制御ネット(ControlNet)は、🧨ディフューザー内での使用です
ControlNetはディフューザー内での使用を目的としています
![]()
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます!
私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。
| 写実的なLofiガール |
|---|
 |
また、それをあなたのインテリアデザイナーとして使用することもできます。
| Before | After |
|---|---|
 |
 |
あなたはスケッチのスクリブルを芸術的な絵に変えることができます。
| Before | After |
|---|---|
 |
 |
さらに、有名なロゴを生き生きとさせることもできます。
| Before | After |
|---|---|
 |
ControlNetを使用すると、可能性は無限大です🌠
このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう!
ControlNet: TL;DR
ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。
ControlNetのトレーニングは次の手順で行われます:
- Diffusionモデル(Stable Diffusionの潜在的なUNetなど)の事前学習パラメータを複製し(「トレーニング可能なコピー」と呼ばれる)、同時に事前学習パラメータを別個に保持します(「ロックされたコピー」と呼ばれる)。これにより、ロックされたパラメータコピーは大規模なデータセットから学習した膨大な知識を保持できる一方、トレーニング可能なコピーはタスク固有の側面を学習するために使用されます。
- トレーニング可能なコピーとロックされたコピーのパラメータは、「ゼロ畳み込み」層(詳細はこちらを参照)を介して接続され、ControlNetフレームワークの一部として最適化されます。これは、新しい条件がトレーニングされる間、凍結モデルにすでに学習済みの意味を保持するためのトレーニングトリックです。
絵で見ると、ControlNetのトレーニングは次のようになります:
 この図はここから取られています。
この図はここから取られています。
ControlNetのトレーニングセットの例は以下のようになります(追加の条件はエッジマップを介して行われます):
| プロンプト | 元画像 | 条件 |
|---|---|---|
| “鳥” |  |
 |
同様に、セマンティックセグメンテーションマップでControlNetを条件づける場合、トレーニングサンプルは次のようになります:
| プロンプト | 元画像 | 条件 |
|---|---|---|
| “大きな家” |  |
 |
新しいタイプの条件付けには、ControlNetの重みの新しいコピーのトレーニングが必要です。この論文では、Diffusersでサポートされている8つの異なる条件付けモデルが提案されています!
推論では、事前学習済みの拡散モデルの重みとトレーニング済みのControlNetの重みの両方が必要です。たとえば、ControlNetチェックポイントを使用したStable Diffusion v1-5では、元のStable Diffusionモデルを使用する場合に比べて約7億のパラメータが追加されるため、推論においてControlNetは多少メモリが必要です。
事前学習済みの拡散モデルはトレーニング中にロックされているため、異なる条件付けを使用する場合にはControlNetのパラメータのみを切り替えればよいです。これにより、1つのアプリケーションに複数のControlNetの重みを簡単に展開することができます。
StableDiffusionControlNetPipeline
始める前に、DiffusersへのControlNetの統合をリードしたコミュニティの貢献者である森拓真さんに感謝の意を表したいと思います ❤️。
ControlNetを試すために、Diffusersは他のDiffusersパイプラインと同様にStableDiffusionControlNetPipelineを公開しています。 StableDiffusionControlNetPipelineの中心になるのはcontrolnet引数で、特定のトレーニングされたControlNetModelインスタンスを提供できるようになっています。事前学習済みの拡散モデルの重みは同じままです。
このブログポストでは、StableDiffusionControlNetPipelineを使用したさまざまなユースケースを探っていきます。最初に説明するControlNetモデルは、Cannyモデルです。これはインターネット上で見られる素晴らしい画像のいくつかを生成した最も人気のあるモデルの1つです。
以下のセクションに示されているコードスニペットをこのColabノートブックで実行してみてください。
始める前に、必要なライブラリがすべてインストールされていることを確認しましょう:
pip install diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.git選択したControlNetに応じて異なる条件を処理するには、いくつかの追加の依存関係もインストールする必要があります:
- OpenCV
- controlnet-aux – ControlNet用のシンプルな前処理モデルのコレクション
pip install opencv-contrib-python
pip install controlnet_auxこの例では有名な絵画「真珠の耳飾りの少女」を使用します。さて、画像をダウンロードして見てみましょう:
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image
次に、画像をCannyプリプロセッサを通します:
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image上記のコードを見ると、基本的にはエッジ検出です:

次に、runwaylml/stable-diffusion-v1-5とCannyエッジのControlNetモデルを読み込みます。モデルは、高速かつメモリ効率の良い推論を可能にするために、半精度(torch.dtype)で読み込まれます。
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)Stable DiffusionのデフォルトのPNDMSchedulerではなく、現在最も高速な拡散モデルスケジューラであるUniPCMultistepSchedulerを使用します。改良されたスケジューラを選択することで、推論時間を大幅に削減することができます。この場合、推論ステップの数を50から20に削減し、ほぼ同じ画像生成品質を維持することができます。スケジューラに関する詳細な情報は、こちらをご覧ください。
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)パイプラインを直接GPUにロードする代わりに、enable_model_cpu_offload関数を使用してスマートなCPUオフロードを有効にします。
推論時には、Stable Diffusionなどの拡散モデルは1つではなく複数のモデルコンポーネントを順次実行する必要があります。ControlNetを使用したStable Diffusionの場合、まずCLIPテキストエンコーダを使用し、次に拡散モデルunetとcontrol net、次にVAEデコーダ、最後に安全チェッカーを実行します。ほとんどのコンポーネントは拡散プロセス中に1度だけ実行されるため、常にGPUメモリを占有する必要はありません。スマートモデルオフロードを有効にすることで、各コンポーネントが必要な時にのみGPUにロードされるようにし、推論速度を著しく低下させずにメモリ消費を大幅に節約できます。
注意: enable_model_cpu_offloadを実行する際には、.to("cuda")でパイプラインを手動でGPUに移動しないでください。CPUオフロードが有効になると、パイプラインが自動的にGPUメモリの管理を行います。
pipe.enable_model_cpu_offload()最後に、素晴らしいFlashAttention/xformersアテンションレイヤーの高速化を最大限に活用したいので、これを有効にしましょう!このコマンドが機能しない場合は、xformersが正しくインストールされていない可能性があります。その場合は、次のコード行をスキップしてください。
pipe.enable_xformers_memory_efficient_attention()これでControlNetパイプラインを実行する準備が整いました!
通常のStable Diffusionイメージ対イメージパイプラインと同様に、画像生成プロセスをガイドするためのプロンプトを提供します。しかし、ControlNetを使用すると、作成したCannyエッジ画像を使用して生成された画像の正確な構成を制御することができるため、生成された画像に対してより多くの制御が可能になります。
17世紀の絵画の中で現代の有名人が同じポーズをとっている画像を見るのは楽しいことです。そして、ControlNetを使用すると、これらの有名人の名前をプロンプトに含めるだけで簡単に実現できます!
まず、画像をグリッドとして表示するための簡単なヘルパー関数を作成しましょう。
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid次に、入力プロンプトを定義し、再現性のためにシードを設定します。
prompt = ", 最高の品質、非常に詳細"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]]
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(len(prompt))]最後に、パイプラインを実行して画像を表示できます!
output = pipe(
prompt,
canny_image,
negative_prompt=["モノクロ、低解像度、悪い解剖学、最低の品質、低品質"] * 4,
num_inference_steps=20,
generator=generator,
)
image_grid(output.images, 2, 2)
ControlNetとファインチューニングを簡単に組み合わせることもできます!例えば、DreamBoothのモデルをファインチューニングして、異なるシーンに自分自身をレンダリングすることができます。
この投稿では、愛されているMr Potato Headを例として使用し、ControlNetをDreamBoothと組み合わせる方法を示します。
同じControlNetを使用することができます。ただし、Stable Diffusion 1.5の代わりに、Mr Potato Headモデルをパイプラインに読み込むことにします – Mr Potato HeadはDreamboothを使用してMr Potato HeadのコンセプトにファインチューニングされたStable Diffusionモデルです 🥔
上記のコマンドを実行しましょう。ただし、ControlNetは変更せずに!
model_id = "sd-dreambooth-library/mr-potato-head"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()さあ、Mr PotatoがJohannes Vermeerのポーズをとるようにしましょう!
generator = torch.manual_seed(2)
prompt = "sks mr potato headの写真、最高の品質、非常に詳細"
output = pipe(
prompt,
canny_image,
negative_prompt="モノクロ、低解像度、悪い解剖学、最低の品質、低品質",
num_inference_steps=20,
generator=generator,
)
output.images[0]Mr Potato Headが最適な候補ではないことがわかりますが、彼は最善を尽くし、本質の一部をうまく捉えています 🍟

ControlNetのもう一つの独自の応用例は、1つの画像からポーズを取り出し、同じポーズを持つ異なる画像を生成することができることです。次の例では、スーパーヒーローにOpen Pose ControlNetを使用してヨガを教えます!
まず、ヨガをしている人々のいくつかの画像を取得する必要があります:
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [
load_image("https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url)
for url in urls
]
image_grid(imgs, 2, 2)
次に、OpenPoseのプリプロセッサを使用してヨガのポーズを抽出します。これはcontrolnet_auxを介して便利に利用できます。
from controlnet_aux import OpenposeDetector
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)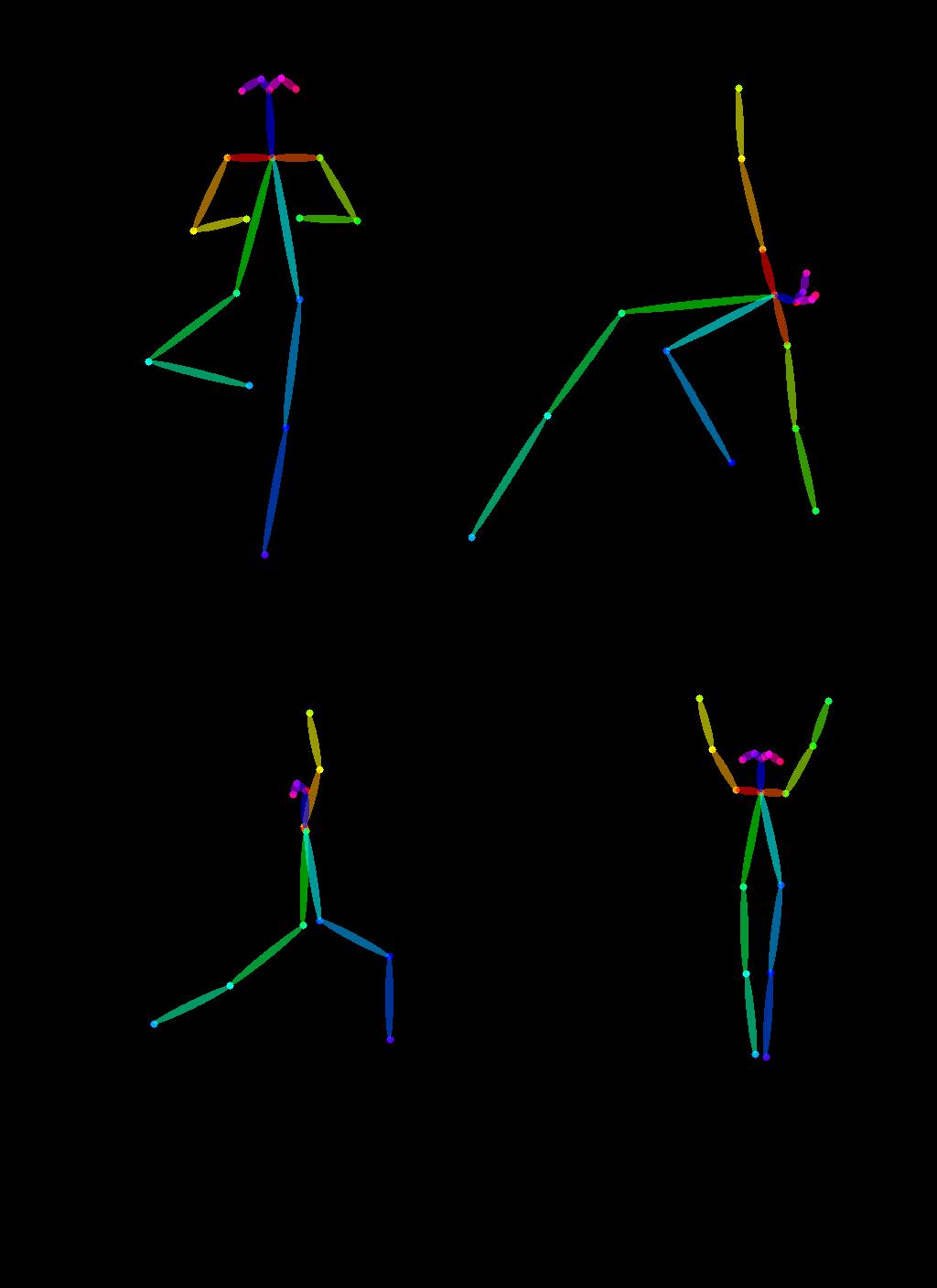
これらのヨガのポーズを使用して新しい画像を生成するために、Open Pose ControlNetを作成しましょう。上記に示されたヨガのポーズでスーパーヒーローの画像を生成します。さあ、始めましょう 🚀
controlnet = ControlNetModel.from_pretrained(
"fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16
)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()今はヨガの時間です!
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe(
[prompt] * 4,
poses,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)
複数の条件を組み合わせる
複数のControlNetの条件を組み合わせて画像生成を行うことができます。パイプラインのコンストラクタにControlNetのリストを渡し、__call__に対応する条件のリストを渡します。
条件を組み合わせる際には、条件が重ならないようにマスクをすると便利です。この例では、ポーズの条件があるキャニーマップの中央部分をマスクしています。
また、controlnet_conditioning_scaleを変化させることで、一方の条件を他方よりも強調することができます。
キャニー条件
元の画像

条件の準備
from diffusers.utils import load_image
from PIL import Image
import cv2
import numpy as np
from diffusers.utils import load_image
canny_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
canny_image = np.array(canny_image)
low_threshold = 100
high_threshold = 200
canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
# ポーズがオーバーレイされる画像の中央列をゼロにする
zero_start = canny_image.shape[1] // 4
zero_end = zero_start + canny_image.shape[1] // 2
canny_image[:, zero_start:zero_end] = 0
canny_image = canny_image[:, :, None]
canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
canny_image = Image.fromarray(canny_image)
Openpose条件
元の画像

条件の準備
from controlnet_aux import OpenposeDetector
from diffusers.utils import load_image
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
openpose_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(openpose_image)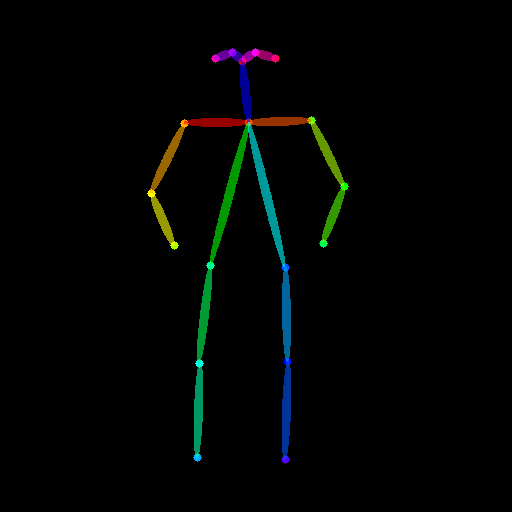
複数の条件でControlNetを実行する
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = [
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
]
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
prompt = "a giant standing in a fantasy landscape, best quality"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
generator = torch.Generator(device="cpu").manual_seed(1)
images = [openpose_image, canny_image]
image = pipe(
prompt,
images,
num_inference_steps=20,
generator=generator,
negative_prompt=negative_prompt,
controlnet_conditioning_scale=[1.0, 0.8],
).images[0]
image.save("./multi_controlnet_output.png")
これまでの例では、StableDiffusionControlNetPipelineのさまざまな側面を探求し、ControlNetをDiffusersを介して簡単かつ直感的に操作できることを示しました。ただし、ControlNetでサポートされているすべての条件付けについてはカバーしていません。それらについて詳しく知りたい場合は、各モデルのドキュメントページをご覧ください:
- lllyasviel/sd-controlnet-depth
- lllyasviel/sd-controlnet-hed
- lllyasviel/sd-controlnet-normal
- lllyasviel/sd-controlnet-scribble
- lllyasviel/sd-controlnet-seg
- lllyasviel/sd-controlnet-openpose
- lllyasviel/sd-controlnet-mlsd
- lllyasviel/sd-controlnet-canny
これらの異なる要素を組み合わせて、@diffuserslib と共有してみてください。上記の例のいくつかを試すためには、Colabノートブックをチェックしてください!
また、高速スケジューラ、スマートモデルオフロード、xformersを使用して、生成プロセスを高速化し、メモリに優しいものにするいくつかの技術も紹介しました。これらの技術を組み合わせると、V100 GPU上での生成プロセスはわずか約3秒かかり、単一の画像に対して約4 GBのVRAMを消費します⚡️ Google Colabなどの無料サービスでは、デフォルトのGPU(T4)を使用して約5秒かかりますが、元の実装では同じ結果を作成するために17秒かかります!diffusersツールボックスのすべての要素を組み合わせると、本当に強力な力が発揮されます 💪
結論
StableDiffusionControlNetPipelineとたくさん遊んできましたが、これまでの経験は楽しかったです!このパイプラインの上にコミュニティが構築するものを楽しみにしています。制御された生成を可能にするDiffusersでサポートされている他のパイプラインや技術をチェックするには、公式ドキュメントをご覧ください。
ControlNetを直接試してみたい場合は、以下のいずれかのスペースをクリックしてControlNetを操作してみてください:
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






