コーネル大学の人工知能(AI)研究者たちは、ビデオマッティングの問題に対処するための新しいニューラルネットワークフレームワークを提案しています
Cornell University AI researchers propose a new neural network framework to address video matting problems.


画像と動画の編集は、コンピュータユーザーにとって最も人気のあるアプリケーションの2つです。機械学習(ML)とディープラーニング(DL)の登場により、画像と動画の編集は、いくつかのニューラルネットワークアーキテクチャを通じて徐々に研究されてきました。最近まで、画像と動画の編集のためのほとんどのDLモデルは、教師あり学習であり、具体的には、望ましい変換の詳細を学習するために入力と出力データのペアを含むトレーニングデータが必要でした。最近では、単一の画像のみを入力として望ましい編集済み出力へのマッピングを学習するエンドツーエンドの学習フレームワークが提案されています。
ビデオマッティングは、ビデオ編集に属する特定のタスクです。マッティングという用語は、19世紀にさかのぼり、撮影中にカメラの前にマットペイントのガラス板を設置して、撮影場所に存在しない環境の錯覚を作り出すために使用されました。現在では、複数のデジタル画像の合成は類似の手順に従います。合成式は、各画像の前景と背景の強度を、それぞれの成分の線形結合として表します。
このプロセスは非常に強力ですが、いくつかの制約があります。画像を前景と背景のレイヤーに明確に分解する必要があり、それらは独立して処理可能であると仮定されます。ビデオマッティングなどの一連の時間的および空間的に依存するフレームのような状況では、レイヤーの分解は複雑なタスクとなります。
- メイヨークリニックのAI研究者たちは、拡散モデルを活用したマルチタスク脳腫瘍インペインティングアルゴリズムを構築するための機械学習ベースの手法を紹介しました
- ミシガン州立大学の研究者たちは、規模の大きな一細胞遺伝子発現の分析をサポートするためのPythonライブラリ「DANCE」を開発しました
- 中国からの新しいAI研究、「Meta-Transformer マルチモーダル学習のための統一されたAIフレームワーク」を提案する
本論文では、このプロセスの解明と分解の精度向上を目指しています。著者らは、下流の編集タスクのためにビデオをより独立した構成要素に分解するマッティング問題の変種であるファクターマッティングを提案しています。この問題に対処するために、彼らはシーン内の予想される変形に基づいた条件付き事前知識を古典的なマッティング事前知識に組み合わせた使いやすいフレームワークであるFactorMatteを提案しています。たとえば、最大事後確率の推定を指す古典的なベイズの式には、前景と背景の独立性に関する制限を取り除くための拡張が行われています。さらに、ほとんどのアプローチでは、背景レイヤーが時間の経過に伴って静的なままであるという仮定がされていますが、これはほとんどのビデオシーケンスにとって制限があります。
これらの制約を克服するために、FactorMatteは2つのモジュールに依存しています。デコンポジションネットワークは、各成分ごとに入力ビデオを1つ以上のレイヤーに分解し、各成分に対する条件付き事前知識を表すパッチベースの識別器のセットです。アーキテクチャのパイプラインは以下のように示されます。
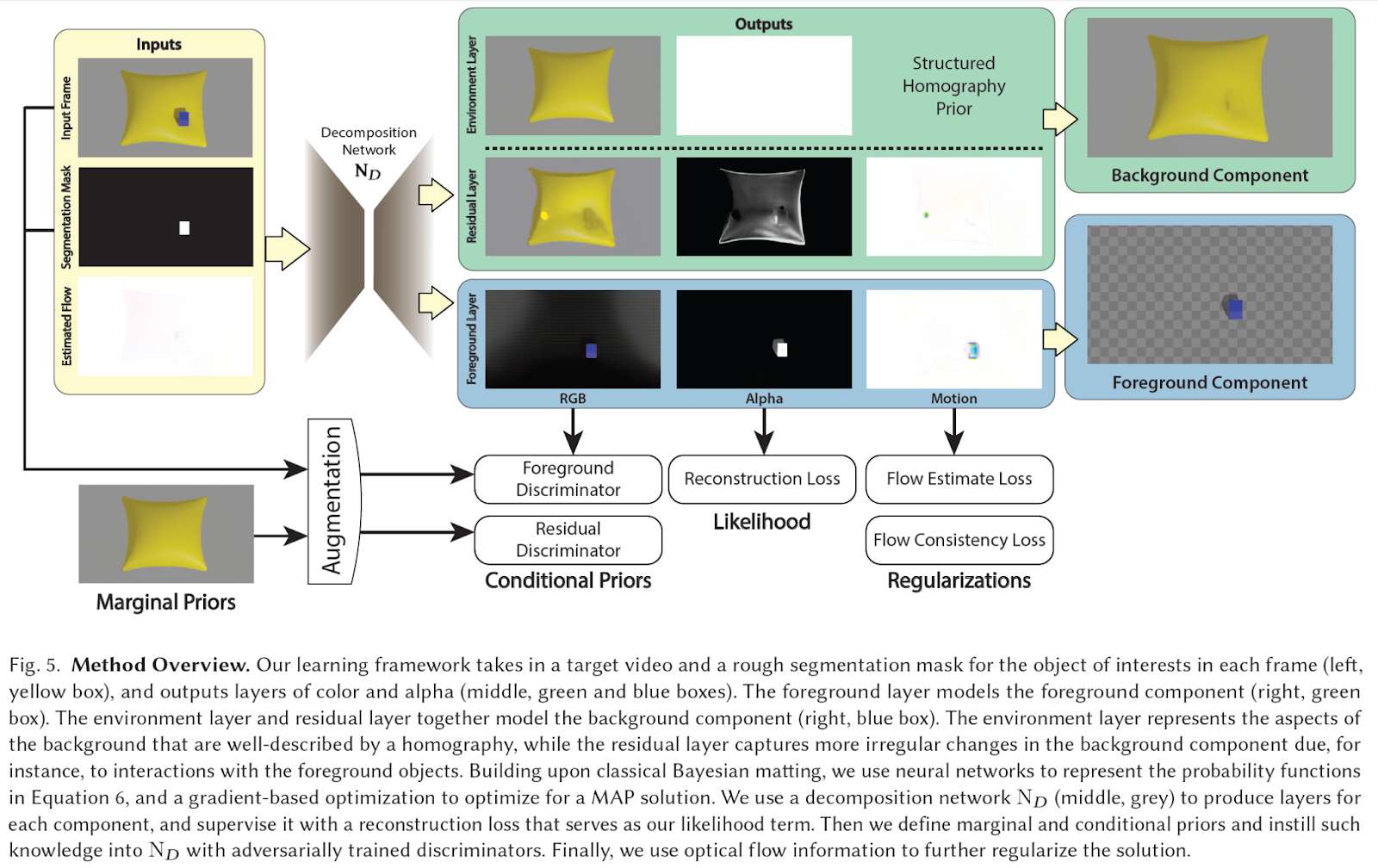
デコンポジションネットワークへの入力は、フレームごとに対象オブジェクトの粗いセグメンテーションマスクを含むビデオです(左、黄色のボックス)。この情報を元に、ネットワークは再構成損失に基づいてカラーとアルファのレイヤー(中央、緑と青のボックス)を生成します。前景レイヤーは前景成分をモデル化します(右、緑のボックス)、一方、環境レイヤーと残差レイヤーは背景成分をモデル化します(右、青のボックス)。環境レイヤーは背景の静的な要素を表し、残差レイヤーは前景オブジェクトとの相互作用による背景成分のより不規則な変化を捉えます(図の枕の変形)。これらのレイヤーごとに、各成分の事前確率を学習するための1つの識別器がトレーニングされています。
選択されたサンプルに対するマッティングの結果は、以下の図に示されています。

FactorMatteは完璧ではありませんが、生成された結果はベースライン手法(OmniMatte)よりも明らかに正確です。すべてのサンプルにおいて、背景と前景のレイヤーはきれいに分離されており、比較解決策では断定することができません。さらに、削除実験を行い、提案された解決策の有効性を証明しました。
これがビデオマッティング問題に対処するための新しいフレームワークであるFactorMatteの概要でした。興味がある場合は、以下のリンクで詳細情報を見つけることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- KAIST(韓国科学技術院)からの新しいAI研究、FLASK(スキルセットに基づく言語モデルの細かい評価フレームワーク)を紹介
- Salesforce AIは、既存の拡散モデルを与えられた場合に、テキストから画像への拡散生成を行う新しい編集アルゴリズム「EDICT」を開発しました
- 「UCLAの研究者が提案するPhyCV:物理に触発されたコンピュータビジョンのPythonライブラリ」
- 「CMUの研究者がBUTD-DETRを導入:言語発話に直接依存し、発話で言及されるすべてのオブジェクトを検出する人工知能(AI)モデル」
- 「バイトダンスAI研究は、連続および離散パラメータのミックスを使用して、高品質のスタイル化された3Dアバターを作成するための革新的な自己教師あり学習フレームワークを提案しています」
- 画像分類において、拡散モデルがGANより優れていることがAI研究で明らかになりましたこの研究では、BigBiGANなどの同等の生成的識別的手法に比べて、拡散モデルが分類タスクにおいて優れた性能を発揮することが示されました
- 「新しいAI研究は、3D構造に基づいたタンパク質表現学習のためのシンプルで効果的なエンコーダーを提案する」






