「MLOpsに関する包括的なガイド」
Comprehensive Guide to MLOps

はじめに
近年、MLモデルは大幅に成長し、ビジネスはますますこれらのモデルに頼って業務を自動化し最適化しています。しかし、MLモデルの管理は困難であり、特にモデルがより複雑化し、トレーニングと展開により多くのリソースを必要とするようになると、さらに困難になります。そのため、MLワークフローを標準化し効率化する手段として、MLOpsが登場しました。MLOpsは、MLワークフローにおける継続的な統合と継続的な展開(CI/CD)の必要性を強調し、モデルがデータやMLアルゴリズムの変更を反映するためにリアルタイムで更新されることを保証します。このインフラストラクチャは、精度、再現性、信頼性が重要な医療、金融、自動運転車などの分野で価値があります。MLOpsを実施することで、組織は自社のMLモデルが継続的に更新され、正確性が保たれることを確認し、イノベーションを推進し、コストを削減し、効率を向上させることができます。
- 「ODSC West 2023のトピックトラックを紹介します – Gen AIとLLMsを特集します」
- 「もしエンジニアがAIのコーディングツールを使い始めたら、プロダクトチームには何が起こるのでしょうか?」
- 「アメリカがAIセキュリティツール開発のコンテストを開催」
MLOpsとは何ですか?
MLOpsは、MLとDevOpsのプラクティスを組み合わせて、MLモデルの開発、展開、保守を効率化する方法論です。MLOpsは、次の点でDevOpsと多くの共通点があります。
- CI/CD: MLOpsは、MLワークフローにおけるコード、データ、モデルの継続的な更新サイクルの必要性を強調しています。このアプローチでは、一貫性と信頼性を確保するためにできるだけ多くの自動化が必要です。
- 自動化: DevOpsと同様に、MLOpsはMLライフサイクル全体での自動化の重要性を強調しています。データ処理、モデルトレーニング、展開など、MLワークフローの重要なステップを自動化することで、より効率的かつ信頼性の高いワークフローを実現します。
- 協力と透明性: MLOpsは、MLモデルの開発と展開を行うチーム間での共有知識と専門知識のコラボレーションと透明性の文化を奨励しています。これにより、ハンドオフの期待値がより標準化されるため、プロセスが効率化されます。
- インフラストラクチャとしてのコード(IaC): DevOpsとMLOpsは、インフラストラクチャをコードとして扱い、バージョン管理システムを介して管理する「インフラストラクチャとしてのコード」アプローチを採用しています。このアプローチにより、チームはインフラストラクチャの変更をより効率的かつ再現可能に管理することができます。
- テストとモニタリング: MLOpsとDevOpsは、一貫性と信頼性を確保するためにテストとモニタリングの重要性を強調しています。MLOpsでは、MLモデルの正確性とパフォーマンスを時間とともにテストおよびモニタリングすることが含まれます。
- 柔軟性とアジリティ: DevOpsとMLOpsは、ビジネスのニーズと要件の変化に対して柔軟性とアジリティを重視しています。これは、ビジネスの要求に追いつくためにMLモデルを迅速に展開し、反復することができることを意味します。
要点は、MLは予測を生成するために使用されるブラックボックスであるため、その動作には多くの変動性があるということです。DevOpsとMLOpsは多くの類似点を共有していますが、MLOpsはデータ駆動型および計算集約型のMLワークフローによって引き起こされる固有の課題に対処するために、より専門的なツールとプラクティスが必要です。MLワークフローでは、従来のソフトウェア開発を超える幅広い技術スキルが必要とされることがあり、トレーニングと展開の計算要件を管理するためのアクセラレータ、GPU、クラスタなどの専門的なインフラストラクチャコンポーネントが関与する場合もあります。それにもかかわらず、DevOpsのベストプラクティスを取り入れ、MLワークフロー全体に適用することで、プロジェクトの時間を大幅に短縮し、MLが本番環境で効果的に機能するための構造を提供することができます。
現代のビジネスにおけるMLOpsの重要性と利点
MLは、ビジネスがデータを分析し、意思決定を行い、業務を最適化する方法を革新しました。それにより、組織はパターン、トレンド、洞察を明らかにする強力なデータ駆動型モデルを作成し、より情報に基づいた意思決定と効果的な自動化を実現することができます。ただし、MLモデルの効果的な展開と管理は困難な場合があり、それがMLOpsの重要性を引き出す理由です。MLOpsは、次のようなさまざまな利点を提供するため、現代のビジネスにとってますます重要になっています。
- 開発時間の短縮: MLOpsにより、組織はMLモデルの開発ライフサイクルを加速し、市場投入までの時間を短縮することができます。さらに、MLOpsは、データ収集、モデルトレーニング、展開などの多くのタスクを自動化することで、リソースを解放し、全体的なプロセスをスピードアップさせることができます。
- モデルのパフォーマンスの向上: MLOpsにより、ビジネスは自社のMLモデルのパフォーマンスを継続的に監視し改善することができます。MLOpsは、MLモデルの正確性、モデルのドリフト、データ品質に関連する問題を検出するための自動化されたテストメカニズムを容易にします。これらの問題に早期に対処することで、組織はMLモデルの全体的なパフォーマンスと正確性を向上させることができ、それがより良いビジネス成果につながります。
- より信頼性のある展開: MLOpsにより、企業は異なる本番環境でより信頼性の高い展開を行うことができます。展開プロセスを自動化することで、MLOpsは展開エラーと環境間の不一致のリスクを低減します。
- コスト削減と効率の向上: MLOpsの実施により、組織はコストを削減し、全体的な効率を向上させることができます。データ処理、モデルトレーニング、展開に関わる多くのタスクを自動化することで、組織は手動介入の必要性を減らし、より効率的かつコスト効果の高いワークフローを実現することができます。
要約すると、MLOpsは、革新を促進し、競争に先んじ、ビジネスの成果を向上させるために、MLの変革的な力を活用しようとする現代のビジネスにとって不可欠です。より高速な開発時間、より良いモデルのパフォーマンス、より信頼性の高い展開、およびより効率的な運用を可能にすることにより、MLOpsはビジネスインテリジェンスと戦略におけるMLのフルポテンシャルを引き出す上で重要な役割を果たします。MLOpsツールを利用することで、チームメンバーはより重要な事柄に集中し、ビジネスは冗長なワークフローを維持するための大規模な専任チームの維持費を節約することができます。
MLOpsライフサイクル
独自のMLOpsインフラストラクチャを作成するか、オンラインで利用可能なさまざまなMLOpsプラットフォームから選択する場合、以下に述べる4つの機能を含むインフラストラクチャを確保することが成功のために重要です。これらの重要な側面に対応するMLOpsツールを選択することで、データサイエンティストから展開エンジニアまでの連続したサイクルを作成し、品質を犠牲にすることなくモデルを迅速に展開できます。
継続的インテグレーション(CI)
継続的インテグレーション(CI)では、コードとデータへの変更を常にテストおよび検証し、一連の定義された基準を満たしていることを確認します。MLOpsでは、CIは新しいデータやMLモデルおよびサポートコードの更新を統合します。CIにより、チームは開発プロセスの早い段階で問題を発見し、効果的に協力し、高品質なMLモデルを維持することができます。MLOpsにおけるCIの実践例には、以下があります:
- データの整合性と品質を保証するための自動データ検証チェック。
- モデルのアーキテクチャとハイパーパラメータの変更を追跡するためのモデルバージョン管理。
- 本番リポジトリにコードがマージされる前にモデルコードの自動ユニットテスト。
継続的デプロイメント(CD)
継続的デプロイメント(CD)は、MLモデルやアプリケーションなどのソフトウェアのアップデートを自動的に本番環境にリリースすることです。MLOpsでは、CDはMLモデルの展開がスムーズで信頼性があり、一貫性があることに重点を置いています。CDにより、展開中のエラーのリスクが低減され、ビジネスの要件の変化に対応してMLモデルを維持および更新することが容易になります。MLOpsにおけるCDの実践例には、以下があります:
- JenkinsやCircleCIなどの継続的デプロイメントツールを使用した自動MLパイプライン。モデルの更新を統合およびテストし、それを本番環境に展開します。
- Dockerなどの技術を使用してMLモデルをコンテナ化し、一貫した展開環境を実現し、展開の問題を減らします。
- ローリングデプロイメントまたはブルーグリーンデプロイメントを実施することで、ダウンタイムを最小化し、問題のあるアップデートを簡単にロールバックすることができます。
継続的トレーニング(CT)
継続的トレーニング(CT)では、新しいデータが利用可能になったり、既存のデータが時間とともに変化したりするにつれて、MLモデルを更新します。MLOpsのこの重要な側面により、MLモデルは最新のデータを考慮し、モデルのドリフトを防止しながら正確で効果的なままであることが保証されます。新しいデータで定期的にモデルをトレーニングすることで、最適なパフォーマンスを維持し、より良いビジネスの成果を達成することができます。MLOpsにおけるCTの実践例には、以下があります:
- 正確性のしきい値などのポリシーを設定し、最新の正確性を維持するためにモデルの再トレーニングをトリガーする。
- トレーニングのための価値のある新しいデータを優先的に収集するためのアクティブラーニング戦略を使用する。
- 異なるデータのサブセットでトレーニングされた複数のモデルを組み合わせるアンサンブルメソッドを使用し、モデルの改善とデータパターンの変化への適応を継続的に行う。
継続的モニタリング(CM)
継続的モニタリング(CM)では、本番環境でのMLモデルのパフォーマンスを常に分析し、潜在的な問題を特定し、モデルが定義された基準を満たし、全体的なモデルの有効性を維持します。MLOpsの実践者は、モデルのドリフトやパフォーマンスの劣化などの問題を検出し、予測の正確性と信頼性を損なう可能性があります。定期的にモデルのパフォーマンスをモニタリングすることで、組織は問題に予防的に対処し、MLモデルが有効で望ましい結果を生成し続けることを保証できます。MLOpsにおけるCMの実践例には、以下があります:
- 本番環境でのモデルの主要なパフォーマンス指標(精度、再現率など)のトラッキング。
- モデルの健全性をリアルタイムで可視化するためのモデルパフォーマンスモニタリングダッシュボードの実装。
- 概念の変化を特定および処理するための異常検出技術の適用。これにより、モデルが時間とともに変化するデータパターンに適応し、その正確性を維持できます。
MLOpsはMLライフサイクルにどのような利益をもたらしますか?
MLモデルの管理と展開は、MLワークフローの複雑さ、データの変動性、反復的な実験、および展開されたモデルの継続的な監視および更新の必要性により、時間がかかり、困難を伴うことがあります。MLライフサイクルがMLOpsと適切に統合されていない場合、データ品質のばらつきによる一貫性のない結果、手動プロセスがボトルネックとなり展開が遅れること、およびビジネスの状況変化に対応するためにモデルを迅速に維持および更新することの困難さなどの問題が組織に生じます。MLOpsは、MLライフサイクルの各段階を容易にする効率性、自動化、およびベストプラクティスをもたらします。
データサイエンスチームが専用のMLOpsプラクティスを持たない状況でセールス予測のためのMLモデルを開発しているシナリオを考えてみましょう。このシナリオでは、チームは以下のような課題に直面するかもしれません:
- 標準化されたプラクティスや自動化されたデータ検証ツールの欠如により、データの前処理およびクレンジングのタスクに時間がかかること。
- モデルのアーキテクチャ、ハイパーパラメータ、およびデータセットのバージョン管理の不十分さにより、実験の再現性とトレーサビリティに困難が生じること。
- 手動および非効率な展開プロセスにより、モデルのリリースが遅れ、本番環境でのエラーのリスクが増加すること。
- 手動展開はオンラインの複数のサーバーでの自動スケーリング展開に多くの障害を引き起こし、冗長性とアップタイムに影響を与えること。
- データパターンの変化に迅速に展開されたモデルを調整することのできないことは、パフォーマンスの低下とモデルのドリフトにつながる可能性があります。
MLライフサイクルには5つのステージがあり、以下のMLOpsツールを使用することで直接改善されます。
データの収集と前処理
MLライフサイクルの最初のステージは、データの収集と前処理です。組織は、この段階でベストプラクティスを実装することで、データの品質、一貫性、管理可能性を確保することができます。データのバージョン管理、自動化されたデータ検証チェック、チーム内での協力により、MLモデルの精度と効果を向上させることができます。例えば以下のようなものがあります:
- モデリングに使用されるデータセットの変更を追跡するためのデータのバージョン管理。
- データの品質と整合性を維持するための自動化されたデータ検証チェック。
- チーム内でデータソースを効果的に共有および管理するための協力ツール。
モデルの開発
MLOpsは、モデルの開発段階で標準化されたプラクティスに従うことをチームに支援します。アルゴリズム、特徴、およびハイパーパラメータの選択時に、非効率性と重複した作業を減らし、モデル全体のパフォーマンスを向上させます。バージョン管理、自動実験のトラッキング、および協力ツールの導入により、MLライフサイクルのこの段階を効果的に進めることができます。例えば以下のようなものがあります:
- モデルのアーキテクチャとハイパーパラメータのバージョン管理。
- 繰り返し実験を減らし、簡単な比較と議論を促進するための自動実験のトラッキングのための中央ハブの確立。
- 視覚化ツールとメトリックのトラッキングにより、開発中のモデルのパフォーマンスを監視し、協力を促進します。
モデルのトレーニングと検証
トレーニングおよび検証の段階では、MLOpsは組織が信頼性のあるプロセスを使用してMLモデルをトレーニングおよび評価することを保証します。自動化とトレーニングのベストプラクティスを活用することで、モデルの精度を効果的に最適化することができます。MLOpsのプラクティスには、交差検証、トレーニングパイプラインの管理、および連続インテグレーションが含まれます。これにより、モデルの更新を自動的にテストおよび検証することができます。例えば以下のようなものがあります:
- より良いモデル評価のための交差検証技術。
- より効率的でスムーズなプロセスのためのトレーニングパイプラインとワークフローの管理。
- モデルの更新を自動的にテストおよび検証するための連続インテグレーションワークフロー。
モデルの展開
第四のステージは、モデルの本番環境への展開です。このステージでのMLOpsのプラクティスは、モデルの展開時のエラーや一貫性の問題のリスクを減らし、組織がモデルをより信頼性の高い方法で展開できるように支援します。Dockerを使用したコンテナ化や自動化された展開パイプラインなどの技術を使用することで、モデルを本番環境にシームレスに統合し、ロールバックおよびモニタリングの機能を実現することができます。例えば以下のようなものがあります:
- 一貫した展開環境のためのDockerを使用したコンテナ化。
- 手動介入なしでモデルのリリースを処理するための自動化された展開パイプライン。
- 展開の問題を迅速に特定および修正するためのロールバックおよびモニタリング機能。
モデルのモニタリングとメンテナンス
第五のステージは、本番環境でのMLモデルの継続的なモニタリングとメンテナンスです。このステージでMLOpsの原則を活用することで、組織は一貫してモデルを評価および調整することができます。定期的なモニタリングにより、モデルのドリフトやパフォーマンスの低下などの問題を検出し、予測の正確性と信頼性を損なうことがありません。主要なパフォーマンス指標、モデルのパフォーマンスダッシュボード、およびアラート機構により、組織は問題を予防的に対処し、MLモデルの効果を維持することができます。例えば以下のようなものがあります:
- モデルの本番運用時にパフォーマンスを追跡するための主要な指標。
- モデルの健全性をリアルタイムで可視化するためのモデルパフォーマンスダッシュボード。
- モデルのパフォーマンスに突発的または漸進的な変化があった場合に、チームに通知するアラート機能。これにより、迅速な介入と問題の解決が可能となります。
MLOpsツールとテクノロジー
適切なツールとテクノロジーを採用することは、MLOpsの実践とエンドツーエンドのMLワークフローの管理において重要です。多くのMLOpsソリューションは、データ管理や実験追跡からモデルの展開とモニタリングまで、さまざまな機能を提供しています。ホールMLライフサイクルワークフローを広告するMLOpsツールからは、次のような機能をいくつか実装することが期待されます:
- エンドツーエンドのMLライフサイクル管理:これらのツールは、データの前処理やモデルのトレーニングから展開とモニタリングまで、MLライフサイクルのさまざまな段階をサポートするように設計されています。
- 実験の追跡とバージョン管理:これらのツールは、実験、モデルのバージョン、およびパイプラインの実行を追跡するメカニズムを提供し、再現性を可能にし、異なるアプローチを比較することができます。一部のツールは、他の抽象化を使用して再現性を表示する場合もありますが、バージョン管理の形式を備えています。
- モデルの展開:ツールによっては、具体的な方法は異なりますが、モデルの展開機能を提供しています。これにより、ユーザーはモデルを本番環境に移行するか、モデルの推論をリクエストするアプリケーションとの間でクイックな展開エンドポイントを提供することができます。
- 人気のあるMLライブラリやフレームワークとの統合:これらのツールは、TensorFlow、PyTorch、Scikit-learnなどの人気のあるMLライブラリと互換性があり、既存のMLツールとスキルを活用することができます。ただし、各フレームワークのサポート量はツール間で異なります。
- 拡張性とカスタマイズ性:これらのツールは、さまざまな拡張性とカスタマイズ性を提供し、ユーザーが特定のニーズに合わせてプラットフォームをカスタマイズし、他のツールやサービスと統合することができます。
- 共同作業とマルチユーザーサポート:各プラットフォームは通常、チームメンバー間の共同作業を容易にし、リソース、コード、データ、および実験結果を共有できるようにしています。これにより、MLライフサイクル全体での効果的なチームワークと共有理解が促進されます。
- 環境と依存関係の処理:これらのツールのほとんどは、一貫性と再現性のある環境の処理に関する機能を備えています。これには、コンテナ(つまり、Docker)や仮想環境(つまり、Conda)を使用した依存関係の管理、または人気のあるデータサイエンスライブラリとツールの事前設定が含まれることがあります。
- モニタリングとアラート:エンドツーエンドのMLOpsツールは、パフォーマンスのモニタリング、異常検出、またはアラート機能を提供する場合もあります。これにより、ユーザーは高性能なモデルを維持し、潜在的な問題を特定し、MLソリューションが本番環境で信頼性と効率性を維持することができます。
これらのツールが提供するコア機能には重複があるものの、それらの独自の実装、実行方法、および焦点領域によって異なる特徴があります。言い換えれば、オファリングを比較する際にMLOpsツールを見た目で判断することは困難かもしれません。これらのツールは異なるワークフロー体験を提供します。
次のセクションでは、完全なエンドツーエンドのMLOps体験を提供するいくつかの注目すべきMLOpsツールを紹介し、彼らが標準的なMLOps機能をどのようにアプローチし、実行するかの違いを強調します。
MLFlow
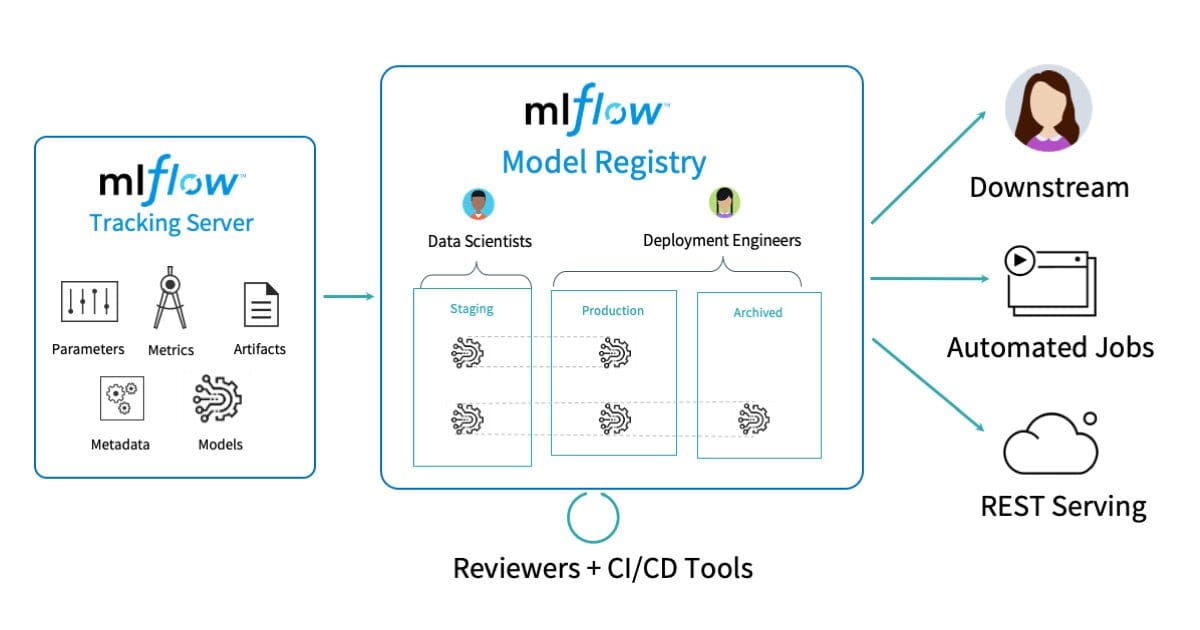
MLflowには、他のMLOpsツールとは異なる特徴と特性があり、特定の要件や好みを持つユーザーに魅力的です:
- モジュラリティ:MLflowの最大の利点の1つは、モジュラーなアーキテクチャです。独立したコンポーネント(トラッキング、プロジェクト、モデル、レジストリ)からなり、それぞれを個別に使用するか組み合わせて使用することができます。これにより、ユーザーはすべてのコンポーネントを強制的に採用する必要なく、プラットフォームを自分のニーズに合わせてカスタマイズすることができます。
- 言語に依存しない:MLflowは、Python、R、Javaなど、複数のプログラミング言語をサポートしています。これにより、さまざまなスキルセットを持つユーザーにアクセス可能となります。これは主に、MLワークロードに異なるプログラミング言語を好むメンバーを持つチームに利益をもたらします。
- 人気のあるライブラリとの統合:MLflowは、TensorFlow、PyTorch、Scikit-learnなどの人気のあるMLライブラリと連携するように設計されています。この互換性により、ユーザーは既存のワークフローにMLflowをシームレスに統合し、現在のツールを変更することなく、管理機能を活用することができます。
- 活発なオープンソースコミュニティ:MLflowには活気のあるオープンソースコミュニティがあり、その開発に貢献し、MLOpsの領域での新しいトレンドや要件に追従しています。この活発なコミュニティサポートにより、MLflowは最新かつ関連性のあるMLライフサイクル管理ソリューションであることが保証されます。
MLflowは、MLライフサイクルのさまざまな側面を管理するための多目的でモジュラーなツールですが、他のMLOpsプラットフォームと比較していくつかの制約があります。MLflowが不足している注目すべき領域の1つは、TFXやKubeflow Pipelinesなどが提供する統合されたパイプラインのオーケストレーションと実行機能の必要性です。MLflowは、トラッキング、プロジェクト、モデルコンポーネントを使用してパイプラインステップを構造化し、管理することができますが、複雑なエンドツーエンドのワークフローを調整し、パイプラインタスクの実行を自動化するために、外部ツールやカスタムスクリプトに頼る必要があるかもしれません。その結果、より効率的なパイプラインのオーケストレーションを提供するためのスムーズなサポートを求める組織は、MLflowの機能が改善される必要があり、代替のプラットフォームや統合を検討するかもしれません。
Kubeflow

Kubeflowは、MLライフサイクルのさまざまな側面に対応するためにカスタマイズされたコンポーネントのスイートを備えた包括的なMLOpsプラットフォームですが、他のMLOpsツールと比較していくつかの制約があります。Kubeflowが不足している領域のいくつかは次のとおりです:
- 学習曲線の急勾配:KubeflowはKubernetesとの強力な結合を持っているため、Kubernetesの概念とツールにより詳しくなる必要があるユーザーにとって、学習曲線が急勾配になる可能性があります。これは、新規ユーザーのオンボーディングに要する時間を増やし、Kubernetesの経験がないチームにとっては採用の障壁になる可能性があります。
- 言語のサポートの制約:Kubeflowは最初にTensorFlowを中心に開発されましたが、PyTorchやMXNetなどの他のMLフレームワークへのサポートを拡充しています。それにもかかわらず、KubeflowはTensorFlowエコシステムに対してより重要な偏りがあります。他の言語やフレームワークを使用している組織は、Kubeflowを採用し統合するために追加の努力を必要とする場合があります。
- インフラストラクチャの複雑さ:KubeflowはKubernetesに依存しているため、既存のKubernetesセットアップがない組織にとっては、追加のインフラストラクチャ管理の複雑さをもたらす可能性があります。Kubernetesの全機能を必要としない小規模なチームやプロジェクトは、Kubeflowのインフラストラクチャ要件が不要なオーバーヘッドになる場合があります。
- 実験の追跡に対する重点の低さ:Kubeflowは、Kubeflow Pipelinesコンポーネントを介して実験の追跡機能を提供していますが、専用の実験の追跡ツールであるMLflowやWeights & Biasesと比較すると、それほど包括的で使いやすいとは言えません。実験の追跡と比較に重点を置くチームは、Kubeflowのこの側面が他の高度な追跡機能を備えたMLOpsプラットフォームと比較して改善される必要があると感じるかもしれません。
- 非Kubernetesシステムとの統合:KubeflowのKubernetesネイティブの設計は、他の非Kubernetesベースのシステムや独自のインフラストラクチャとの統合能力を制限する可能性があります。一方、MLflowのようなより柔軟で非依存なMLOpsツールは、基礎となるインフラストラクチャに関係なく、さまざまなデータソースやツールとのより簡単な統合オプションを提供するかもしれません。
Kubeflowは、Kubernetesを包括したMLOpsプラットフォームであり、MLワークロードをKubernetesネイティブのワークロードに変換しながら、展開、スケーリング、および管理を効率化します。このKubernetesとの緊密な関係により、複雑なMLワークフローの効率的なオーケストレーションなどの利点が提供されます。ただし、Kubernetesの専門知識がないユーザーやさまざまな言語やフレームワークを使用しているユーザー、非Kubernetesベースのインフラストラクチャを使用している組織にとっては、複雑さが増す可能性があります。全体として、KubeflowのKubernetes中心の性質は、展開とオーケストレーションにおいて大きな利点を提供しますが、組織はこれらのトレードオフと互換性の要素を考慮に入れて、MLOpsのニーズに対してKubeflowを評価するべきです。
Saturn Cloud
Saturn Cloudは、MLモデルのスケーリング、インフラストラクチャ、コラボレーション、および迅速なデプロイメントを提供するMLOpsプラットフォームであり、並列処理とGPUアクセラレーションに焦点を当てています。Saturn Cloudの主な利点と堅牢な機能には、次のようなものがあります:
- リソースのアクセラレーションに焦点:Saturn Cloudは、MLワークロードのための簡単に使用できるGPUアクセラレーションと柔軟なリソース管理に重点を置いています。他のツールがGPUベースの処理をサポートする場合でも、Saturn Cloudはデータサイエンティストがこのアクセラレーションを利用するためのインフラストラクチャ管理のオーバーヘッドを取り除くために、このプロセスを簡素化します。
- Daskと分散コンピューティング:Saturn Cloudは、Pythonの並列処理と分散コンピューティングのための人気のあるライブラリであるDaskとの密な統合を持っています。この統合により、ユーザーはマルチノードクラスタでの並列処理を利用して、ワークロードを容易にスケールアウトさせることができます。
- 管理されたインフラストラクチャと事前構築環境:Saturn Cloudは、管理されたインフラストラクチャと事前構築環境を提供するため、ユーザーのインフラストラクチャのセットアップとメンテナンスの負担を軽減します。
- 簡単なリソース管理と共有:Saturn Cloudは、Dockerイメージ、シークレット、共有フォルダなどのリソースの共有を簡素化するために、所有権とアクセス許可を定義することを許可します。これらのリソースは、個々のユーザー、グループ(ユーザーの集合)、または組織全体の所有権によって所有されます。所有権は、共有リソースにアクセスして使用できるユーザーを決定します。さらに、ユーザーは他の人が同じコードをどこでも実行できるように、簡単に完全な環境をクローンすることができます。
- Infrastructure as Code:Saturn Cloudは、コード中心のアプローチでリソースを定義および管理するためのレシピJSON形式を採用しています。これにより、一貫性、モジュラリティ、およびバージョン管理が促進され、プラットフォームのセットアップやインフラストラクチャコンポーネントの管理が効率
Saturn Cloudは、多くのユースケースに便利な機能と機能を提供していますが、他のMLOpsツールと比較していくつかの制約があります。以下に、Saturn Cloudが制約される可能性のあるいくつかの領域を示します:
- 非Python言語との統合:Saturn Cloudは主にPythonエコシステムを対象としており、人気のあるPythonライブラリやツールに対する幅広いサポートを提供しています。ただし、Linux環境で実行できる任意の言語は、Saturn Cloudプラットフォームで実行することができます。
- 即座の実験トラッキング:Saturn Cloudは実験の記録とトラッキングを容易にしますが、スケーリングとインフラストラクチャに重点を置いており、実験のトラッキング機能に比べてはるかに充実しています。ただし、MLOpsワークフローのトラッキング側でよりカスタマイズ性と機能性を求める人々は、Saturn CloudをComet、Weights & Biases、Verta、Neptuneなどのプラットフォームと統合することができることを喜ぶでしょう。
- Kubernetesネイティブのオーケストレーション:Saturn Cloudはスケーラビリティと管理されたインフラストラクチャをDaskを介して提供していますが、Kubeflowなどのツールが提供するKubernetesネイティブのオーケストレーションには欠けています。Kubernetesに大きく投資している組織は、より深いKubernetes統合を備えたプラットフォームを好むかもしれません。
TensorFlow Extended(TFX)

TensorFlow Extended(TFX)は、TensorFlowユーザーを対象に明示的に設計されたエンドツーエンドのプラットフォームであり、TensorFlowベースのMLワークフローを管理する包括的かつ緊密に統合されたソリューションを提供します。TFXは以下の領域で優れています:
- TensorFlowの統合:TFXの最も注目すべき強みは、TensorFlowエコシステムとのシームレスな統合です。TensorFlow向けに特別に設計されたコンポーネントの完全なセットを提供し、既にTensorFlowに投資しているユーザーが他のツールやフレームワークに切り替えることなく、MLモデルの構築、テスト、展開、モニタリングを容易にします。
- 本番対応:TFXは本番環境を念頭に置いて構築されており、堅牢性、スケーラビリティ、ミッションクリティカルなMLワークロードのサポート能力を重視しています。データの検証と前処理からモデルの展開とモニタリングまで、TFXはワークフローの再現性と一貫性を確保し、スケールで信頼性のあるパフォーマンスを提供します。
- エンドツーエンドのワークフロー:TFXは、MLライフサイクルのさまざまな段階を処理するための幅広いコンポーネントを提供します。データの取り込み、変換、モデルトレーニング、検証、サービングをサポートすることで、ユーザーは再現性とワークフローの一貫性を確保するエンドツーエンドのパイプラインを構築することができます。
- 拡張性:TFXのコンポーネントはカスタマイズ可能であり、必要に応じて独自のコンポーネントを作成して統合することができます。この拡張性により、組織はTFXを固有の要件に合わせてカスタマイズし、好みのツールを組み込んだり、MLワークフローで遭遇するかもしれない固有の課題に対するカスタムソリューションを実装したりすることができます。
ただし、TFXのTensorFlowへの主な焦点は、他のMLフレームワークに頼る組織やより言語に依存しないソリューションを希望する組織にとって制約となる可能性があります。TFXはTensorFlowベースのワークロードに対する強力で包括的なプラットフォームを提供しますが、PyTorchやScikit-learnなどのフレームワークを使用するユーザーは、自身の要件により適した他のMLOpsツールを検討する必要があります。TFXの強力なTensorFlow統合、本番対応性、拡張可能なコンポーネントは、TensorFlowエコシステムに大きく投資している組織にとって魅力的なMLOpsプラットフォームとなります。組織は、現在のツールやフレームワークの互換性を評価し、TFXの機能が自分たちの特定のユースケースとMLワークフローの管理ニーズに適合するかどうかを判断することができます。
MetaFlow
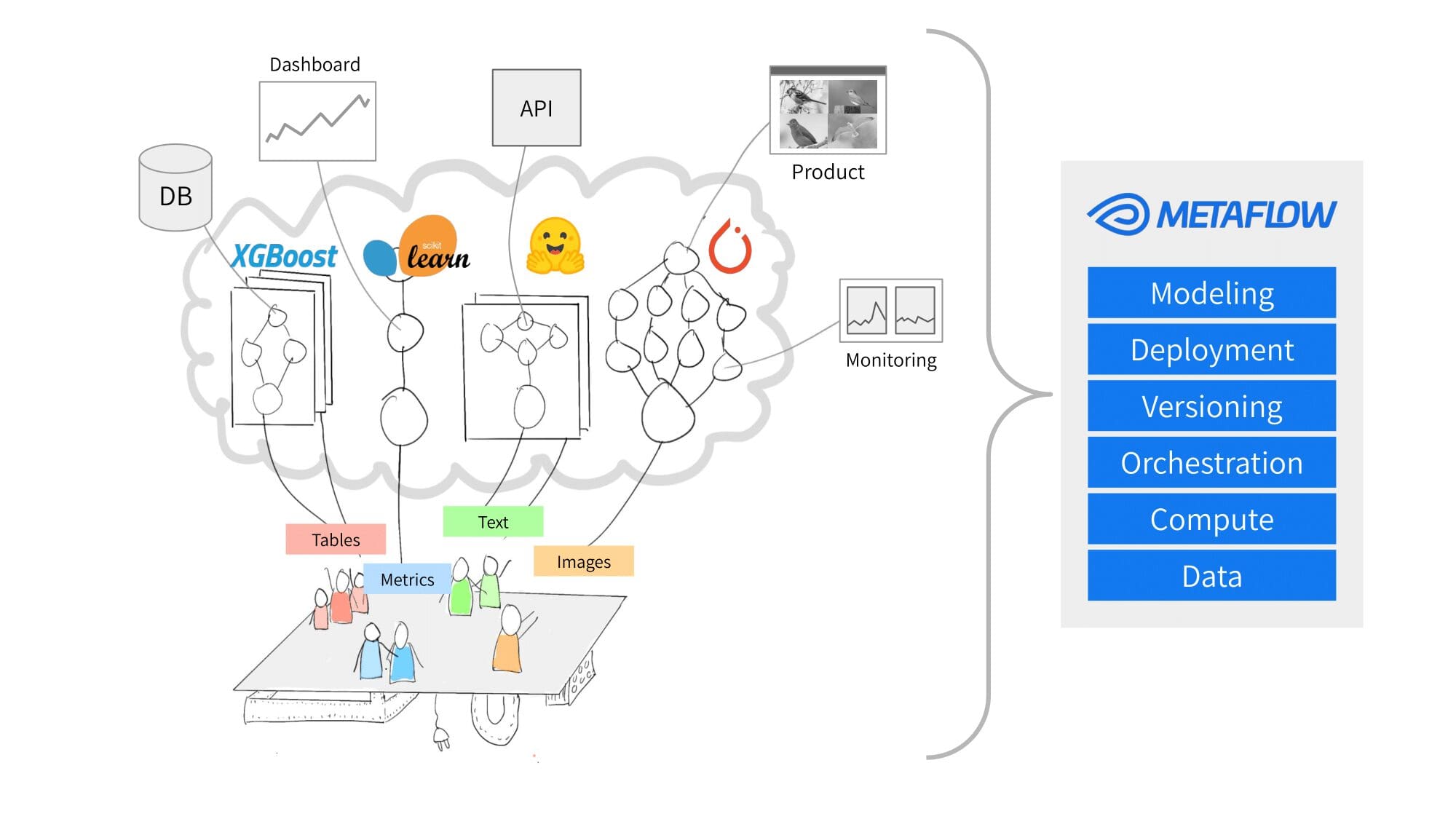
Metaflowは、Netflixが開発したMLOpsプラットフォームであり、複雑な実世界のデータサイエンスプロジェクトを効率化し簡素化することを目的としています。Metaflowは、以下の点で優れています:
- ワークフロー管理:Metaflowの主な強みは、複雑な実世界のMLワークフローを効果的に管理する能力にあります。ユーザーは、組み込みのバージョン管理、依存関係管理、およびPythonベースのドメイン固有言語を使用して、複雑な処理やモデルトレーニングのステップを設計、組織、実行することができます。
- 観測可能性:Metaflowは、パイプラインの各ステップの後で入力と出力を観測する機能を提供し、パイプラインのさまざまな段階でデータを追跡することが容易です。
- スケーラビリティ:Metaflowは、ワークフローをローカル環境からクラウドまでスケーリングし、AWS Batch、S3、Step FunctionsなどのAWSサービスとの緊密な統合を備えています。これにより、ユーザーは基礎となるリソースを気にすることなく、スケールできるワークロードを実行して展開することができます。
- 組み込みのデータ管理:Metaflowは、ワークフローで使用されるデータセットを自動的に追跡することにより、効率的なデータ管理とバージョン管理のツールを提供します。これにより、異なるパイプラインの実行間でデータの一貫性が保たれ、ユーザーは履歴データやアーティファクトにアクセスして再現性と信頼性のある実験を行うことができます。
- 障害耐性と弾力性:Metaflowは、実世界のMLプロジェクトで発生する予期しない障害、リソース制約、および要件の変更といった課題に対処するように設計されています。自動エラーハンドリング、再試行メカニズム、失敗または停止したステップの再開などの機能を提供し、さまざまな状況で信頼性と効率性のあるワークフローの実行が可能です。
- AWS統合:Netflixが開発したMetaflowは、Amazon Web Services(AWS)インフラストラクチャと密接に統合しています。これにより、すでに
Metaflowにはいくつかの強みがありますが、他のMLOpsツールと比較すると不足している部分もあります:
- 限定的なディープラーニングのサポート:Metaflowは、主に典型的なデータサイエンスのワークフローや従来の機械学習手法に焦点を当てて開発されたため、ディープラーニングにはあまり適していません。これは、TensorFlowやPyTorchなどのディープラーニングフレームワークを主に使用するチームやプロジェクトには適さないかもしれません。
- 実験のトラッキング:Metaflowはいくつかの実験トラッキングの機能を提供しています。ただし、ワークフロー管理とインフラのシンプルさに重点を置くため、MLflowやWeights & Biasesなどの専用の実験トラッキングプラットフォームと比較して、トラッキングの機能が総合的には制限されているかもしれません。
- Kubernetesネイティブのオーケストレーション:Metaflowはさまざまなバックエンドソリューション(AWS Batchやコンテナオーケストレーションシステムなど)に展開できる多目的なプラットフォームです。ただし、Kubeflowなどのツールに見られるKubernetesネイティブのパイプラインオーケストレーションの機能は備えていないため、MLパイプライン全体をKubernetesリソースとして実行することはできません。
- 言語のサポート:Metaflowは主にPythonをサポートしています。これはほとんどのデータサイエンスの実践にとって有利ですが、RやJavaなどの他のプログラミング言語を使用しているチームがMLプロジェクトで利用する場合には制限となるかもしれません。
ZenML
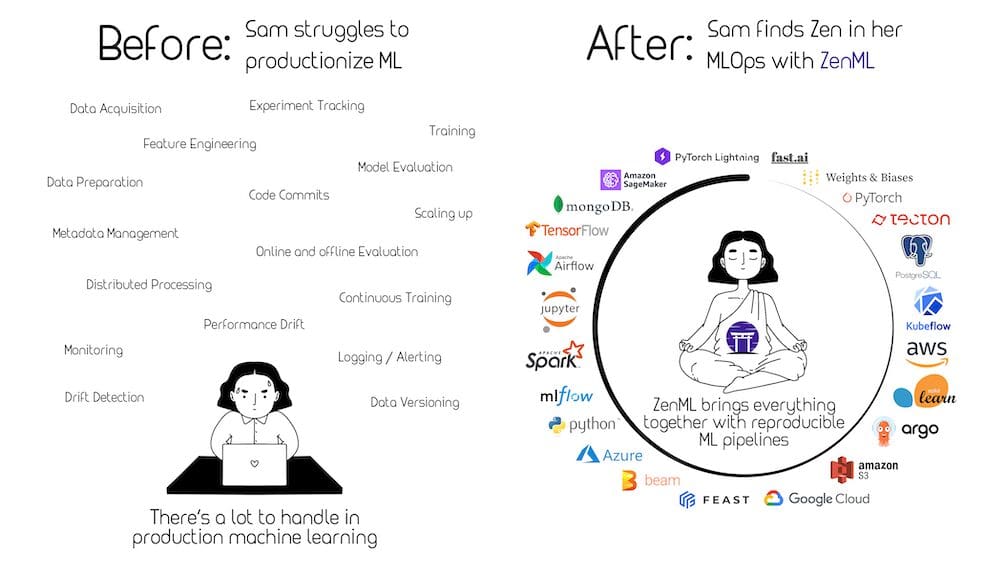
ZenMLは拡張可能なオープンソースのMLOpsフレームワークであり、MLの再現性、保守性、スケーラビリティを実現するために設計されています。ZenMLは非常に拡張性と適応性のあるMLOpsフレームワークであり、さまざまな機械学習のコンポーネント、ライブラリ、フレームワークを簡単に統合してエンドツーエンドのパイプラインを構築することができます。ZenMLのモジュラーな設計により、データサイエンティストやエンジニアはパイプライン内の特定のタスクに異なるMLフレームワークやツールを組み合わせることが容易になり、さまざまなツールやフレームワークの統合の複雑さを軽減することができます。
以下はZenMLが優れているいくつかの領域です:
- MLパイプラインの抽象化:ZenMLはシンプルな抽象化を使用してMLパイプラインを定義するためのクリーンなPythonicな方法を提供し、データの取り込み、前処理、トレーニング、評価など、MLライフサイクルの異なるステージを簡単に作成および管理することができます。
- 再現性:ZenMLは再現性に重点を置いており、パイプラインコンポーネントが正確なメタデータシステムを介してバージョン管理され、追跡されることを保証しています。これにより、不安定な環境、データ、または依存関係に関連する問題を防ぎ、ML実験を一貫して複製することができます。
- バックエンドオーケストレータの統合:ZenMLはApache Airflow、Kubeflowなどのさまざまなバックエンドオーケストレータをサポートしています。この柔軟性により、ユーザーは自身のニーズやインフラに最適なバックエンドを選択することができます。ローカルマシン、Kubernetes、またはクラウド環境でパイプラインを管理します。
- 拡張性:ZenMLは高度に拡張可能なアーキテクチャを提供し、ユーザーは異なるパイプラインステップのためにカスタムロジックを記述し、好みのツールやライブラリと簡単に統合することができます。これにより、組織はZenMLを特定の要件とワークフローに合わせてカスタマイズすることができます。
- データセットのバージョニング:ZenMLは効率的なデータ管理とバージョニングに重点を置いており、パイプラインが正しいバージョンのデータとアーティファクトにアクセスできるようにします。組み込みのデータ管理システムにより、さまざまなパイプライン実行間でデータの一貫性を維持し、MLワークフローの透明性を促進することができます。
- 主要なMLフレームワークとの高い統合性:ZenMLはTensorFlow、PyTorch、Scikit-learnなどの人気のあるMLフレームワークとのスムーズな統合を提供します。これらのMLライブラリとの連携能力により、実践者は既存のスキルとツールを活用しながら、ZenMLのパイプライン管理を行うことができます。
要約すると、ZenMLはクリーンなパイプラインの抽象化、再現性の確保、さまざまなバックエンドオーケストレータのサポート、拡張性の提供、効率的なデータセットのバージョニング、人気のあるMLライブラリとの統合に優れています。これらの側面に焦点を当てることで、ZenMLはインフラストラクチャを新しいツールに大きく移行することなく、MLワークフローの保守性、再現性、スケーラビリティを向上させたい組織に特に適しています。
私にとって最適なツールは何ですか?
数多くのMLOpsツールが利用可能ですが、自分やチームに最適なものをどのように選べば良いでしょうか?潜在的なMLOpsソリューションを評価する際には、いくつかの要素が重要となります。以下は、組織の特定のニーズと目標に合わせたMLOpsツールを選ぶ際に考慮すべき重要な要素です:
- 組織の規模とチームの構造:データサイエンスとエンジニアリングのチームの規模、専門知識のレベル、そして彼らがどれだけ協力する必要があるかを考慮してください。大きなグループや複雑な階層構造では、堅牢な協力とコミュニケーション機能を備えたツールが役立つ場合があります。
- MLモデルの複雑さと多様性:組織で使用されるアルゴリズム、モデルアーキテクチャ、および技術の範囲を評価してください。一部のMLOpsツールは特定のフレームワークやライブラリに対応していますが、他のツールはより包括的で多目的なサポートを提供しています。
- 自動化とスケーラビリティのレベル:データの前処理、モデルのトレーニング、展開、監視などのタスクに対してどれだけ自動化が必要かを判断してください。また、組織でのスケーラビリティの重要性を理解してください。一部のMLOpsツールは、計算のスケーリングや大量のデータの処理に対してより良いサポートを提供しています。
- 統合と互換性:MLOpsツールが既存の技術スタック、インフラストラクチャ、ワークフローとの互換性を考慮してください。現行システムとのシームレスな統合は、採用プロセスをスムーズにし、進行中のプロジェクトへの影響を最小限に抑えることができます。
- カスタマイズと拡張性:MLワークフローに必要なカスタマイズと拡張性のレベルを評価してください。一部のツールはより柔軟なAPIやプラグインアーキテクチャを提供しており、特定の要件を満たすためのカスタムコンポーネントの作成が可能です。
- コストとライセンス:MLOpsツールの価格体系とライセンスオプションを考慮してください。これにより、組織の予算とリソース制約に合致することが保証されます。
- セキュリティとコンプライアンス:MLOpsツールがセキュリティ、データプライバシー、およびコンプライアンス要件にどれだけ対応しているかを評価してください。規制された業界で活動している組織や機密データを扱っている組織にとって、これは特に重要です。
- サポートとコミュニティ:ドキュメンテーションの品質、コミュニティサポート、プロフェッショナルな支援の提供状況を考慮してください。能動的なコミュニティと迅速なサポートは、課題の解決やベストプラクティスの検索時に価値があります。
これらの要素を慎重に検討し、組織のニーズと目標に合わせて調整することで、MLワークフローを最も効果的にサポートし、成功するMLOps戦略を実現するための適切なMLOpsツールを選択できます。
MLOpsのベストプラクティス
MLOpsにおけるベストプラクティスの確立は、高品質なMLモデルの開発、展開、および維持を目指す組織にとって重要です。以下のプラクティスを実施することで、データの一貫性、モデルの時系列データのバージョン管理、および開発のスピードと品質を向上させることができます。これにより、データの不整合、古いモデル、または開発の遅延やエラーのリスクが最小限に抑えられます:
- データの品質と一貫性の確保:堅牢な前処理パイプラインの確立、Great ExpectationsやTensorFlow Data Validationなどの自動データ検証チェックツールの使用、およびデータストレージ、アクセス、および処理ルールを定義するデータガバナンスポリシーの実装を行ってください。データ品質の管理が不十分な場合、不正確またはバイアスのかかったモデルの結果が生じ、意思決定の質が低下し、ビジネスの損失が発生する可能性があります。
- データとモデルのバージョン管理:GitやDVCなどのバージョン管理システムを使用して、データとモデルの変更履歴を追跡し、チームメンバー間の混乱を減らしてください。たとえば、DVCを使用すると、データセットとモデルの実験の異なるバージョンを管理し、簡単に切り替え、共有、再現することができます。バージョン管理により、チームは複数のイテレーションを管理し、過去の結果を再現して分析することができます。
- 協力的で再現性のあるワークフロー:明確なドキュメンテーション、コードレビュープロセス、標準化されたデータ管理、およびJupyter NotebooksやSaturn Cloudのような協力ツールとプラットフォームの実装により、協力を促進してください。チームメンバーが効率的かつ効果的に協力することをサポートすることで、高品質なモデルの開発を加速することができます。一方、協力的で再現性のあるワークフローを無視すると、開発が遅くなり、エラーのリスクが増加し、知識の共有が妨げられます。
- 自動化されたテストと検証:自動化されたテストと検証手法(Pytestなどのユニットテスト、統合テストなど)をMLパイプラインに統合し、GitHub ActionsやJenkinsなどの継続的統合ツールを活用して、定期的にモデルの機能をテストしてください。自動化されたテストは、デプロイ前に問題を特定し修正するのに役立ち、本番環境での高品質で信頼性のあるモデルのパフォーマンスを保証します。自動化されたテストをスキップすると、検出されない問題のリスクが高まり、モデルのパフォーマンスが損なわれ、最終的にビジネスの成果に悪影響を与える可能性があります。
- モニタリングとアラートシステム:Amazon SageMaker Model Monitor、MLflow、またはカスタムのソリューションなどのツールを使用して、主要なパフォーマンスメトリックスを追跡し、早期に問題を検出するためのアラートを設定してください。たとえば、モデルのドリフトが検出された場合や特定のパフォーマンスの閾値が超えられた場合にMLflowでアラートを設定します。モニタリングとアラートシステムを実装しないと、モデルのドリフトやパフォーマンスの低下などの問題の検出が遅れ、古いまたは不正確なモデル予測に基づいた最適でない意思決定が行われ、全体的なビジネスのパフォーマンスに悪影響を与える可能性があります。
これらのMLOpsのベストプラクティスに従うことで、組織はMLモデルを効率的に開発、展開、および維持することができ、潜在的な問題を最小限に抑え、モデルの効果と全体的なビジネスへの影響を最大化することができます。
MLOpsとデータセキュリティ
データセキュリティは、MLOpsの成功した実装において重要な役割を果たします。組織は、MLライフサイクルの各段階でデータとモデルが安全かつ保護されていることを保証するために必要な予防措置を講じる必要があります。MLOpsにおけるデータセキュリティを確保するための重要な考慮事項は次のとおりです。
- モデルの堅牢性:MLモデルが敵対的な攻撃に耐えたり、ノイズや予期しない状況で信頼性を持って動作することを確認します。例えば、敵対的なトレーニングと呼ばれる手法を取り入れることができます。これは、トレーニングプロセスに敵対的な例を注入することで、モデルの耐性を向上させるものです。定期的なモデルの堅牢性の評価は、誤った予測やシステムの障害を引き起こす可能性のある悪用を防ぐのに役立ちます。
- データのプライバシーとコンプライアンス:機密データを保護するために、組織は一般データ保護規則(GDPR)や健康保険携帯性責任法(HIPAA)などの関連するデータプライバシーとコンプライアンスの規制に従う必要があります。これには、堅牢なデータガバナンスポリシーの実施、機密情報の匿名化、データマスキングや匿名化などの手法の利用が含まれる場合があります。
- モデルのセキュリティと完全性:MLモデルのセキュリティと完全性を確保することで、モデルが未承認のアクセス、改ざん、または盗難から保護されます。組織は、モデルアーティファクトの暗号化、安全なストレージ、およびモデル署名などの手法を実装することで、モデルの正当性を検証し、外部の関与による危険性や操作のリスクを最小限に抑えることができます。
- 安全な展開とアクセス制御:MLモデルを本番環境に展開する際には、迅速な展開のためのベストプラクティスに従う必要があります。これには、潜在的な脆弱性の特定と修正、安全な通信チャネル(HTTPSやTLSなど)の実装、および認証されたユーザーのみがモデルにアクセスできるようにするための厳格なアクセス制御メカニズムの強制が含まれます。組織は、役割ベースのアクセス制御やOAuthやSAMLなどの認証プロトコルを使用して、未承認のアクセスを防止し、モデルのセキュリティを維持することができます。
セキュリティチーム(例:レッドチーム)をMLOpsサイクルに組み込むことで、全体的なシステムのセキュリティを大幅に向上させることも可能です。例えば、レッドチームはモデルやインフラストラクチャに対する敵対的な攻撃をシミュレートし、気付かれない脆弱性や弱点を特定するのに役立ちます。この積極的なセキュリティアプローチにより、組織は問題が脅威になる前に対処し、規制の遵守を確保し、MLソリューションの全体的な信頼性と信頼性を向上させることができます。MLOpsサイクル中に専任のセキュリティチームと協力することは、MLプロジェクトの成功に貢献する堅牢なセキュリティ文化を育むことにつながります。
業界でのMLOpsの実例
MLOpsは、さまざまな業界で成功裏に実施され、効率、自動化、および全体的なビジネスパフォーマンスの改善をもたらしています。以下は、異なるセクターでのMLOpsの潜在能力と効果を示す実際の例です:
CareSourceによるヘルスケア
CareSourceは、アメリカ合衆国で最大の医療扶助プロバイダーの1つであり、高リスク妊娠のトリアージと医療提供者とのパートナーシップを重視し、救命の産科ケアを積極的に提供しています。しかし、いくつかのデータのボトルネックが解決される必要がありました。CareSourceのデータは、異なるシステムに分散しており、常に最新のものではなかったため、アクセスや分析が困難でした。モデルのトレーニングに関しては、データが一貫した形式でない場合があり、クリーニングや分析の準備が困難でした。
これらの課題に対処するため、CareSourceは、Databricks Feature Store、MLflow、およびHyperoptを使用したMLOpsフレームワークを導入し、産科リスクを予測するためのMLモデルの開発、チューニング、およびトラッキングを行いました。その後、デプロイメントのための本番準備テンプレートをインスタンス化し、予測結果をタイムリーなスケジュールで医療パートナーに送信するためにStacksを使用しました。
ML開発と本番準備のデプロイメント間の加速した移行により、CareSourceは遅すぎる前に患者の健康と生活に直接影響を与えることができました。例えば、CareSourceは高リスク妊娠を早期に特定することで、母親と赤ちゃんの結果を改善しました。また、不必要な入院を防ぐことで、医療費を削減しました。
Moody’s Analyticsによる金融
Moody’s Analyticsは、金融モデリングのリーダーであり、ツールやインフラストラクチャへのアクセス制限、モデル開発と配信の摩擦、および分散したチーム間の知識の隔たりなどの課題に直面しました。彼らは、クレジットリスク評価や財務諸表分析など、さまざまなアプリケーションにMLモデルを開発および利用しました。これらの課題に対応するため、彼らはDominoデータサイエンスプラットフォームを導入し、エンドツーエンドのワークフローを効率化し、データサイエンティスト間の効率的なコラボレーションを可能にしました。
Moody’s Analyticsは、Dominoを活用することで、モデルの開発を加速し、9か月かかっていたプロジェクトを4か月に短縮し、モデルのモニタリング能力を大幅に向上させました。この変革により、同社はクライアントのニーズに合わせたカスタマイズされた高品質のモデルを効率的に開発・提供することができるようになりました。リスク評価や財務分析など、クライアントのニーズに応じたモデルの開発・提供が可能となりました。
Netflixとのエンターテイメント
Netflixは、Metaflowを活用して、パーソナライズされたコンテンツの推薦、ストリーミング体験の最適化、コンテンツの需要予測、ソーシャルメディアのエンゲージメントの感情分析など、さまざまなアプリケーションのためのMLワークロードの開発、展開、管理を効率化しました。効率的なMLOpsのプラクティスを促進し、内部のワークフローに人間中心のフレームワークを適用することで、Netflixはデータサイエンティストが迅速に実験し、反復することができるようになり、より敏捷で効果的なデータサイエンスの実践を実現しました。
Netflixの元機械学習インフラストラクチャマネージャであるVille Tuulosによれば、Metaflowの導入により、プロジェクトのアイデアから展開までの平均時間が4か月からわずか1週間に短縮されました。この加速されたワークフローは、MLOpsと専用のMLインフラストラクチャの変革的な影響を示しており、MLチームがより迅速かつ効率的に運営できるようになりました。機械学習をビジネスのさまざまな側面に統合することで、NetflixはMLOpsのプラクティスの価値と可能性を示し、産業を革新し、全体的なビジネスの運営を改善するための大きな利点を提供しています。
MLOpsの教訓
前述のケースからわかるように、MLOpsの成功した実装は、ビジネスのさまざまな側面で劇的な改善をもたらす効果的なMLOpsのプラクティスの重要性を示しています。実際の経験から得られた教訓により、組織におけるMLOpsの重要性に関する重要な洞察を得ることができます:
- MLライフサイクルを簡素化するための標準化、統一されたAPI、および抽象化。
- プロセスを効率化し、複雑さを減らすために複数のMLツールを1つの一貫したフレームワークに統合する。
- 再現性、バージョン管理、実験の追跡などの重要な課題に対処し、効率性と協力を向上させる。
- データサイエンティストの特定のニーズに合わせた人間中心のフレームワークを開発し、摩擦を減らし、迅速な実験と反復を促進する。
- モデルが関連性、正確性、効果を保持し続けるために、本番環境でモデルを監視し、適切なフィードバックループを維持する。
Netflixや他の実際のMLOpsの実装から得られる教訓は、自社のML能力を向上させたい組織にとって貴重な洞察を提供することができます。これらの教訓は、よく考えられた戦略を持ち、堅牢なMLOpsのプラクティスに投資することの重要性を強調しており、価値を生み出し、スケーリングし、変化するビジネスニーズに適応する高品質なMLモデルを開発、展開、維持するための手段を提供しています。
MLOpsの将来のトレンドと課題
MLOpsは進化し成熟していく中で、組織はMLOpsのプラクティスを実装する際に直面する可能性のある新たなトレンドと課題に注意を払う必要があります。いくつかの注目すべきトレンドと潜在的な障害には以下があります:
- エッジコンピューティング:エッジコンピューティングの台頭により、組織はエッジデバイス上でMLモデルを展開することで、より高速でローカライズされた意思決定を可能にし、レイテンシを低減し、帯域幅のコストを削減する機会を得ることができます。エッジコンピューティング環境でのMLOpsの実装には、デバイスのリソースの制約、セキュリティ、接続性の制約を考慮したモデルのトレーニング、展開、モニタリングのための新しい戦略が必要です。
- 説明可能なAI:AIシステムが日常のプロセスや意思決定により重要な役割を果たすようになるにつれ、組織は自社のMLモデルが説明可能で透明で偏りのないものであることを確保する必要があります。これには、モデルの解釈可能性、可視化のためのツールの統合、バイアスの軽減技術などが必要です。説明可能で責任あるAIの原則をMLOpsのプラクティスに組み込むことで、ステークホルダーの信頼を高め、規制要件に準拠し、倫理基準を守ることができます。
- 高度なモニタリングとアラート:MLモデルの複雑さとスケールが増すにつれて、組織は十分なパフォーマンスを維持するためにより高度なモニタリングとアラートシステムが必要になる場合があります。異常検知、リアルタイムフィードバック、適応的なアラート閾値などの技術を活用することで、モデルのドリフト、パフォーマンスの低下、データ品質の問題などを迅速に特定し、診断することができます。これらの高度なモニタリングとアラートの技術をMLOpsのプラクティスに統合することで、組織は問題が発生した際に迅速に対処し、MLモデルの正確性と信頼性を一貫して高いレベルで維持することができます。
- フェデレーテッドラーニング:このアプローチにより、分散されたデータソース上でMLモデルのトレーニングを行いながらデータプライバシーを維持することができます。組織は、機密データを公開することなく、分散トレーニングや複数の利害関係者間の協力を可能にするため、フェデレーテッドラーニングによって利益を得ることができます。
- ヒューマンインザループプロセス:主観的な意思決定や完全にエンコードできない複雑なコンテキストを含む多くのMLアプリケーションに人間の専門知識を組み込むことへの関心が高まっています。ヒューマンインザループプロセスをMLOpsワークフローに統合するためには、効果的なコラボレーションツールと戦略が必要です。
- 量子ML:量子コンピューティングは、複雑な問題の解決や特定のMLプロ
結論
今日の世界において、MLOpsの実装は、MLのフルポテンシャルを引き出し、ワークフローを効率化し、モデルのライフサイクル全体で高性能なモデルを維持することを目指す組織にとって重要な要素となっています。この記事では、MLOpsのプラクティスとツール、さまざまな業界でのユースケース、データセキュリティの重要性、そしてフィールドが進化し続ける中での機会と課題について探ってきました。
以下の内容をまとめてみましょう:
- MLOpsライフサイクルの段階。
- 選択したインフラストラクチャに展開できる人気のあるオープンソースのMLOpsツール。
- MLOpsの実装のためのベストプラクティス。
- さまざまな業界でのMLOpsのユースケースと貴重なMLOpsの教訓。
- エッジコンピューティング、説明可能性と責任あるAI、およびヒューマンインザループプロセスなど、将来のトレンドと課題。
MLOpsの環境は絶えず進化しているため、組織や実践者は最新のプラクティス、ツール、研究について常に最新情報を得る必要があります。継続的な学習と適応を重視することで、企業は常に最新の状況に応じてMLOps戦略を洗練させ、新たなトレンドや課題に効果的に対応することができます。
MLのダイナミックな性質とテクノロジーの急速な進歩のペースは、組織がMLOpsソリューションを繰り返し改善し、進化させる準備をする必要があることを意味します。これには、新しい技術やツールの採用、チーム内での協力的な学習文化の育成、知識の共有、広範なMLOpsコミュニティからの洞察の追求が含まれます。
MLOpsのベストプラクティスを採用し、データセキュリティと倫理的なAIに重点を置き、新たなトレンドに対応するために敏捷性を維持する組織は、MLへの投資の価値を最大化するためにより良い位置に立つことができます。あらゆる業界の企業がMLを活用する中で、AI駆動のソリューションの成功、責任ある展開、持続可能性を確保するためにMLOpsはますます重要になっていくでしょう。堅牢かつ将来に対応したMLOps戦略を採用することで、組織はMLの真の潜在能力を引き出し、各分野で変革を促進することができます。 Honson Tranは、人類のための技術の向上に取り組んでいます。彼は非常に好奇心旺盛な人物で、テクノロジー全般が大好きです。フロントエンド開発から人工知能や自動運転まで、どれも大好きです。彼にとって一日の終わりに重要なのは、技術に新しい貢献を毎晩提供できるかどうかです。彼は10年以上のIT経験と5年のプログラミング経験を持ち、新しいアイデアを提案して実装するための絶え間ないエネルギーを持っています。彼はいつまでも自分の仕事に夢中です。彼にとって墓地で一番裕福になることは重要ではありません。毎晩就寝する前に自分が技術に新しいものを貢献したと言えること、それが彼にとって重要なことです。
オリジナル。許可を得て転載されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






