AIの未来を形作る ビジョン・ランゲージ・プリトレーニング・モデルの包括的な調査と、ユニモーダルおよびマルチモーダルタスクにおける役割
Comprehensive survey of Vision Language Pretraining models shaping the future of AI and their role in unimodal and multimodal tasks.


機械学習研究の最新リリースで、ビジョン言語事前学習(VLP)とその多様なタスクへの応用について、研究チームが深く掘り下げています。この論文は、単一モーダルトレーニングのアイデアを探究し、それがマルチモーダル適応とどのように異なるかを説明しています。そして、VLPの5つの重要な領域である特徴抽出、モデルアーキテクチャ、事前トレーニング目標、事前トレーニングデータセット、およびダウンストリームタスクを示しています。研究者たちは、既存のVLPモデルとその異なる側面での適応をレビューしています。
人工知能の分野は常に、モデルを人間と同じように知覚、思考、そしてパターンや微妙なニュアンスを理解する方法でトレーニングしようとしてきました。ビジュアル、オーディオ、テキストなど、可能な限り多くのデータ入力フィールドを組み込もうとする試みがいくつか行われてきました。ただし、これらのアプローチのほとんどは、単一モーダル意味で「理解」の問題を解決しようとしたものです。
単一モーダルアプローチは、1つの側面のみを評価するアプローチであり、例えばビデオの場合、音声またはトランスクリプトに焦点を絞っており、マルチモーダルアプローチでは、可能な限り多くの利用可能な特徴をターゲットにしてモデルに組み込もうとします。たとえば、ビデオを分析する際に、音声、トランスクリプト、スピーカーの表情をとらえて、文脈を本当に「理解」することができます。
- FastAPI、AWS Lambda、およびAWS CDKを使用して、大規模言語モデルのサーバーレスML推論エンドポイントを展開します
- ディープラーニングが深く掘り下げる:AIがペルー砂漠で新しい大規模画像を公開
- 線形回帰の理論的な深堀り
マルチモーダルアプローチは、リソースが豊富であり、訓練に必要な大量のラベル付きデータを取得することが困難であるため、課題があります。Transformer構造に基づく事前トレーニングモデルは、自己教師あり学習と追加タスクを活用して、大規模な非ラベルデータからユニバーサルな表現を学習することで、この問題に対処しています。
NLPのBERTから始まり、単一モーダルの方法でモデルを事前トレーニングすることで、限られたラベル付きデータでダウンストリームタスクを微調整することができることが示されています。研究者たちは、同じ設計哲学をマルチモーダル分野に拡張することで、ビジョン言語事前学習(VLP)の有効性を探究しました。VLPは、大規模なデータセットで事前トレーニングモデルを使用して、モダリティ間の意味的な対応関係を学習します。
研究者たちは、VLPアプローチの進歩について、5つの主要な領域を検討しています。まず、VLPモデルが画像、ビデオ、テキストを前処理して表現する方法、使用されるさまざまなモデルを強調して説明しています。次に、単一ストリームの観点とその使用可能性、デュアルストリームフュージョンとエンコーダのみ対エンコーダデコーダ設計の観点を探究しています。
論文では、VLPモデルの事前トレーニングについてさらに探求し、完了、マッチング、特定のタイプに分類しています。これらの目標は、ユニバーサルなビジョン言語表現を定義するのに役立ちます。研究者たちは、2つの主要な事前トレーニングデータセットのカテゴリである画像言語モデルとビデオ言語モデルについて概説しました。論文では、マルチモーダルアプローチが文脈を理解し、より適切にマッピングされたコンテンツを生成するためにどのように役立つかを強調しています。最後に、記事は、事前トレーニングモデルの有効性を評価する上での重要性を強調しながら、VLPのダウンストリームタスクの目標と詳細を提示しています。
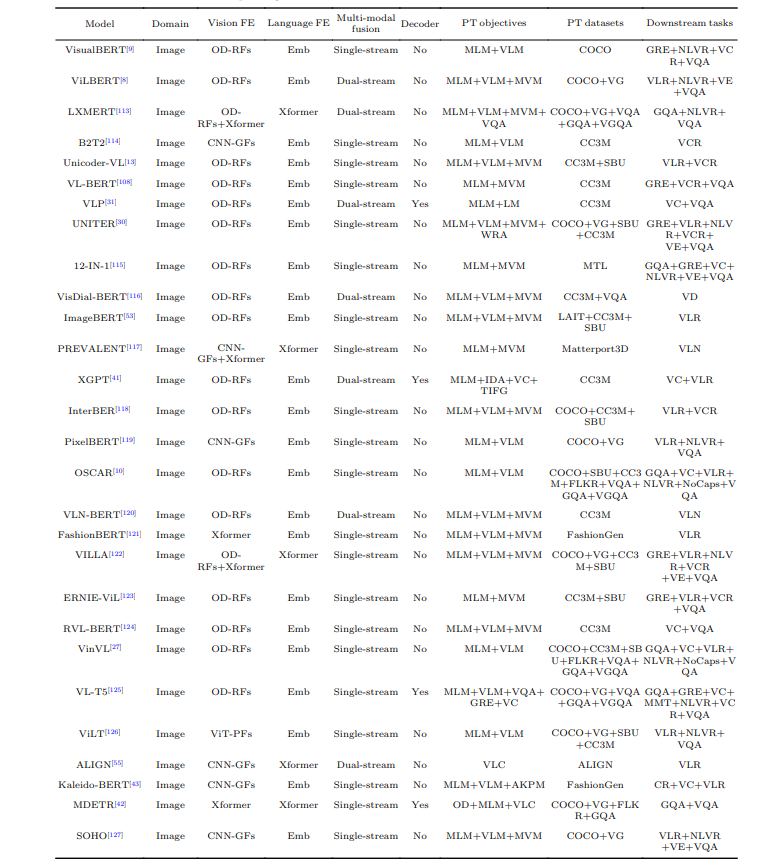
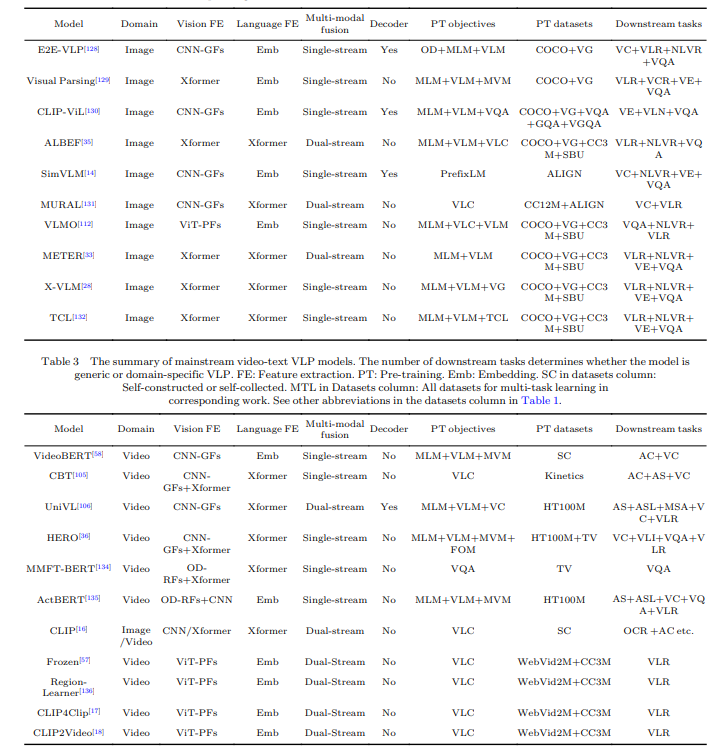
この論文では、SOTA(State-of-the-Art)のVLPモデルについて詳細な概要が提供されています。これらのモデルをリストアップし、その主要な特徴やパフォーマンスを強調しています。言及されているモデルは、最先端の技術開発の堅固な基盤であり、将来の開発のベンチマークとして役立ちます。
研究論文に基づくと、VLPアーキテクチャの将来は有望で信頼性があります。彼らは、音響情報の統合、知識と認知学習、プロンプトチューニング、モデル圧縮と加速、およびドメイン外の事前学習など、様々な改善の領域を提案しています。これらの改善領域は、新しい研究者たちがVLPの分野で前進し、画期的なアプローチを打ち出すためにインスピレーションを与えることを目的としています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles