畳み込みニューラルネットワークの包括的なガイド
Comprehensive Guide to Convolutional Neural Networks
人工知能は、人間と機械の能力のギャップを埋めるために、画期的な成長を遂げています。研究者や愛好家たちは、さまざまな分野で素晴らしいことを成し遂げるために取り組んでいます。そのような多くの分野の1つが、コンピュータビジョンの領域です。
この分野の目的は、機械が人間と同じように世界を見、同様に知覚し、画像やビデオ認識、画像分析・分類、メディア再生、推薦システム、自然言語処理などの多数のタスクに知識を利用できるようにすることです。ディープラーニングによるコンピュータビジョンの進歩は、主に1つの特定のアルゴリズムである畳み込みニューラルネットワークによって構築され、完璧にされてきました。
はじめに

畳み込みニューラルネットワーク(ConvNet/CNN)は、入力画像を受け取り、画像内のさまざまな要素/オブジェクトに重要性(学習可能な重みとバイアス)を割り当て、それらを区別することができるディープラーニングアルゴリズムです。ConvNetで必要な前処理は、他の分類アルゴリズムに比べてはるかに低くなります。原始的な方法ではフィルタは手動で作成されますが、十分な訓練により、ConvNetはこれらのフィルタ/特徴を学習することができます。
ConvNetのアーキテクチャは、人間の脳のニューロンの接続パターンと類似しており、視覚皮質の組織からインスピレーションを得ています。個々のニューロンは、受容野として知られる視野の制限された領域にのみ刺激に反応します。そのような領域のコレクションは、全視野をカバーするためにオーバーラップします。
フィードフォワードニューラルネットワークよりもConvNetを選ぶ理由
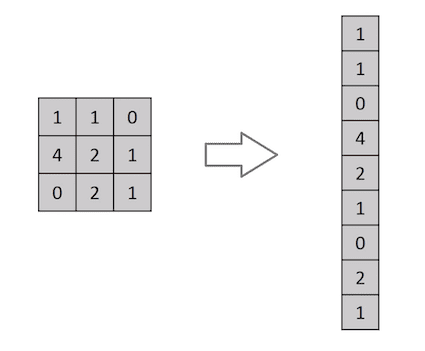
画像は、ピクセル値の行列に過ぎません。だから、画像をフラット化して(たとえば、3×3の画像行列を9×1のベクトルに)分類の目的に使用しない理由はありませんが、複雑な画像については精度が低くなります。
ConvNetは、関連するフィルタを適用することで、画像内の空間的および時間的な依存関係を正確に捕捉することができます。アーキテクチャは、関与するパラメータの数の削減と重みの再利用により、画像データセットに適した適合性を持ちます。つまり、ネットワークは、画像の複雑さをよりよく理解するために訓練されることができます。
入力画像
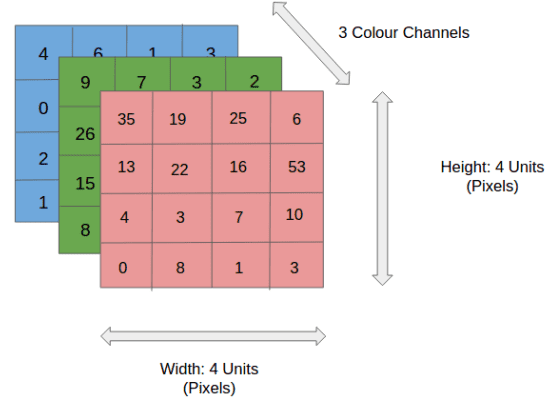
上の図では、RGB画像が赤、緑、青の3つの色平面に分離されています。画像が存在する色空間には、グレースケール、RGB、HSV、CMYKなどがあります。
イメージが8K(7680×4320)のサイズになると、計算が非常に複雑になることが想像できます。ConvNetの役割は、処理が容易になるように画像を縮小することであり、良好な予測に重要な特徴を失うことがないようにすることが重要です。これは、特徴を学習するだけでなく、膨大なデータセットにも拡張可能なアーキテクチャを設計する場合に重要です。
畳み込み層-カーネル

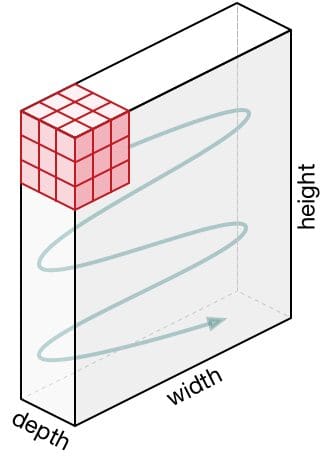
画像の寸法=5(高さ)x 5(幅)x 1(チャンネル数、例:RGB)
上記のデモンストレーションでは、緑のセクションが私たちの5x5x1の入力画像Iに似ています。畳み込み層の最初の部分で畳み込み演算に関与する要素はカーネル/フィルタKと呼ばれ、黄色で表されます。私たちはKを3x3x1の行列として選択しました。
Kernel/Filter, K =
1 0 1
0 1 0
1 0 1ストライド長=1(非ストライド)のため、カーネルは9回シフトし、カーネルがホバリングする画像の部分PとKの要素ごとの乗算操作(Hadamard Product)を実行します。
フィルターは、特定のストライド値で右に移動して、完全な幅を解析するまで移動します。次に、同じストライド値で画像の開始(左)に移動して、画像全体が走査されるまでこのプロセスを繰り返します。
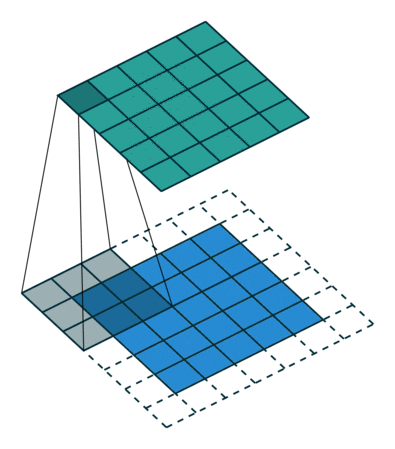
複数のチャンネル(例:RGB)を持つ画像の場合、カーネルの深さは入力画像と同じです。 KnおよびInスタック([K1、I1]; [K2、I2]; [K3、I3])間で行列乗算が実行され、すべての結果がバイアスと合算されて、圧縮された1深度チャネル畳み込みフィーチャ出力が得られます。

畳み込み操作の目的は、入力画像からエッジなどの高レベルの特徴を抽出することです。 ConvNetsは、1つの畳み込み層に限定される必要はありません。従来、最初のConvLayerは、エッジ、色、勾配方向などの低レベルの特徴をキャプチャする責任を持っています。追加の層を加えることで、アーキテクチャは高レベルの特徴にも適応し、データセット内の画像についての私たちの理解に似たネットワークを提供します。
この操作の結果には、入力に比べて次元が低下するものと、次元が増加するか、同じままのものがあります。これは、前者の場合には有効なパディングを適用し、後者の場合には同じパディングを適用することによって行われます。
5x5x1画像を6x6x1画像に拡張してから3x3x1カーネルを適用すると、畳み込まれた行列のサイズが5x5x1になることがわかります。したがって、名前はSame Paddingです。
一方、パディングなしで同じ操作を行うと、カーネル(3x3x1)自体のサイズの行列が得られます-有効なパディング。
次のリポジトリには、パディングとストライド長がどのように協力して、私たちのニーズに関連する結果を達成するのかをより良く理解するのに役立つ多くのGIFが含まれています。
vdumoulin/conv_arithmetic A technical report on convolution arithmetic in the context of deep learning – vdumoulin/conv_arithmeticgithub.com
プーリング層
プーリング層は、畳み込まれたフィーチャの空間サイズを減少させる責任があります。これは、次元削減を通じてデータを処理するために必要な計算能力を減らすためです。さらに、回転および位置に関して不変な主要な特徴を抽出するのに役立ち、モデルの効果的なトレーニングのプロセスを維持するために役立ちます。
プーリングには2種類あります:MaxプーリングとAverageプーリングです。 Maxプーリングは、カーネルでカバーされる画像の部分から最大値を返します。一方、Averageプーリングは、カーネルでカバーされる画像の部分からすべての値の平均値を返します。
Maxプーリングはまた、ノイズ抑制機能として機能します。ノイズのあるアクティベーションをまったく破棄し、次元削減と一緒にノイズ除去を実行します。一方、Averageプーリングは、ノイズ抑制メカニズムとして次元削減を単に実行します。したがって、MaxプーリングはAverageプーリングよりもはるかに優れたパフォーマンスを発揮します。
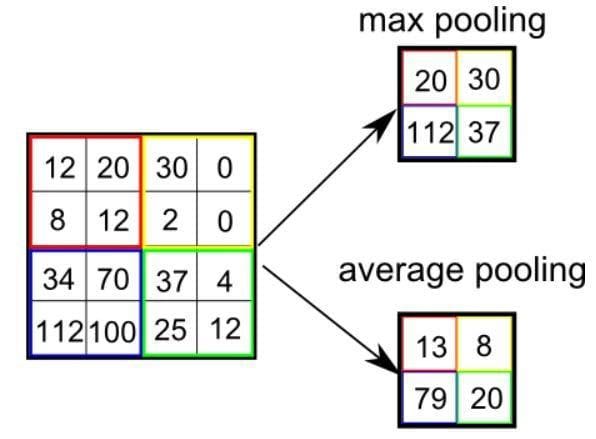 プーリングの種類
プーリングの種類
畳み込み層とプーリング層は、畳み込みニューラルネットワークのi番目の層を形成します。画像の複雑さに応じて、このような層の数を増やして、さらに低レベルの詳細を捉えることができますが、より多くの計算能力が必要になります。
上記のプロセスを経た後、モデルが特徴を理解できるようになりました。次に、最終出力をフラット化して、分類目的のために通常のニューラルネットワークにフィードします。
分類-完全接続層(FC層)
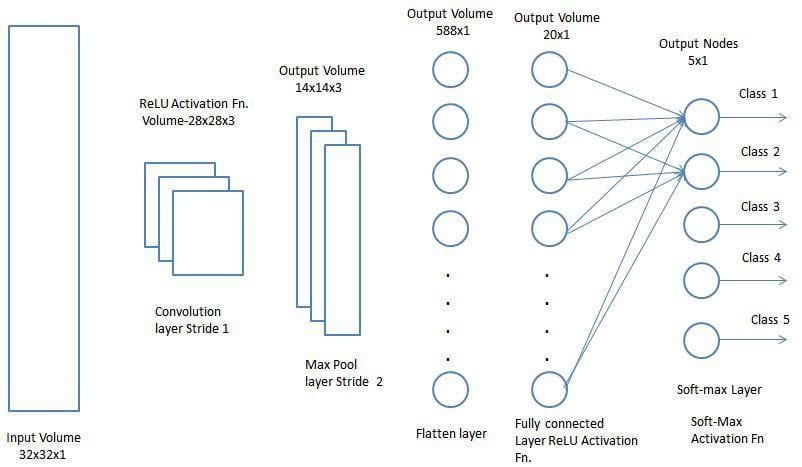
完全接続層を追加することは、畳み込み層の出力によって表される高レベルの特徴の非線形の組み合わせを学習する(通常)安価な方法です。完全接続層は、その空間で可能性のある非線形関数を学習しています。
現在、入力画像をMulti-Level Perceptronに適した形式に変換したので、画像を列ベクトルにフラット化します。フラット化された出力は、順方向のニューラルネットワークにフィードされ、トレーニングの各イテレーションに対してバックプロパゲーションが適用されます。一連のエポックを経て、モデルは画像の支配的な低レベルの特徴と特定の特徴を区別し、ソフトマックス分類技術を使用してそれらを分類できるようになります。
将来にわたってAIを支えているアルゴリズムを構築する上で、CNNのさまざまなアーキテクチャが利用可能です。以下にいくつか挙げています。
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
Sumit Sahaは、現在AI駆動の製品を開発しているデータサイエンティストおよび機械学習エンジニアです。彼は、特に医療とヘルスケアの領域において、社会的な利益のためのAIの応用に情熱を持っています。時々技術ブログも書いています。
Original . Reposted with permission.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






