AWSにおけるマルチモデルエンドポイントのためのCI/CD
CI/CD for AWS Multi-Model Endpoints
持続可能なMLソリューションのためのシンプルで柔軟な代替案

製品の機械学習ソリューションの再トレーニングとデプロイを自動化することは、共変量シフトを考慮してモデルが限定的なエラーと不必要な人的手間に対応するために、重要なステップです。
AWSスタック、特にSageMakerを使用して展開されたモデルの場合、AWSはSageMakerパイプラインを使用して再トレーニング/デプロイを自動化し、SageMaker Model Registryを使用してモデルの系譜を追跡する標準のCI / CDソリューションを提供しています。
標準のソリューションは、標準的なケースに対してうまく機能しますが、より複雑なケースにはいくつかの制限があります:
- 入力データはAWS s3から入手する必要があります。
- 動的なウォームスタートハイパーパラメータチューニングの設定が難しい。
- 複数のモデルをトレーニングするために追加のモデルトレーニングステップが必要です。
- パイプラインを実行するための長いブートストラップ時間。
- 限られたデバッグツール。
幸いにも、AWSはこれらの制限を克服するために使用できる新機能を開始しました。次の機能は、機械学習の統合開発環境であるAWSのSageMaker Studio内でアクセスできます:
- 2023年5月のVoAGIトップ記事:Mojo Lang:新しいプログラミング言語
- 新たな能力が明らかに:GPT-4のような成熟したAIのみが自己改善できるのか?言語モデルの自律的成長の影響を探る
- 赤い猫&アテナAIは夜間視認能力を備えた知能化軍用ドローンを製造する
- カスタムSageMakerイメージの使用
- Git / SageMaker Studioの統合
- ウォームスタートハイパーパラメータチューニング
- SageMaker Studioノートブックジョブ
- クロスアカウントモデルレジストリ
本記事の目的…
は、AWSクラウドを介した代替CI / CDソリューションの主要な詳細について説明することです。より柔軟性があり、市場へのスピードが速くなります。
ソリューションコンポーネントの概要:
1. PostgreSQLクエリング用カスタムSageMaker Studioイメージ
2. 動的なウォームスタートハイパーパラメータチューニング
3.複数のモデルを単一のインタラクティブなPythonノートブックにモデルレジストリに登録する
4.新しいモデルでマルチモデルエンドポイントを更新する
5.再トレーニング/再デプロイノートブックを設定されたリズムで実行する
始めましょう。
1. PostgreSQLクエリング用カスタムSageMaker Studioイメージ
SageMakerパイプラインは、入力データをs3から取得できますが、AWS RedshiftやGoogle BigQueryのようなデータウェアハウスに新しい入力データがある場合はどうなりますか?もちろん、ETLまたは同等のプロセスを使用してデータをバッチでs3に移動できますが、それは単にパイプラインからデータを直接クエリすることに比べて不必要な複雑さ/剛性を追加します。
SageMaker Studioは、環境を初期化するためのいくつかのデフォルトイメージを提供しており、その一例が「Data Science」であり、numpyやpandasなどの一般的なパッケージが含まれています。ただし、PythonでPostgreSQLデータベースに接続するには、ドライバまたはアダプタが必要です。 Psycopg2は、Pythonプログラミング言語用の最も人気のあるPostgreSQLデータベースアダプタです。幸いなことに、カスタムイメージを使用してStudio環境を初期化できますが、特定の要件があります。私はこれらの要件を満たすDockerイメージを事前にパッケージ化し、Python Julia-1.5.2イメージにpsycopg2ドライバを追加して構築しました。イメージはこのgitリポジトリで見つけることができます。ここで説明されている手順を使用して、Studioドメインでイメージにアクセスできます。
2.動的なウォームスタートハイパーパラメータチューニング
モデルの再トレーニングは、初期モデルトレーニングとは性質が異なります。プロダクションモデルの最適なモデルハイパーパラメータを検索するために同じリソースを投資することは現実的ではありません。最後のプロダクションモデルから最適なハイパーパラメータに対するわずかな調整のみが期待される場合、特にそれは当てはまります。
そのため、この記事で推奨されるCI / CDのためのハイパーパラメータチューニングソリューションは、K倍交差検証、ウォームプールなどの追加の機能を使って再チューニングしようとするものではありません。これらはすべて、初期モデルトレーニングには非常に適しています。しかし、再トレーニングの場合、既にプロダクションでうまく機能しているものから始め、新しい利用可能なデータに対応するためにわずかな調整を行うことを望みます。そのため、ウォームスタートハイパーパラメータチューニングを使用するのは最適なソリューションです。さらに、最新のプロダクションチューニングジョブを親として使用する動的ウォームスタートチューニングシステムを作成できます。たとえば、XGBoostベイジアンチューニングジョブの場合、ソリューションは以下のようになります。:
# 実行パラメータを設定testing=Falsehyperparam_jobs=10# 最大ジョブ数を設定if testing==False: max_jobs=hyperparam_jobselse: max_jobs=1# パッケージをロードするfrom sagemaker.xgboost.estimator import XGBoostfrom sagemaker.tuner import IntegerParameterfrom sagemaker.tuner import ContinuousParameterfrom sagemaker.tuner import HyperparameterTunerfrom sagemaker.tuner import WarmStartConfig, WarmStartTypes# Warm Startを構成するnumber_of_parent_jobs=1# 5まで可能ですが、現在のコードでは1の値のみサポートされています。# base_dirが設定されている必要があることに注意してください。空白にも設定できます。try: eligible_parent_tuning_jobs=pd.read_csv(f"""{base_dir}logs/tuningjobhistory.csv""")except: eligible_parent_tuning_jobs=pd.DataFrame({'datetime':[],'tuningjob':[],'metric':[],'layer':[],'objective':[],'eval_metric':[],'eval_metric_value':[],'trainingjobcount':[]}) eligible_parent_tuning_jobs.to_csv(f"""{base_dir}logs/tuningjobhistory.csv""",index=False)eligible_parent_tuning_jobs=eligible_parent_tuning_jobs[(eligible_parent_tuning_jobs['layer']==prefix)&(eligible_parent_tuning_jobs['metric']==metric)&(eligible_parent_tuning_jobs['objective']==trainingobjective)&(eligible_parent_tuning_jobs['eval_metric']==objective_metric_name)&(eligible_parent_tuning_jobs['trainingjobcount']>1)].sort_values(by='datetime',ascending=True)eligible_parent_tuning_jobs_count=len(eligible_parent_tuning_jobs)if eligible_parent_tuning_jobs_count>0: parent_tuning_jobs=eligible_parent_tuning_jobs.iloc[(eligible_parent_tuning_jobs_count-(number_of_parent_jobs)):eligible_parent_tuning_jobs_count,1].iloc[0] warm_start_config = WarmStartConfig( WarmStartTypes.TRANSFER_LEARNING, parents={parent_tuning_jobs}) # 適用される場合はWarmStartTypes.IDENTICAL_DATA_AND_ALGORITHMを使用できます。 print(f"""調整ジョブを使ってウォームスタート: {parent_tuning_jobs[0]}""") else: warm_start_config = None# 探索範囲を定義する(Amazon SageMakerドキュメントからのデフォルトの提案値)hyperparameter_ranges = { 'eta': ContinuousParameter(0.1, 0.5, scaling_type='Logarithmic'), 'max_depth': IntegerParameter(0,10,scaling_type='Auto'), 'num_round': IntegerParameter(1,4000,scaling_type='Auto'), 'subsample': ContinuousParameter(0.5,1,scaling_type='Logarithmic'), 'colsample_bylevel': ContinuousParameter(0.1, 1,scaling_type="Logarithmic"), 'colsample_bytree': ContinuousParameter(0.5, 1, scaling_type='Logarithmic'), 'alpha': ContinuousParameter(0, 1000, scaling_type="Auto"), 'lambda': ContinuousParameter(0,100,scaling_type='Auto'), 'max_delta_step': IntegerParameter(0,10,scaling_type='Auto'), 'min_child_weight': ContinuousParameter(0,10,scaling_type='Auto'), 'gamma':ContinuousParameter(0, 5, scaling_type='Auto'),}tuner_log = HyperparameterTuner( estimator, objective_metric_name, hyperparameter_ranges, objective_type='Minimize', max_jobs=max_jobs, max_parallel_jobs=10, strategy='Bayesian', base_tuning_job_name="transferlearning", warm_start_config=warm_start_config)# SageMaker XGBoost estimatorを事前にインスタンス化する必要があることに注意training_input_config = sagemaker.TrainingInput("s3://{}/{}/{}".format(bucket,prefix,filename), content_type='csv')validation_input_config = sagemaker.TrainingInput("s3://{}/{}/{}".format(bucket,prefix,filename), content_type='csv')# bucket、prefix、およびfilenameオブジェクト/エイリアスを設定する必要があることに注意# ハイパーパラメータ調整ジョブを開始するtuner_log.fit({'train': training_input_config, 'validation': validation_input_config})# 最新のハイパーパラメータ調整ジョブのステータスを表示するboto3.client('sagemaker').describe_hyper_parameter_tuning_job( HyperParameterTuningJobName=tuner_log.latest_tuning_job.job_name)['HyperParameterTuningJobStatus']調整ジョブの履歴は、次のような例のように、ベースディレクトリにログファイルとして保存されます:
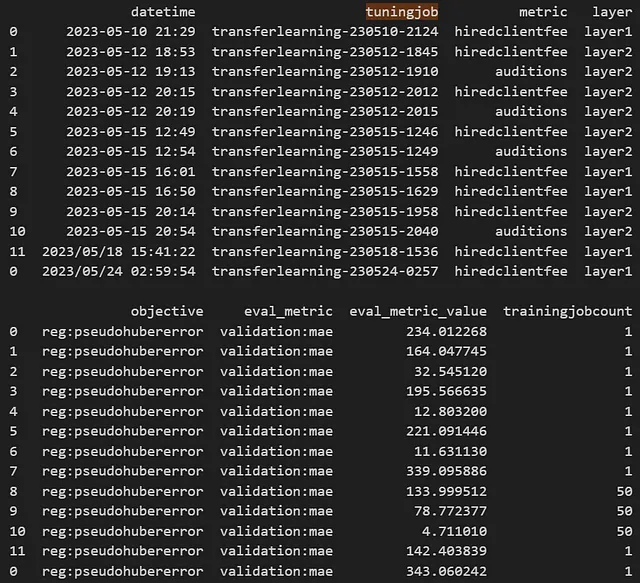
チューニングジョブの日時スタンプおよび名前とメタデータは、新しいチューニングジョブがファイルに追加される形式で .csv ファイルに格納されます。
システムは、必要な条件を満たす最新のチューニングジョブを使用して動的にウォームスタートします。この例では、次のコード行に条件が記載されています。
eligible_parent_tuning_jobs=eligible_parent_tuning_jobs[(eligible_parent_tuning_jobs['layer']==prefix)&(eligible_parent_tuning_jobs['metric']==metric)&(eligible_parent_tuning_jobs['objective']==trainingobjective)&(eligible_parent_tuning_jobs['eval_metric']==objective_metric_name)&(eligible_parent_tuning_jobs['trainingjobcount']>1)].sort_values(by='datetime',ascending=True)パイプラインが動作することをテストしたいため、testing=True の実行オプションが用意されており、1 つのハイパーパラメーターチューニングジョブのみが強制されます。テスト用のジョブであるため、調整されたモデルが 1 つだけのジョブのみを親として考慮する条件が追加されています。さらに、チューニングジョブログファイルは異なるモデル間でも使用できます。理論的には、親ジョブをモデル間で使用できるでしょう。 この場合、モデルは ‘metric’ フィールドで追跡され、対象のメトリックに一致するチューニングジョブに絞り込まれます。
再学習が完了した後、新しいハイパーパラメーターチューニングジョブをログファイルに追加し、バージョニングを有効にしてローカルに書き込み、s3 に書き込みます。
# Append Last Parent Job for Next Warm Starteligible_parent_tuning_jobs=pd.read_csv(f"""{base_dir}logs/tuningjobhistory.csv""")latest_tuning_job=boto3.client('sagemaker').describe_hyper_parameter_tuning_job( HyperParameterTuningJobName=tuner_log.latest_tuning_job.job_name)updatetuningjobhistory=pd.concat([eligible_parent_tuning_jobs,pd.DataFrame({'datetime':[datetime.now().strftime("%Y/%m/%d %H:%M:%S")],'tuningjob':[latest_tuning_job['HyperParameterTuningJobName']],'metric':[metric],'layer':prefix,'objective':[trainingobjective],'eval_metric':[latest_tuning_job['BestTrainingJob']['FinalHyperParameterTuningJobObjectiveMetric']['MetricName']],'eval_metric_value':latest_tuning_job['BestTrainingJob']['FinalHyperParameterTuningJobObjectiveMetric']['Value'],'trainingjobcount':[latest_tuning_job['HyperParameterTuningJobConfig']['ResourceLimits']['MaxNumberOfTrainingJobs']]})],axis=0)print(updatetuningjobhistory)# Write locallyupdatetuningjobhistory.to_csv(f"""{base_dir}logs/tuningjobhistory.csv""",index=False)# Upload to s3s3.upload_file(f"""{base_dir}logs/tuningjobhistory.csv""",bucket,'logs/tuningjobhistory.csv')3. 1 つの対話型 Python ノートブックで複数のモデルをモデルレジストリに登録する
組織では、異なるユースケースのために複数の AWS アカウントを持っている場合があります(つまり、sandbox、QA、および本番)。CI/CD ソリューションの各ステップでどのアカウントを使用するかを決定し、このガイドで注記されたクロスアカウントの許可を追加する必要があります。
推奨される方法は、モデルトレーニングとモデル登録を同じアカウント、具体的には sandbox またはテストアカウントで行うことです。したがって、以下の表では「データサイエンス」と「共有サービス」アカウントは同じものとします。このアカウント内には、モデルアーティファクトを収容し、パイプラインに関連する他のファイルのラインナップを追跡するための s3 バケットが必要です。モデル/エンドポイントは、トレーニング/登録アカウント内で別々に展開されます(つまり、sandbox、QA、本番)、モデルアーティファクトとトレーニング/登録アカウント内のレジストリを参照します。
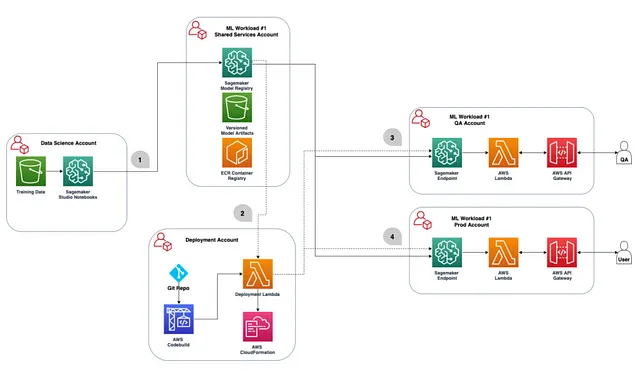
トレーニングに使用する AWS アカウントとモデルレジストリをハウスするアカウントを決定したので、最初のモデルを構築し、CI/CD ソリューションを開発できるようになりました。
SageMaker Pipelines を使用する場合、データ前処理、トレーニング/チューニング、評価、登録、および任意の後処理のために別々のパイプラインステップが作成されます。単一のモデルパイプラインには問題ありませんが、機械学習ソリューションに複数のモデルが必要な場合、パイプラインコードの重複が大幅に増加してしまいます。
そのため、推奨される解決策は、SageMaker Studio で 3 つの対話型 Python ノートブックを構築してスケジュールすることです。これらは順番に実行され、ノートブックジョブで自動化された場合、CI/CD パイプラインを実現するために一緒に実行されます。
A. データの準備
B. モデルの学習、評価、登録
C. 最新の承認済みモデルでのエンドポイントの更新
A. データの準備
ここでは、データウェアハウスからデータをクエリしてローカルおよびs3に書き込みます。現在の日付を使用して動的な日付/時刻条件を設定し、その結果の日付の床と天井をSQLクエリに渡すことができます。
# データウェアハウスに接続dbname='<ここに挿入>'host='<ここに挿入>'password='<ここに挿入>'port='<ここに挿入>'search_path='<ここに挿入>'user='<ここに挿入>'import psycopg2data_warehouse= psycopg2.connect(f"""host={host} port={port} dbname={dbname} user={user} password={password} options = '-c search_path={search_path}'""")# データセットの日付の床と天井を設定してクエリを適用するdatestart=date(2000, 1, 1)pushbackdays=30dateend=date.today() - timedelta(days=pushbackdays)print(datestart)print(dateend)# データウェアハウスからクエリを実行するmodelbuildingset=pd.read_sql_query(f"""<クエリを挿入>""",data_warehouse)# .csvファイルに書き込むmodelbuildingset.to_csv(f"{base_dir}datasets/{filename}", index=False)modelbuildingset# Lineage Trackingのためにs3にアップロードするs3 = boto3.client('s3')s3.upload_file(f"{base_dir}datasets/{filename}",bucket,f"datasets/{filename}")このステップでは、トレーニングのために準備したデータを、ローカルに保存すると同時に、Lineage Trackingのためにs3に保存します。
B. モデルの学習、評価、登録
Studio内のインタラクティブなPythonノートブックを使用することで、モデルの学習、評価、登録をすべて1つのノートブックで完了することができます。これらのすべてのステップを関数に組み込むことができ、再トレーニングが必要な追加のモデルに適用することができます。説明用に、関数を使用せずにコードが提供されています。
続行する前に、ソリューションの一部である各モデルに対して、レジストリ(コンソールまたはPythonを使用して)でモデルパッケージグループを作成する必要があります。
# 最高のトレーニングジョブを取得するbest_overall_training_job_name = latest_tuning_job['BestTrainingJob']['TrainingJobName']# hyperparameter tuningセクションからlatest_tuning_jobを取得しましたlatest_tuning_job['BestTrainingJob']# XGBoostをインストールする! pip install xgboost# ベストモデルをダウンロードするs3 = boto3.client('s3')s3.download_file('<s3 bucket>', f"""output/{best_overall_training_job_name}/output/model.tar.gz""", f"""{base_dir}models/{metric}/model.tar.gz""")# ダウンロードしたモデルアーティファクトを開いて読み込むtar = tarfile.open(f"""{base_dir}models/{metric}/model.tar.gz""")tar.extractall(f"""{base_dir}models/{metric}""")tar.close()model = pkl.load(open(f"""{base_dir}models/{layer}/{metric}/xgboost-model""", 'rb'))# モデルの評価を実行するimport jsonimport pathlibimport joblibfrom sklearn.metrics import mean_squared_errorfrom sklearn.metrics import mean_absolute_errorimport mathevaluationset=pd.read_csv(f"""{base_dir}datasets/{layer}/{metric}/{metric}modelbuilding_test.csv""")evaluationset['prediction']=model.predict(xgboost.DMatrix(evaluationset.drop(evaluationset.columns.values[0], axis=1), label=evaluationset[[evaluationset.columns.values[0]]]))# 例では回帰問題が使用され、評価指標としてMAEおよびRMSEが使用されますmae = mean_absolute_error(evaluationset[evaluationset.columns.values[0]], evaluationset['prediction'])rmse = math.sqrt(mean_squared_error(evaluationset[evaluationset.columns.values[0]], evaluationset['prediction']))stdev_error = np.std(evaluationset[evaluationset.columns.values[0]] - evaluationset['prediction'])evaluation_report=pd.DataFrame({'datetime':[datetime.now().strftime("%Y/%m/%d %H:%M:%S")], 'testing':[testing], 'trainingjob': [best_overall_training_job_name], 'objective':[trainingobjective], 'hyperparameter_tuning_metric':[objective_metric_name], 'mae':[mae], 'rmse':[rmse], 'stdev_error':[stdev_error]})# 過去の評価レポートを読み込むtry: past_evaluation_reports=pd.read_csv(f"""{base_dir}models/{metric}/evaluationhistory.csv""")except: past_evaluation_reports=pd.DataFrame({'datetime':[],'testing':[], 'trainingjob': [], 'objective':[], 'hyperparameter_tuning_metric':[], 'mae':[], 'rmse':[], 'stdev_error':[]})evaluation_report=pd.concat([past_evaluation_reports,evaluation_report],axis=0)print(evaluation_report)# .csvファイルに書き込むevaluation_report.to_csv(f"""{base_dir}models/{metric}/evaluationhistory.csv""",index=False)# s3に書き込むs3.upload_file(f"""{base_dir}models/{metric}/evaluationhistory.csv""",'<s3 bucket>',f"""{layer}/{metric}/evaluationhistory.csv""")# モデルを登録することもできますが、ここではスキップしますreport_dict = {}# モデルの登録model_package_group_name='<>'modelpackage_inference_specification = { "InferenceSpecification": { "Containers": [ { "Image": xgboost_container, "ModelDataUrl": f"""s3://{s3 bucket}/output/{best_overall_training_job_name}/output/model.tar.gz""" } ], "SupportedContentTypes": [ "text/csv" ], "SupportedResponseMIMETypes": [ "text/csv" ], } }create_model_package_input_dict = { "ModelPackageGroupName" : model_package_group_name, "ModelPackageDescription" : "<ここに説明を挿入>", "ModelApprovalStatus" : "PendingManualApproval", "ModelMetrics" :report_dict}create_model_package_input_dict.update(modelpackage_inference_specification)sm_client = boto3.client('sagemaker')create_model_package_response = sm_client.create_model_package(**create_model_package_input_dict)model_package_arn = create_model_package_response["ModelPackageArn"]print('ModelPackage Version ARN : {}'.format(model_package_arn))レジストリでモデルパッケージグループを開くと、登録されたすべてのモデルバージョン、登録日、承認ステータスを確認できます。
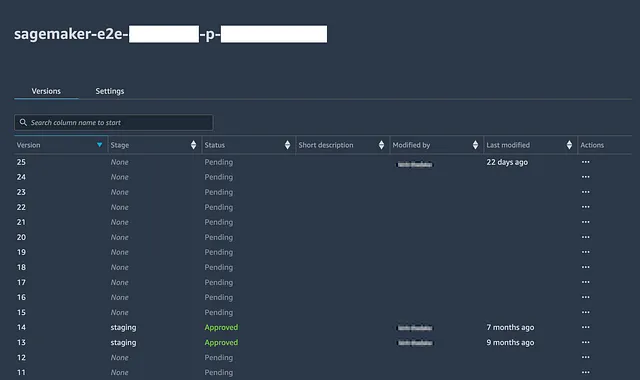
パイプラインの監督者は、前のステップでローカルに保存された評価レポートを確認して、過去のすべてのモデル評価の履歴を含む、テストセット評価メトリックに基づいてモデルを承認または拒否するかどうかを決定できます。その後、承認された場合は、最新のモデルでのみ本番(またはQA)エンドポイントを更新する基準を設定できます。
4. 新しいモデルでマルチモデルエンドポイントを更新する
SageMakerにはMultiDataModelクラスがあり、複数のモデルをホストできるSageMakerエンドポイントを展開できます。理由は、複数のモデルを同じコンピュートインスタンスに読み込み、リソースを共有し、コストを節約できるためです。さらに、モデルの再トレーニング/管理を単一のエンドポイントで行うことができるため、各専用エンドポイントでステップを複製する必要がなくなります(代替手段として行うことができます)。 MultiDataModelクラスは、将来的にソリューションに追加する予定がある場合には、単一のモデルを展開するためにも使用できます。
トレーニングアカウントで最初にモデルとエンドポイントを作成する必要があります。MultiDataModelクラスは、呼び出されるとエンドポイントにロードされるモデルアーティファクトを格納する場所が必要です。以下では使用中のs3バケットの’model’ディレクトリを使用します。
# コンテナの読み込みfrom sagemaker.xgboost.estimator import XGBoostxgboost_container = sagemaker.image_uris.retrieve("xgboost", region, "1.2-2")# 1回限り:Multi Modelをビルドするestimator = sagemaker.estimator.Estimator.attach('sagemaker-xgboost-220611-1453-011-699894eb')xgboost_container = sagemaker.image_uris.retrieve("xgboost", region, "1.2-2")model = estimator.create_model(role=role, image_uri=xgboost_container)from sagemaker.multidatamodel import MultiDataModelsagemaker_session=sagemaker.Session()# ここがMMEがS3上でモデルを読み込む場所です。model_data_prefix = f"s3://{bucket}/models/"mme = MultiDataModel( name=model_name, model_data_prefix=model_data_prefix, model=model, # モデルを通過するコンテナイメージを渡す sagemaker_session=sagemaker_session,)# 1回限り:MMEをデプロイするENDPOINT_INSTANCE_TYPE = "ml.m4.xlarge"ENDPOINT_NAME = "<ここに挿入>"predictor = mme.deploy( initial_instance_count=1, instance_type=ENDPOINT_INSTANCE_TYPE, endpoint_name=ENDPOINT_NAME,kms_key='<必要に応じてここに挿入>')その後、MultiDataModelは次のように参照できます。
model=sagemaker.model.Model(model_name)from sagemaker.multidatamodel import MultiDataModelsagemaker_session=sagemaker.Session()# ここがMMEがS3上でモデルを読み込む場所です。model_data_prefix = f"s3://{bucket}/models/"mme = MultiDataModel( name=model_name, model_data_prefix=model_data_prefix, model=model, # モデルを通過するコンテナイメージを渡す sagemaker_session=sagemaker_session,)モデルは、エンドポイントがモデルを読み込むために使用する{s3バケット}/modelsディレクトリにアーティファクトをコピーすることでMultiDataModelに追加できます。必要なのは、モデルパッケージグループ名と、モデルレジストリが対応するソースアーティファクトの場所と承認ステータスを提供することです。
以下に、承認された場合にのみ最新のモデルを追加する条件を示します。データサイエンスのQAのために即座に展開する必要がある場合や、最終的にモデルを承認する場合は、この条件を省略することができます。
# モデルパッケージグループに関連する最新のモデルバージョンとそのアーティファクトの場所を取得するModelPackageGroup = 'model_package_group'list_model_packages_response = client.list_model_packages(ModelPackageGroupName=f"arn:aws:sagemaker:{region}:{aws_account_id}:model-package-group/{ModelPackageGroup}")list_model_packages_responselatest_model_version_arn = list_model_packages_response["ModelPackageSummaryList"][0][ "ModelPackageArn"]print(latest_model_version_arn)modelpackage=client.describe_model_package(ModelPackageName=latest_model_version_arn)modelpackageartifact_path=modelpackage['InferenceSpecification']['Containers'][0]['ModelDataUrl']artifact_path# 承認された場合はモデルを追加if list_model_packages_response["ModelPackageSummaryList"][0]['ModelApprovalStatus']=="Approved": model_artifact_name='<model_name>.tar.gz' mme.add_model(model_data_source=artifact_path, model_data_path=model_artifact_name)以下の機能を使用して、追加されたモデルをリストアップできます。
list(mme.list_models())# 追加された2つのモデルがある場合の出力['modela.tar.gz','modelb.tar.gz']モデルを削除するには、関連するs3ディレクトリに移動して、削除してください。削除すると、利用可能なモデルのリストを再表示すると削除されていることが確認できます。
モデルを追加した後は、以下のコードを使用してデプロイされたエンドポイントで呼び出すことができます。
response = runtime_sagemaker_client.invoke_endpoint( EndpointName = "<endpoint_name>", ContentType = "text/csv", TargetModel = "<model_name>.tar.gz", Body = body)モデルを初めて呼び出すと、エンドポイントはターゲットモデルをロードするため、追加のレイテンシが発生します。モデルがすでにロードされている場合は、将来の呼び出しでは推論が直ちに取得されます。マルチモデルエンドポイント開発者ガイドによると、最近呼び出されていないモデルはメモリ使用量のしきい値に達すると「アンロード」され、次回の呼び出し時に再度ロードされるとのことです。
4. 新しいモデルでマルチモデルエンドポイントを更新する
mme.add_model()またはs3コンソールで既存のモデルアーティファクトが上書きされると、デプロイされたエンドポイントにはすぐに反映されません。最新のモデルアーティファクトを次回の呼び出し時にエンドポイントに再度ロードするには、エンドポイントを任意の新しいエンドポイント構成で更新することができます。これにより、モデルをロードする必要がある新しいエンドポイントが作成され、古いエンドポイントと新しいエンドポイントの間の移行が安全に管理されます。各エンドポイント構成には一意の名前が必要なため、日付スタンプのサフィックスを追加できます。
# エンドポイント構成のためのdatetimeの取得time=str(datetime.now())[0:10]+'--'+str(datetime.now())[11:13]+'-'+'00'time# 新しいエンドポイント構成を作成し、新しいデプロイメントに対応するように既存エンドポイントを更新するendpoint_config_name=f"""<endpoint name>-{time}"""create_endpoint_config_api_response = client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[ { 'VariantName': model_name, 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': instance_type }, ] )# 新しい構成でエンドポイントを更新response = client.update_endpoint( EndpointName=endpoint_name, EndpointConfigName=f"""{model_name}-{time}""")responseこのコードを実行すると、関連するエンドポイントがコンソールで表示されると「更新中」のステータスになります。この更新期間中、以前のエンドポイントは引き続き使用でき、新しいエンドポイントが準備でき次第、新しいエンドポイントで置き換えられ、ステータスが「インサービス」に調整されます。追加された新しいモデルは、次回の呼び出し時にロードされます。
CI/CDソリューションに必要な3つのノートブック(データ準備、トレーニング/評価、エンドポイント更新)を構築しました。ただし、これらのファイルは現在、トレーニングAWSアカウントにのみあります。第3のノートブックを、リスペクティブなエンドポイントが作成/更新される任意のデプロイメントAWSアカウントで動作するように適応する必要があります。
AWSアカウントIDに基づいた条件付きロジックを追加することで、これを行うことができます。新しいAWSアカウントにはモデルアーティファクトを保持するためのs3バケットも必要です。s3バケット名はAWS全体で一意である必要があるため、このような条件付きロジックを使用できます。エンドポイントインスタンスタイプの調整や、新しいモデルの追加条件(承認ステータスなど)に対する条件付きロジックも適用できます。
# AWSアカウントIDの取得aws_account_id = boto3.client("sts").get_caller_identity()["Account"]aws_account_id# アカウントごとにバケットとインスタンスタイプを設定するif aws_account_id=='<insert AWS Account_ID 1>': bucket='<insert s3 bucket name 1>' instance_type='ml.t2.medium'elif aws_account_id=='<insert AWS Account_ID 2>': bucket='<insert s3 bucket name 2>' instance_type='ml.t2.medium'elif aws_account_id=='<insert AWS Account_ID 3>': bucket='<insert s3 bucket name 3>' instance_type='ml.m5.large'training_account_bucket='<insert training account bucket name>'bucket_path = 'https://s3-{}.amazonaws.com/{}'.format(region,bucket)最初にMultiDataModelを作成してデプロイする手順を、各新しいデプロイメントアカウントで繰り返す必要があります。
今や AWS アカウント ID を参照し、異なる AWS アカウントで実行できる 1 つの動作するノートブックがあるので、このノートブック(およびラインナップ追跡のためにおそらく他の 2 つ)を含む Git リポジトリを設定し、これらのアカウントの SageMaker Studio ドメインでリポジトリをクローンする必要があります。幸いなことに、Studio/Git 統合により、これらの手順は簡単でシームレスで、次のドキュメントで説明されています。私の経験に基づいて、SageMaker Studio の外部にリポジトリを作成し、各 AWS アカウントドメイン内でクローンすることをお勧めします。
ノートブックに対する将来の変更は、トレーニングアカウントで行ってリポジトリにプッシュすることができます。それらは変更を引き込むことによって他の展開アカウントに反映されることができます。.gitignore ファイルを作成して、ログやその他のファイルではなく 3 つのノートブックだけが考慮されるようにすることを確認してください。ラインナップはここでは s3 で追跡されます。さらに、ノートブックが実行されるたびにコンソール出力が変わることに注意する必要があります。他の展開アカウントでファイルの変更をプルするときに競合を避けるために、これらのアカウントで最後のプル以降にファイルが変更された場合は、最新の更新をプルする前に復元する必要があります。
5. 一定のリズムで再トレーニング/再展開ノートブックをスケジュールする
最後に、3 つのノートブックをトレーニングアカウントで同時に実行するようにスケジュールを設定できます。これを行うには、新しい SageMaker Studio ノートブックジョブ機能を使用できます。スケジュールは環境/アカウントに依存する必要があります。つまり、展開アカウントでは、最新のモデルでエンドポイントを更新するために別個のノートブックジョブを作成することができます。新しく承認されたモデルが自動的にサンドボックス、QA、および本番アカウントで展開されるまでのラグタイムを提供します。美しいのは、リリースされたソリューションの唯一の手動部分がレジストリでのモデルの承認/否認になることです。そして、新しく展開されたモデルが何か問題があった場合、レジストリで拒否された後、前の本番モデルバージョンに戻すためにエンドポイント更新ノートブックを手動で実行することができ、さらなる調査の時間を稼ぐことができます。この場合、パイプラインを一定の時間間隔(月次/四半期)で実行するように設定しましたが、このソリューションは条件(データドリフトまたは生産モデルの精度の低下など)に基づいて適応できます。
終わりに
CI/CD は現在、機械学習オペレーション領域で注目されている話題です。これは、初期展開後に機械学習ソリューションの継続性について多くの考えが行われないことが多いためです。生産機械学習ソリューションが共変量のドリフトに堅牢であり、時間をかけて持続可能であることを確認するには、シンプルで柔軟な CI/CD ソリューションが必要です。幸いにも、AWS は SageMaker エコシステム内で多数の新機能をリリースしており、このようなソリューションを実現することができます。この記事では、単一の手動モデル検証ステップのみが必要な、幅広いタイプの ML ソリューションに対してこれを成功裏に達成するためのパスを示しています。
読んでいただきありがとうございます!この記事が役に立った場合は、私をフォローして新しい投稿を通知してください。また、コメント/提案をお寄せいただくのも自由です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- CapPaに会ってください:DeepMindの画像キャプション戦略は、ビジョンプレトレーニングを革新し、スケーラビリティと学習性能でCLIPに匹敵しています
- 最初のLLMアプリを構築するために知っておく必要があるすべて
- 再帰型ニューラルネットワークの基礎からの説明と視覚化
- AIは自己を食べるのか?このAI論文では、モデルの崩壊と呼ばれる現象が紹介されており、モデルが時間の経過とともに起こり得ないイベントを忘れ始める退行的な学習プロセスを指します
- より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
- 50以上の最新の最先端AIツール(2023年7月)
- Google Cloudを使用してレコメンドシステムを構築する






