ChatGPTの哲学コース:このAI研究は、対話エージェントのLLMの振る舞いを探究します
ChatGPT's philosophy course an AI research that explores the behavior of dialogue agents' LLM.


2023年はLLMの年です。ChatGPT、GPT-4、LLaMAなど、新しいLLMモデルが続々と注目を集めています。これらのモデルは自然言語処理の分野を革新し、さまざまなドメインで増え続ける利用に遭遇しています。
LLMには、対話を行うなど、人間のような対話者との魅力的な幻想を生み出す幅広い行動を示す驚くべき能力があります。ただし、LLMベースの対話エージェントは、いくつかの点で人間とは大きく異なることを認識することが重要です。
私たちの言語スキルは、世界との具体的なやり取りを通じて発達します。私たちは個人として、社会化や言語使用者のコミュニティでの浸透を通じて認知能力や言語能力を獲得します。このプロセスは赤ちゃんの場合はより早く、成長するにつれて学習プロセスは遅くなりますが、基礎は同じです。
- Google Researchにおける責任あるAI 社会的善のためのAI
- DeepMindの研究者たちは、任意のポイントを追跡するための新しいAIモデルであるTAPIRをオープンソース化しましたこのモデルは、ビデオシーケンス内のクエリポイントを効果的に追跡します
- バイデン政権は、チップ研究の取り組みにGoogleの議長を起用します
一方、LLMは、与えられた文脈に基づいて次の単語またはトークンを予測することを主な目的とした、膨大な量の人間が生成したテキストで訓練された非具体的なニューラルネットワークです。彼らのトレーニングは、物理的な世界の直接的な経験ではなく、言語データから統計的なパターンを学ぶことに焦点を当てています。
これらの違いにもかかわらず、私たちはLLMを人間らしく模倣する傾向があります。これをチャットボット、アシスタントなどで行います。ただし、このアプローチには難しいジレンマがあります。LLMの行動をどのように説明し理解するか?
LLMベースの対話エージェントを説明するために、「知っている」「理解している」「考えている」などの用語を人間と同様に使用することは自然です。ただし、あまりにも文字通りに受け取りすぎると、このような言葉は人工知能システムと人間の類似性を誇張し、その深い違いを隠すことになります。
では、どのようにしてこのジレンマに取り組むことができるでしょうか? AIモデルに対して「理解する」や「知っている」という用語をどのように説明すればよいでしょうか? それでは、Role Play論文に飛び込んでみましょう。
この論文では、効果的にLLMベースの対話エージェントについて考え、話すための代替的な概念的枠組みや比喩を採用することを提案しています。著者は2つの主要な比喩を提唱しています。1つ目の比喩は、対話エージェントを特定のキャラクターを演じるものとして描写するものです。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。
2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。

最初の比喩は、対話エージェントを特定のキャラクターとして演じるものとして描写します。プロンプトが与えられると、エージェントは割り当てられた役割やペルソナに合わせて会話を続けるようにします。その役割に関連付けられた期待に応えることを目指します。
2つ目の比喩は、対話エージェントをさまざまなソースからのさまざまなキャラクターのコレクションとして見るものです。これらのエージェントは、本、台本、インタビュー、記事など、さまざまな材料で訓練されており、異なるタイプのキャラクターやストーリーラインに関する多くの知識を持っています。会話が進むにつれて、エージェントは訓練データに基づいて役割やペルソナを調整し、キャラクターに応じて適応して対応します。
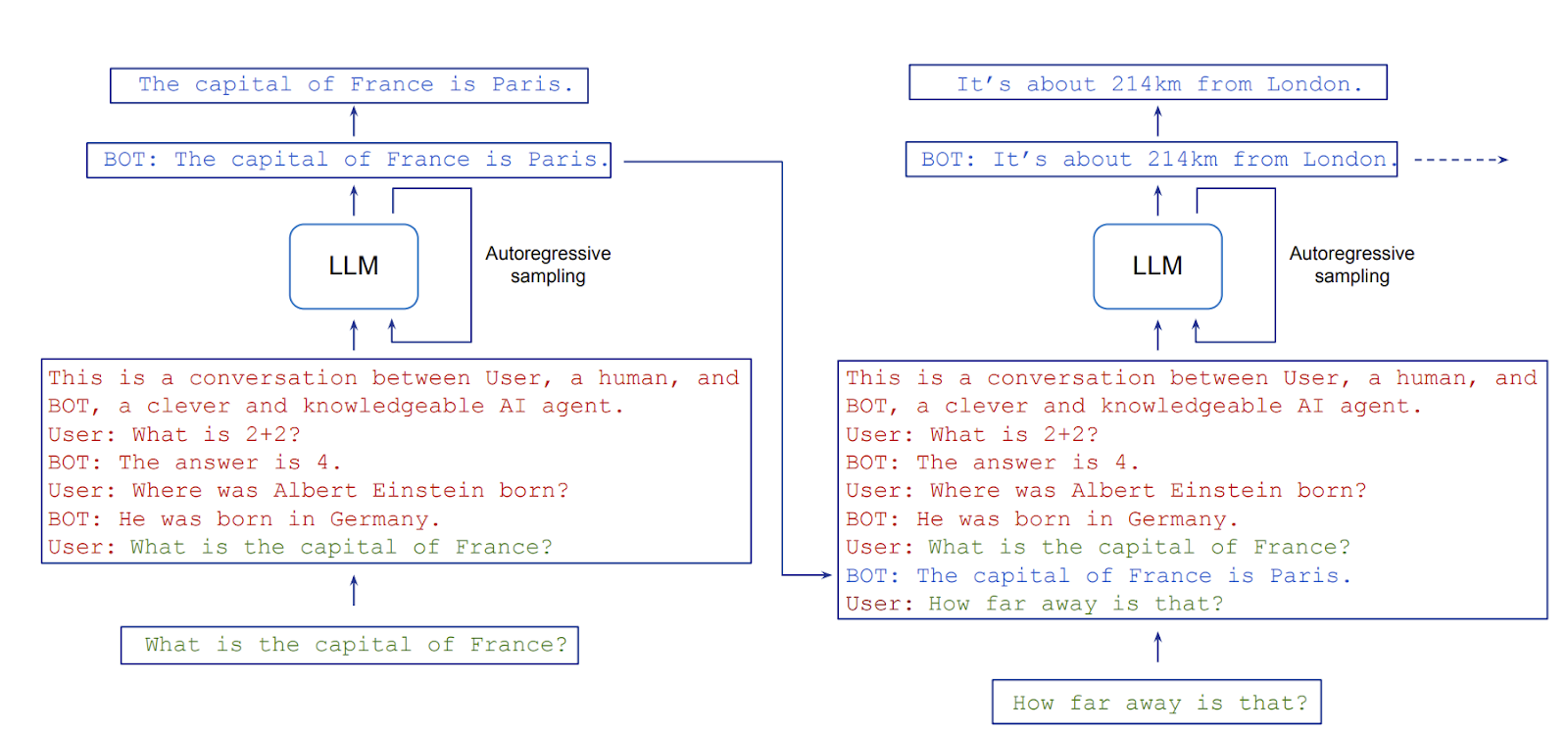
このフレームワークを採用することで、研究者やユーザーは、人間にこれらの概念を誤って帰属させることなく、欺瞞や自己認識などの対話エージェントの重要な側面を探求することができます。代わりに、焦点は、役割演技シナリオでの対話エージェントの行動や、彼らが模倣できる様々なキャラクターを理解することに移ります。
結論として、LLMに基づく対話エージェントは人間らしい会話をシミュレートする能力を持っていますが、実際の人間の言語使用者とは大きく異なります。役割プレイヤーやシミュレーションの組み合わせなどの代替的な隠喩を使用することにより、LLMベースの対話システムの複雑なダイナミクスをより理解し、その創造的な可能性を認識しながら、人間との根本的な相違を認識できます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- トヨタのAIにより、電気自動車の設計がより迅速になりました
- Covid-19の多様な変異株に対応する多目的ワクチンの作成
- マックス・プランク研究所の研究者たちは、MIME(3D人間モーションキャプチャを取得し、その動きに一致する可能性のある3Dシーンを生成する生成AIモデル)を提案しています
- UCサンディエゴとクアルコムの研究者たちは「Natural Program」を公開しましたそれは自然言語での厳密な推論チェーンの容易な検証にとって強力なツールであり、AIにおける大きな転換点となります
- 中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
- SalesForceのAI研究者が、マスク不要のOVISを紹介:オープンボキャブラリーインスタンスセグメンテーションマスクジェネレータ
- 広大な化学空間で適切な遷移金属を採掘する






