「ConDistFLとの出会い:CTデータセットにおける臓器と疾患のセグメンテーションのための革新的なフェデレーテッドラーニング手法」
ConDistFL Innovative Federated Learning Method for Organ and Disease Segmentation in CT Dataset


コンピュータ支援診断や治療計画などの臨床応用のために、コンピュータ断層撮影(CT)画像は腹部臓器と腫瘍を正確にセグメント化する必要があります。現実の医療状況では、多くの臓器と病気を同時に処理できる一般化モデルが好まれます。主要な研究は、悪性腫瘍のない個々の臓器や異なる臓器クラスのセグメンテーションに焦点を当ててきましたが、他の興味深い領域も存在します。一方、従来の教師付き学習技術は、トレーニングデータのボリュームと品質に依存しています。残念ながら、高品質の医療画像データの高額な費用からトレーニングデータの不足が生じています。正確な医療画像に対して正しい注釈を作成できるのは、資格を持つ専門家のみです。
さらに、専門家であっても、異なる解剖学の臓器や関連するがんを注釈付けするのは困難です。一部の専門家は、単一の活動に特化した専門知識しか持っていない場合もあります。異なる臓器と悪性腫瘍に対して適切な注釈情報が不足しているため、一般化されたセグメンテーションモデルの開発が大幅に妨げられています。この問題を解決するために、一部の対象臓器と悪性腫瘍のみが各画像にタグ付けされた部分的に注釈付きのデータセットを使用して、一般化されたセグメンテーションモデルを開発するための研究が行われています。しかし、機密性の高い医療統計情報を組織間で共有することは、プライバシーや法的な問題を引き起こす可能性があります。これらの問題に対処するために、連邦学習(FL)が提案されました。
FLは、データを一箇所に集約することなく、複数の機関間で共通(または「グローバル」)モデルの協調トレーニングを可能にします。医療画像セグメンテーションの効果を高めるための潜在的な方法として、FLがあります。FLでは、各クライアントは単にモデルの更新をサーバーに送信し、そのデータとリソースを使用してローカルモデルをトレーニングします。サーバーはこれらの変更をグローバルモデルに統合するために「FedAvg」を使用します。最近の研究では、図1に示すように、部分的に注釈付けされた腹部データセットを使用して、統一された多臓器セグメンテーションモデルをFLを使用して作成しています。しかし、これらの手法では病変領域を頻繁に無視しています。一部の研究では、異なる臓器とその腫瘍を同時にセグメント化するための努力が行われています。
- 「PUGに会ってください:メタAIによるアンリアルエンジンを使用したフォトリアルで意味的に制御可能なデータセットを用いた堅牢なモデル評価に関する新しいAI研究」
- USCとMicrosoftの研究者は、UniversalNERを提案します:ターゲット指向の蒸留で訓練され、13,000以上のエンティティタイプを認識し、43のデータセット上でChatGPTのNER精度を9%F1上回る新しいAIモデルです
- インフォグラフィックスでデータ可視化をどのように使用するか?
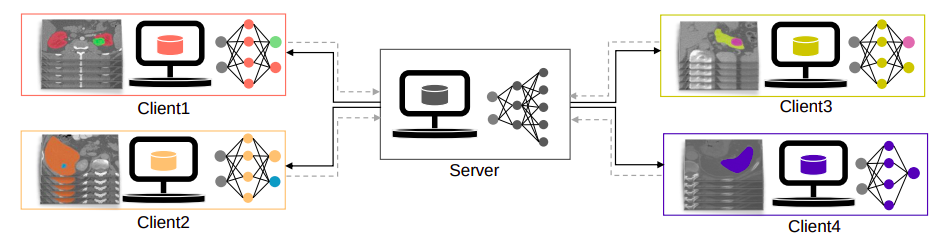
データの多様性によって引き起こされるデータの異質性への対処の難しさにより、FLのモデル集約は重要な課題に直面しています。異なるソースからのモデルを非IIDデータとともに使用すると、パフォーマンスが低下する可能性があります。クライアントがさまざまな目的のために注釈付けられたデータを使用すると、ラベル空間にドメインシフトがさらに導入され、問題が悪化します。さらに、データの少ないジョブの場合、クライアントの異なるデータセットのサイズによって、グローバルモデルのパフォーマンスに影響を与える可能性があります。この論文の研究者は、国立台湾大学、名古屋大学、NVIDIA Corporationの研究者が、部分的に注釈付きの腹部CT画像からマルチクラスの臓器と腫瘍のセグメンテーションにおけるFLにおけるデータの異質性に対処する戦略を提案しています。
この研究の主な貢献は次のとおりです:
1. 提案された条件付き蒸留連邦学習(ConDistFL)フレームワークにより、追加の完全に注釈付きのデータセットを必要とせずに、腹部臓器と悪性腫瘍の複合マルチタスクセグメンテーションが可能になります。
2. 提案されたフレームワークは、長いローカルトレーニングステップと少数の集約による安定性とパフォーマンスを実証し、データトラフィックとトレーニング時間を削減します。
3. 彼らは、AMOS22と呼ばれる未公開の完全に注釈付きのパブリックデータセットを使用して、自分たちのモデルをさらにテストしています。定性的および定量的な評価の結果は、彼らの戦略の堅牢性を示しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「データの可視化を改善するための4つの必須リソース」
- 高パフォーマンスなリアルタイムデータモデルの構築ガイド
- 「データサイエンスは難しいのか?現実を知ろう」
- Google AIは、ドキュメント理解タスクの進捗状況をより正確に追跡するためのデータセットである「Visually Rich Document Understanding (VRDU)」を導入しました
- 「制限されたデータで言語モデルをトレーニングするのはリスキーですか?SILOに会ってください:推論中のリスクとパフォーマンスのトレードオフを管理する新しい言語モデル」
- 「ディープラーニングの解説:ニューラルネットワークへの学生の入門」
- 「Apache Sparkにおける出力ファイルサイズの最適化」
