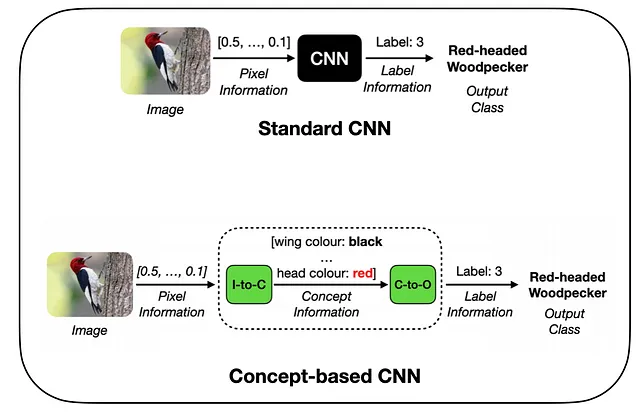
「Now You See Me (CME) 概念ベースのモデル抽出」
Concept-based model extraction for Now You See Me (CME)
コンセプトベースモデルへのラベル効率的なアプローチ
CIKMカンファレンスで発表されたAIMLAIワークショップ論文から:「Now You See Me(CME):コンセプトベースモデルの抽出」(GitHub)
要点
問題 — 深層ニューラルネットワークモデルはブラックボックスであり、直接解釈することができません。その結果、このようなモデルに対して信頼を築くことは困難です。既存の手法であるコンセプトボトルネックモデルは、このようなモデルをより解釈可能にするものの、基になるコンセプトの注釈に高いコストがかかります。
主なイノベーション — 弱教師ありの方法によるコンセプトベースモデルの生成方法は、結果として非常に少ない注釈のみを必要とします。
解決策 — 弊社のコンセプトベースモデル抽出(CME)フレームワークは、事前学習されたバニラ型畳み込みニューラルネットワーク(CNN)からコンセプトベースモデルを準教師ありの方法で抽出することができ、エンドタスクのパフォーマンスを保持します。
- 効果的な小規模言語モデル:マイクロソフトの13億パラメータphi-1.5
- 「BlindChat」に会いましょう:フルブラウザおよびプライベートな対話型AIを開発するためのオープンソースの人工知能プロジェクト
- 「コンテキストに基づくドキュメント検索の強化:GPT-2とLlamaIndexの活用」
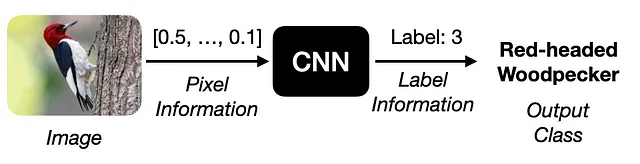
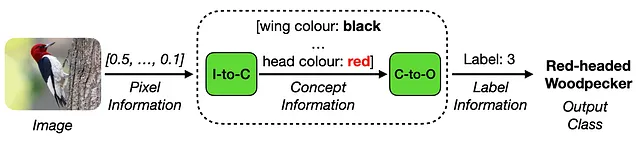
コンセプトボトルネックモデル(CBM)
近年、説明可能な人工知能(XAI)[1]の領域では、コンセプトボトルネックモデル(CBM)アプローチ[2]に対する関心が高まっています。これらの手法では、入力画像が2つの異なるフェーズで処理される革新的なモデルアーキテクチャが導入されています:コンセプト符号化とコンセプト処理。
コンセプト符号化では、高次元の入力データからコンセプト情報が抽出されます。その後、コンセプト処理フェーズでは、この抽出されたコンセプト情報を使用して、目的の出力タスクラベルが生成されます。CBMの顕著な特徴は、下流のタスク予測のための中間的で解釈可能なコンセプト表現に依存していることです。
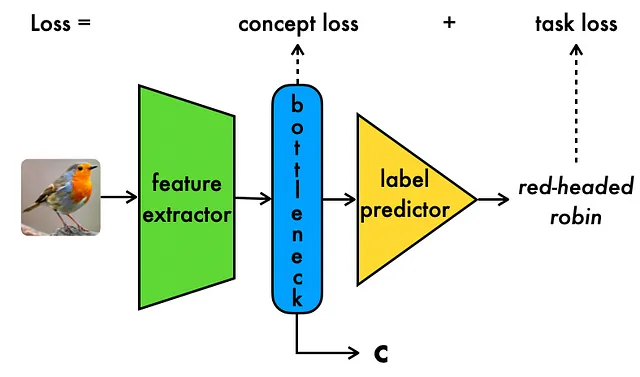
上記のように、CBMモデルは、正確なタスクラベルの予測を保証するためのタスク損失と、正確な中間コンセプトの予測を保証するためのコンセプト損失の組み合わせで訓練されます。重要なのは、CBMはモデルの透明性を向上させることであり、基になるコンセプト表現がモデルの動作を説明し、より良く理解する手段を提供します。
コンセプトボトルネックモデルは、既存のドメイン知識をコンセプトを介してモデルにエンコードすることができる、設計上解釈可能なCNNの新しいタイプを提供します。
全体的に、CBMはより透明性があり信頼性の高いモデルに近づくための重要なイノベーションとなります。
課題:CBMのコンセプト注釈コストが高い
残念ながら、CBMは訓練時に多くのコンセプト注釈が必要です。
現在、CBMの手法では、すべての訓練サンプルにエンドタスクとコンセプトの注釈が明示的に必要です。したがって、N個のサンプルとC個のコンセプトを持つデータセットでは、注釈コストがN注釈(サンプルごとに1つのタスクラベル)からN *(C + 1)注釈(サンプルごとに1つのタスクラベルと各コンセプトの注釈)に上昇します。実際には、コンセプトの数や訓練サンプルの多いデータセットでは、すぐに扱いにくくなる可能性があります。
例えば、10,000の画像データセットに50の概念がある場合、注釈のコストは50 * 10,000 = 500,000のラベル、つまり追加の50万の注釈で増加します。
残念ながら、概念ボトルネックモデルはトレーニングにかなりの量の概念の注釈を必要とします。
CMEを用いた半教師付きコンセプトベースモデルの活用
CMEは、[3]で強調された似たような観察に基づいています。そこでは、バニラCNNモデルはしばしば隠れた空間の概念に関する多くの情報を保持しており、これらの情報は追加の注釈コストなしでコンセプト情報の採掘に使用できることが観察されました。重要なことは、この作業が潜在的な概念が不明であり、モデルの隠れた空間から非教師付きの方法で抽出するシナリオを考慮していることです。
CMEでは、上記の観察を利用し、潜在的な概念の知識があるが、それぞれの概念に対してごく少量のサンプルの注釈しか持っていない場合を考えます。[3]と同様に、CMEは事前に学習済みのバニラCNNと少量の概念の注釈に依存して、半教師付きの方法でさらなる概念の注釈を抽出します。以下に示すように:
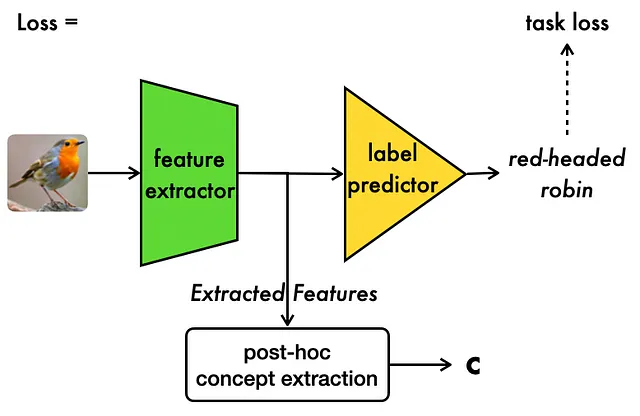
上記のように、CMEは事後的に事前に学習済みモデルの隠れた空間を使用して概念表現を抽出します。詳細は以下に示します。
概念エンコーダのトレーニング:CBMの場合と同様に、生データ上で概念エンコーダをゼロからトレーニングする代わりに、バニラCNNの隠れた空間を使用して半教師付きの方法で概念エンコーダモデルのトレーニングをセットアップします:
- 最初に、概念抽出に使用するバニラCNNのレイヤーLのセットを事前に指定します。利用可能な計算能力に応じて、すべてのレイヤーまたは最後の数レイヤーまでの範囲にすることができます。
- 次に、各概念について、Lの各レイヤーの隠れた空間を使用してその概念の値を予測するための別々のモデルをトレーニングします
- 次に、各概念について最も高いモデル精度を持つモデルと対応するレイヤーを選択し、「ベスト」モデルとレイヤーとして使用します。
- その結果、概念iの概念予測を行う場合、まずその概念のベストレイヤーの隠れた空間表現を取得し、それを対応する予測モデルに通します。
全体として、概念エンコーダ関数は以下のようにまとめられます(合計でkの概念があると仮定):
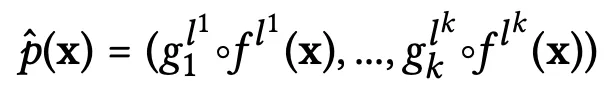
- ここで、LHSのp-hatは概念エンコーダ関数を表します
- gᵢの項は、異なるレイヤーの隠れた空間上でトレーニングされた隠れた空間から概念へのモデルを表し、iは概念インデックスを表し、1からkまでの範囲内です。実際には、これらのモデルは比較的単純なものである場合があります。例えば、線形回帰器や勾配ブースティング分類器などです。
- f(x)の項は、元のバニラCNNのサブモデルであり、特定のレイヤーで入力の隠れた表現を抽出します
- 上記の両方の場合、lʲの上付き文字はこれらの2つのモデルが操作する「ベスト」レイヤーを指定します
概念プロセッサのトレーニング:CMEでの概念プロセッサモデルのトレーニングは、タスクラベルを出力とし、概念エンコーダの予測を入力としてモデルをトレーニングすることでセットアップされます。重要なことは、これらのモデルがよりコンパクトな入力表現で動作しているため、決定木(DT)やロジスティック回帰(LR)モデルなどの解釈可能なモデルを介して直接表現できることです。
CMEの実験と結果
私たちの合成データ(dSpritesとshapes3d)および厳しい現実世界のデータセット(CUB)における実験は、CMEモデルが次のような結果を示すことを示しました:
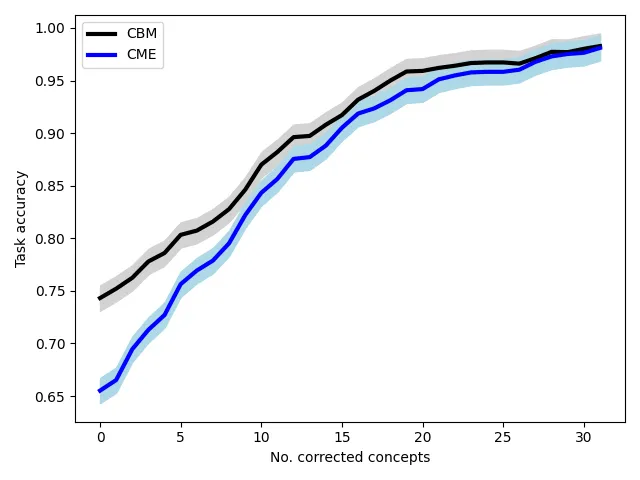
- 多くの場合において、CBMと同等の高い概念的予測精度を達成します。これは、エンドタスクに関係のない概念に対しても当てはまります:

- 概念による人間の介入を可能にします — つまり、選択された概念の小さなセットを修正することでモデルのパフォーマンスを迅速に改善することができます:
- 概念の観点からモデルの意思決定を説明する — 実践者が概念プロセッサモデルを直接プロットできるようにします:
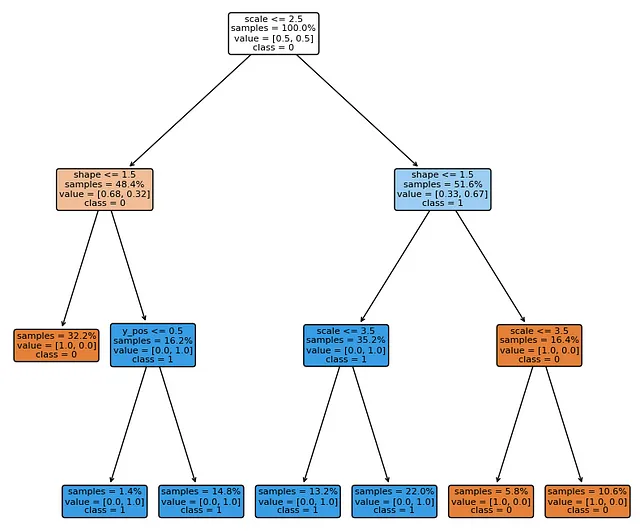
- モデルが概念を処理する方法を理解するのに役立ちます — モデル層を横断した基礎概念の非表示空間を分析することによって:

弱教師ありドメインで概念ベースモデルをCMEで定義することにより、ラベル効率が大幅に向上した概念ベースモデルを開発することができます。
要点
事前学習されたバニラディープニューラルネットワークを活用することで、通常のCBM手法と比較して、概念の注釈と概念ベースモデルを大幅に低い注釈コストで得ることができます。
さらに、これはエンドタスクと高い相関関係を持つ概念に限定されるものではなく、一部の場合にはエンドタスクと独立した概念にも適用されます。
参考文献
[1] Chris Molnar. Interpretable Machine Learning. https://christophm.github.io/interpretable-ml-book/
[2] Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International Conference on Machine Learning, pages 5338–5348. PMLR (2020).
[3] Amirata Ghorbani, James Wexler, James Zou, and Been Kim. Towards Automatic Concept-based Explanations. In Advances in neural information processing systems, 32.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AIはどれくらい環境に優しいのか?人間の作業と人工知能の二酸化炭素排出量を比較する」
- 大規模言語モデル:RoBERTa — ロバストに最適化されたBERTアプローチ
- 「TikTokがAI生成コンテンツのためのAIラベリングツールを導入」
- デシAIは、DeciDiffusion 1.0を公開しました:820億パラメータのテキストから画像への潜在的拡散モデルで、安定した拡散と比べて3倍の速度です
- 「Hugging FaceはLLMのための新しいGitHubです」
- 「Google DeepMindが、7100万件の「ミスセンス」変異の効果を分類する新しいAIツールを発表」
- バッテリー最適化の解除:機械学習とナノスケールX線顕微鏡がリチウムバッテリーを革命化する可能性






