → bytes: payload = { "inputs": [ [ { "role": "system", "content": prompt, }, {"role": "user", "content": prompt}, ], ], "parameters": { "max_new_tokens": 1000, "top_p": 0.9, "temperature": 0.6, }, } input_str = json.dumps( payload, ) return input_str.encode("utf-8") def transform_output(self, output: bytes) → str: response_json = json.loads(output.read().decode("utf-8")) content = response_json[0]["generation"]["content"] return contentcontent_handler = ContentHandler() chain = load_qa_chain( llm=SagemakerEndpoint( endpoint_name=llm_endpoint_name, region_name=aws_region, model_kwargs={"max_new_tokens": 300}, endpoint_kwargs={"CustomAttributes": "accept_eula=true"}, content_handler=content_handler, ), prompt=prompt,)sim_docs = docsearch.similarity_search(query, include_metadata=False)chain({"input_documents": sim_docs, "question": query}, return_only_outputs=True)
後始末
今後の費用を回避するために、このノートブックで作成したSageMaker推論エンドポイントを削除してください。SageMaker Studioノートブックで以下を実行することで削除できます:
# 削除LLMllm_predictor.delete_model()llm_predictor.delete_predictor(delete_endpoint_config=True)# 埋め込みモデルの削除embed_predictor.delete_model()embed_predictor.delete_predictor(delete_endpoint_config=True)この例のために作成したOpenSearch Serverlessコレクションをもはや不要であれば、OpenSearch Serverlessコンソールを使用して削除できます。
結論
この記事では、RAGを使用してLLMにドメイン固有のコンテキストを提供する方法について説明しました。SageMaker JumpStartを使用して、Llama 2とOpenSearch Serverlessをベクトルエンジンとして使用した金融サービス機関向けのRAGベースのコンテキストチャットボットを構築する方法を示しました。この方法では、Llama 2を使用してテキスト生成を洗練すると同時に、関連するコンテキストを動的に取得します。SageMaker JumpStartで独自のデータを持ち込んで、このRAGベースの戦略でイノベーションを行うことを心待ちにしています!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 大規模な言語モデルをマスターするための包括的な資源リスト
- 「OpenAgents:野生の言語エージェントのためのオープンプラットフォーム」
- 「LeNetのマスタリング:アーキテクチャの洞察と実践的な実装」
- マストゥゴにお会いしましょう:ディフュージョンに基づいた音楽ドメイン知識に触発されたテキストから音楽へのシステムですタンゴのテキストからオーディオへのモデルを拡張します
- エコジェンに会ってください:生物学者や生態学者のためにリアルな鳥の歌を生成するために設計された新しいディープラーニングのアプローチ
- 「Amazon Textractの新しいレイアウト機能は、一般的な目的と生成型のAIドキュメント処理タスクに効率をもたらします」
- 「Amazon SageMaker JumpStartを使用したスケーラブルなテキスト埋め込みと文の類似性検索」