CleanLabを使用してデータセットのラベルエラーを自動的に検出する
CleanLabを使用してラベルエラーを自動的に検出する
AIと誤分類されたブラジル連邦法の物語
はじめに
数週間前、私は私の個人プロジェクトを開発するためのデータセットを通常の検索中に、ブラジル下院オープンデータポータルに出会いました。このポータルには、議員の経費、政党のメタデータなど、多くのデータが含まれており、すべてが使いやすいAPIを介して利用できます。
数時間の検索と調査の後、非常に興味深いものが目に留まりました:議員によって提案されたすべての法律が、その「要旨」(簡潔な要約)、著者、年、そして何よりも重要なのは、そのテーマ(健康、セキュリティ、財政など…)についてのデータの編成が、下院の文書と情報センター(Centro de Documentação e Informação da Câmara)によって行われていることです。
私の頭にスパークが走りました。「私は監督付き分類のパイプラインを作成し、法律の要約を使用してそのテーマを予測することができる」と私は考えました。データのバージョニングにDVCなどの機械学習のインフラの側面を探索します。私はすぐにスクリプトを書き、1990年から2022年までの期間にわたる60,000以上の法律を含む広範なデータセットを収集しました。
私はすでに司法と立法のデータを少し扱ったことがあるので、この作業は難しくないだろうと感じました。しかし、さらに簡単にするために、法案提案(LP)が「税金と記念日」に関するものかどうかのみを分類することにしました(2値分類)。理論的には簡単なはずです。テキストは非常にシンプルです:
- DLISファイルからLASファイル形式へのウェルログデータの変換
- query()メソッドを使用してPandasデータフレームをクエリする方法
- データサイエンスのキャリアに転身する際に comitted した5つのミステイク

しかし、私が試してみたことは何であっても、私のパフォーマンスはf1スコアの約0.80のマークを超えませんでした。また、真のクラスに対する再現率(正例の場合)も0.5〜0.7と比較的低いです。
もちろん、私のデータセットは非常に不均衡であり、このクラスはデータセットのサイズのわずか5%未満を占めていますが、それ以上の問題があります。
調査を行い、正規表現ベースのクエリでデータを検査し、誤分類されたレコードを調べた結果、いくつかの誤ったラベル付けの例が見つかりました。私の素朴なアプローチで、真の陽性の約7.5%、全データセットの0.33%を占める偽陰性の約200件を見つけました。さらに、偽陽性については言及しません。以下にいくつかの例を示します:
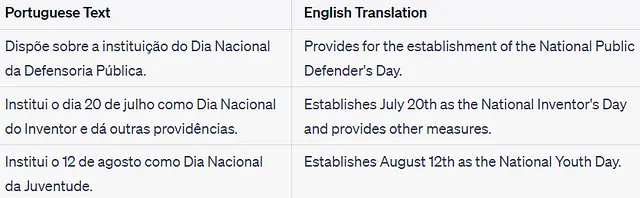
これらの例は、私の検証指標を悪化させていました。「これらの例はいくつ存在するのでしょうか?エラーを手動で検索する必要があるのでしょうか?」
しかし、そこで、Confident Learningが登場し、私を救ってくれるClean LabのPythonパッケージが現れました。
Confident Learningとは何ですか?
データの正しいラベル付けは、任意の監督学習プロジェクトで最も時間がかかり、費用のかかるステップの1つです。クラウドソーシング、半教師あり学習、微調整などの技術は、ラベルの収集コストを削減したり、モデルトレーニングにおけるそのようなラベルの必要性を減らしたりするために試みられています。
幸いなことに、私たちはこの問題の1歩前進しています。専門家によって提供されるラベルを持っています。おそらく適切なノウハウを持つ政府の職員から提供されたものです。しかし、私の素人の目と素朴な正規表現のアプローチでは、パフォーマンスの期待が外れるとすぐに間違いを見つけることができました。
ポイントは:データにまだいくつのエラーがあるのか?
各法律を検査するのは合理的ではありません — 自動的に 間違ったラベルを検出する方法が必要であり、それがConfident Learningです。
要約すると、Confident Learningはモデルの確率予測から収集された統計情報を使用して、データセット内のエラーを推定します。ノイズ、外れ値、そしてこの記事の主題であるラベルのエラーを検出できます。
CLの詳細には触れませんが、主要なポイントをカバーした素晴らしい記事と、CleanLabの作成者によるその研究についてのYTビデオがあります。
実際にどのように機能するか見てみましょう。
データ
データは、ブラジル下院の公開データポータルから収集されたもので、1990年から2022年までの法案提案(LP)を含んでいます。最終的なデータセットには約60,000件のLPが含まれています。
単一のLPには、健康や財政など、複数のテーマが関連付けられることがあり、この情報もオープンデータポータルで利用できます。扱いやすくするために、各個別のテーマをバイナリ化して別々の列にエンコードしました。
先にも述べたように、この記事で使用するテーマは「トリビュートと記念日」です。そのエメンタは非常に短くシンプルなため、ラベルのエラーを簡単に特定できます。
データとコードは、プロジェクトのGitHubリポジトリで入手できます。
実装
私たちの目標は、「トリビュートと記念日」というラベルのエラーをすべて自動的に修正し、きれいで使いやすいデータセットを機械学習の問題に使用できる状態でこの記事を終了することです。
環境のセットアップ
このプロジェクトを実行するために必要なのは、古典的なML/Data ScienceのPythonパッケージ(Pandas、Numpy & Scikit-Learn)とCleanLabパッケージです。
cleanlab==2.4.0scikit-learn==1.2.2pandas>=2.0.1numpy>=1.20.3これらの要件をインストールするだけで準備完了です。
CLによるラベルエラーの検出
CleanLabパッケージには、外れ値や重複/類似エントリなど、さまざまな種類のデータセットの問題を識別する機能が組み込まれていますが、私たちはラベルのエラーにのみ興味があります。
CleanLabは、機械学習モデルによって生成されるエントリが特定のラベルである確信度を表す確率を使用しています。データセットがn個のエントリとm個のクラスを持つ場合、これはn行m列の行列Pで表され、P[i, j]は行iがクラスjである確率を表します。
これらの確率と「真の」ラベルは、CleanLabの内部でエラーを推定するために使用されます。
実際にやってみましょう:
パッケージのインポート
import numpy as npimport pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import train_test_split, cross_val_score, cross_val_predictfrom sklearn.model_selection import GridSearchCV, StratifiedKFoldfrom sklearn.pipeline import Pipelinefrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scorefrom sklearn.metrics import confusion_matrix, classification_reportfrom cleanlab import DatalabRANDOM_SEED = 214np.random.seed(RANDOM_SEED)データのロード…
df_pls_theme = pd.read_parquet( '../../data/proposicoes_temas_one_hot_encoding.parquet')# "Tributes and commemorative dates"BINARY_CLASS = "Homenagens e Datas Comemorativas"IN_BINARY_CLASS = "in_" + BINARY_CLASS.lower().replace(" ", "_")df_pls_theme = df_pls_theme.drop_duplicates(subset=["ementa"])df_pls_theme = df_pls_theme[["ementa", BINARY_CLASS]]df_pls_theme = df_pls_theme.rename( columns={BINARY_CLASS: IN_BINARY_CLASS})まずは、確率を生成しましょう。
CleanLabのドキュメントで述べられているように、より良いパフォーマンスを得るためには、確率は「トレーニングではない」データ(アウトオブサンプルレコード)で生成されることが重要です。これは、モデルがトレーニングデータ上で確率を予測する際に自然に過信する傾向があるためです。データセットでアウトオブサンプルの確率を生成する最も一般的な方法は、以下のようにK-Fold戦略を使用することです:
y_proba = cross_val_predict( clean_pipeline, df_pls_theme['ementa'], df_pls_theme[IN_BINARY_CLASS], cv=StratifiedKFold(n_splits=5, shuffle=True, random_state=RANDOM_SEED), method='predict_proba', verbose=2, n_jobs=-1)注意:クラスの分布を把握することは重要です – そのためStratifiedKFoldオブジェクトが使用されています。選ばれたクラスはデータセットの5%未満を表し、ナイーブなサンプリングアプローチでは間違ってバランスが取られていないデータセットで訓練されたモデルによって生成される品質の低い確率が容易に生じる可能性があります。
CleanLabは、エラー検出ジョブを処理するためのDatalabと呼ばれるクラスを使用します。データが含まれるDataFrameとラベル列の名前を受け取ります。
lab = Datalab( data=df_pls_theme, label_name=IN_BINARY_CLASS,)さて、先ほど計算した確率を渡すだけです…
lab.find_issues(pred_probs=y_proba)…問題を見つけ始めるために
lab.get_issue_summary("label")
これほど簡単です。
get_issues(“label”)関数は、各レコードに対してCleanLabが計算したメトリックと指標を含むDataFrameを返します。最も重要な列は’is_label_issue’と’predicted_label’であり、それぞれレコードにラベルの問題があるかどうかと、それに対する可能な正しいラベルを表します。
lab.get_issues("label")これらの情報を元のDataFrameにマージして、問題のある例を調査することができます。
# Getting the predicted errorsy_clean_labels = lab.get_issues("label")[['predicted_label', 'is_label_issue']]# adding them to the original datasetdf_ples_theme_clean = df_pls_theme.copy().reset_index(drop=True)df_ples_theme_clean['predicted_label'] = y_clean_labels['predicted_label']df_ples_theme_clean['is_label_issue'] = y_clean_labels['is_label_issue']いくつかの例をチェックしましょう:


私にとって、これらの法律は明らかにトリビュートと記念日に関連していますが、適切に分類されていません。
素晴らしい! – CleanLabはデータセット内の312のラベルエラーを見つけることができましたが、今何をすればいいのでしょうか?
これらのエラーは、手動検査による修正(アクティブラーニングの方法で)の対象となるか、即座に修正される可能性があります(CleanLabが正しく機能したと仮定して)。前者は時間がかかりますが、より良い結果につながる可能性がありますが、後者は速く、より多くのエラーにつながる可能性があります。
選択したパスに関係なく、CleanLabは最悪の場合でも60,000件のレコードから数百件に作業量を減らしました。
ただし、注意が必要です。
CleanLabがデータセット内のすべてのエラーを見つけたことを確認する方法はありますか?
実際、上記のパイプラインを実行した場合、エラーが修正されたものが正解として与えられた場合、CleanLabはさらにエラーを見つけるでしょう…
さらにエラーが見つかるでしょうが、おそらく最初の実行よりも少ないエラーが見つかるでしょう。
このロジックを必要な回数繰り返すことができます:エラーを見つける、エラーを修正する、新しい推定されるより良い品質のラベルでモデルを再訓練する、再びエラーを見つける…
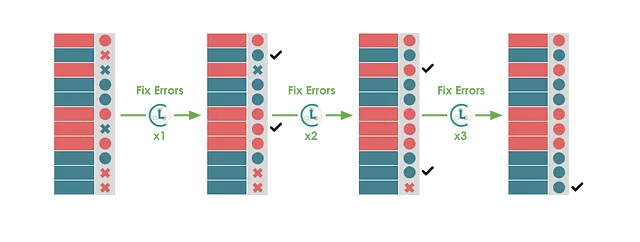
いくつかの反復の後、エラーの数がゼロになることを望んでいます。
CleanLabを使った反復的なエラー修正
このアイデアを実装するために必要なのは、上記のプロセスをループで繰り返すだけです。以下のコードがそれを行います:
それを見直しましょう。
各反復では、OOSの確率は前述のように生成されます:StratifiedKFoldを使用したcross_val_predictメソッドを使用します。現在の確率セット(各反復で)は、新しいDatalabオブジェクトの構築と新しいラベルの問題の検索に使用されます。
見つかった問題は現在のデータセットと統合され、修正されます。
私はオリジナルのものを置き換える代わりに、修正されたラベルを新しい列として追加する戦略を選びました。
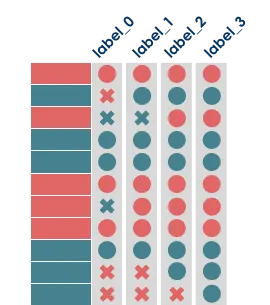
LABEL_COLUMN_0は元のラベル、LABEL_COLUMN_1は1回修正されたラベル列、LABEL_COLUMN_2は2回修正されたラベル列、依次となります…
このプロセスに加えて、通常の分類メトリクスも計算され、後で検査のために保存されます。
8回の反復(約16分)後、プロセスが終了します。
結果
以下の表は、プロセス中に計算されたパフォーマンスメトリクスを示しています。

8回の反復中にデータセット内で393のラベルエラーが見つかりました。予想どおり、反復ごとに見つかるエラーの数は減少しました。
このプロセスが6回の反復で「収束」し、「解決策」に到達したことは興味深いことです。最後の2回ではエラーが0のままでした。これは、この場合、CleanLabの実装が堅牢であり、振動につながる「偶然」のエラーを見つけることができなかったことを示す良い指標です。
エラーの数はデータセット全体のわずか0.6%を占めるに過ぎませんが、f1スコアは0.81から0.90、約11%増加しました。これは、クラスが非常に不均衡であるためであり、新しい322のポジティブラベルは元のポジティブ例の数の約12%を表します。
しかし、CleanLabは本当に意味のあるエラーを見つけることができたのでしょうか?いくつかの例をチェックしてみましょう。
間違った陰性が修正されました
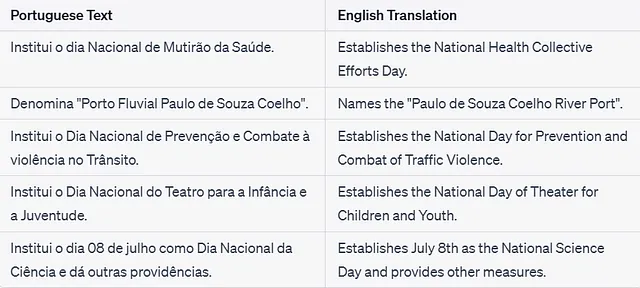
上記のテキストは確かに「賛辞と記念日」に似ているため、適切に分類されるべきであることを示しています – CleanLabにポイント
間違った陽性が修正されました

この場合、2番目と4番目の法律に誤った陽性があります。あまり良くありませんが、まだ大丈夫です。
私はこの検査を繰り返して、新しい「修正された」法律をサンプリングしましたが、一般的に、CleanLabは偽陰性を検出するのにほぼ完璧なパフォーマンスを発揮し、偽陽性に少し混乱します。
さて、私たちはおそらく完璧にラベル付けされたデータセットを持っているわけではありませんが、私はそれで機械学習モデルのトレーニングにはるかに自信を持っています。
結論
長い間、機械学習の分野は品質の低いモデルとコンピュータのパワー不足に苦しんできましたが、それはもはやありません。今では、ほとんどのMLアプリケーションの真のボトルネックはデータです。ただし、生データではなく、良いラベル、適切な形式で、ノイズや外れ値があまりない洗練されたデータです。
どれほど大きくて強力なモデルであろうと、パイプラインにどれほどの統計と数学を組み込もうとも、これらのいずれもコンピュータ科学の基本的な法則からは逃れることはできません:ゴミを入れればゴミが出ます。
そして、このプロジェクトはこの原則の証人でした。いくつかのモデル、ディープラーニングアーキテクチャ、サンプリング技術、ベクトル化手法をテストしましたが、結局のところ問題は基本的な部分にあったことを発見しました:私のデータが間違っていました。
このようなシナリオでは、データ品質の技術に投資することが成功したMLプロジェクトを作成するための重要な要素となります。
この記事では、私たちがデータセット内の間違ったラベルを検出して修正するのに役立ったCleanLabというパッケージについて調査しました。これにより、データセットの品質を大幅に向上させるだけでなく、人間の介入なしで自動的かつ再現可能かつ安価に行うことができました。
このプロジェクトがConfident LearningとCleanLabパッケージについて少し理解する助けになったことを願っています。いつものように、この記事で取り上げられたいずれの主題についても私は専門家ではなく、さらなる参考文献の読書を強くお勧めします。以下にいくつかの参考文献をご覧ください。
お読みいただき、ありがとうございました! 😉
参考文献
すべてのコードはこのGitHubリポジトリで入手できます。使用したデータ — 開放データポータル連邦会議 [開放データ — 法律第12号527号]すべての画像は、特に指定されていない限り、著者によって作成されています。
[1] Cleanlab. (n.d.). GitHub — cleanlab/cleanlab: The standard data-centric AI package for data quality and machine learning with messy, real-world data and labels. GitHub. [2] Computing Out-of-Sample Predicted Probabilities with Cross-Validation — cleanlab. (n.d.). [3] Databricks. (2022, July 19). CleanLab: AI to find and fix errors in ML datasets [Video]. YouTube. [4] FAQ — cleanlab. (n.d.). [5] Mall, S. (2023, May 25). Are label errors imperative? Is confident learning useful? VoAGI. [6] Northcutt, C. G. (2021). Confident Learning: Estimating uncertainty in Dataset labels. arXiv.org.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
