「目と耳を持つChatGPT:BuboGPTは、マルチモーダルLLMsにおいて視覚的なグラウンディングを可能にするAIアプローチです」
ChatGPT BuboGPT is an AI approach that enables visual grounding in multimodal LLMs.


大規模言語モデル(LLM)は、自然言語処理の領域でゲームチェンジャーとして登場しました。彼らは私たちの日常生活の重要な一部になりつつあります。最も有名なLLMの例はChatGPTであり、この時点でほとんどの人がそれについて知っており、ほとんどの人が日常的に使用していると安全に言えます。
LLMはその巨大なサイズと膨大なテキストデータからの学習能力によって特徴付けられます。これにより、彼らは一貫した文脈に即した人間らしいテキストを生成することができます。これらのモデルは、GPT(Generative Pre-trained Transformer)やBERT(Bidirectional Encoder Representations from Transformers)などの深層学習アーキテクチャに基づいて構築されており、言語の長距離依存関係を捉えるために注意メカニズムを使用しています。
大規模なデータセットでの事前トレーニングと特定のタスクでの微調整を活用することで、LLMはテキスト生成、感情分析、機械翻訳、質問応答など、さまざまな言語関連のタスクで優れたパフォーマンスを発揮しています。LLMが改良を続けるにつれて、機械と人間のような言語処理の間のギャップを埋め、自然言語の理解と生成を革新するという莫大なポテンシャルを秘めています。
一方、一部の人々は、LLMがテキスト入力に限定されているため、その全ての潜在能力を活用していないと考えていました。彼らはLLMの潜在能力を言語以外の領域に広げる取り組みを行ってきました。いくつかの研究では、画像、動画、音声、オーディオなどのさまざまな入力信号をLLMと統合し、強力なマルチモーダルチャットボットを構築することに成功しています。
しかし、ここにはまだ長い道のりがあります。これらのモデルのほとんどは、視覚オブジェクトと他のモダリティの関係を理解していません。視覚的に強化されたLLMは高品質な説明を生成することができますが、視覚的な文脈に明示的に関連付けることなく、ブラックボックス的な方法で行います。
マルチモーダルLLMにおいてテキストと他のモダリティの間に明示的かつ有益な対応関係を確立することで、ユーザーエクスペリエンスを向上させ、これらのモデルに新たな応用を可能にすることができます。そこで、私たちはBuboGPTに会いましょう。これはこの制約に取り組むものです。
BuboGPTは、視覚オブジェクトを他のモダリティに接続することでLLMに視覚的な基礎付けを取り入れる最初の試みです。BuboGPTは、事前トレーニングされたLLMとよく一致する共有表現空間を学習することにより、テキスト、ビジョン、オーディオのための共同マルチモーダル理解とチャットを実現します。
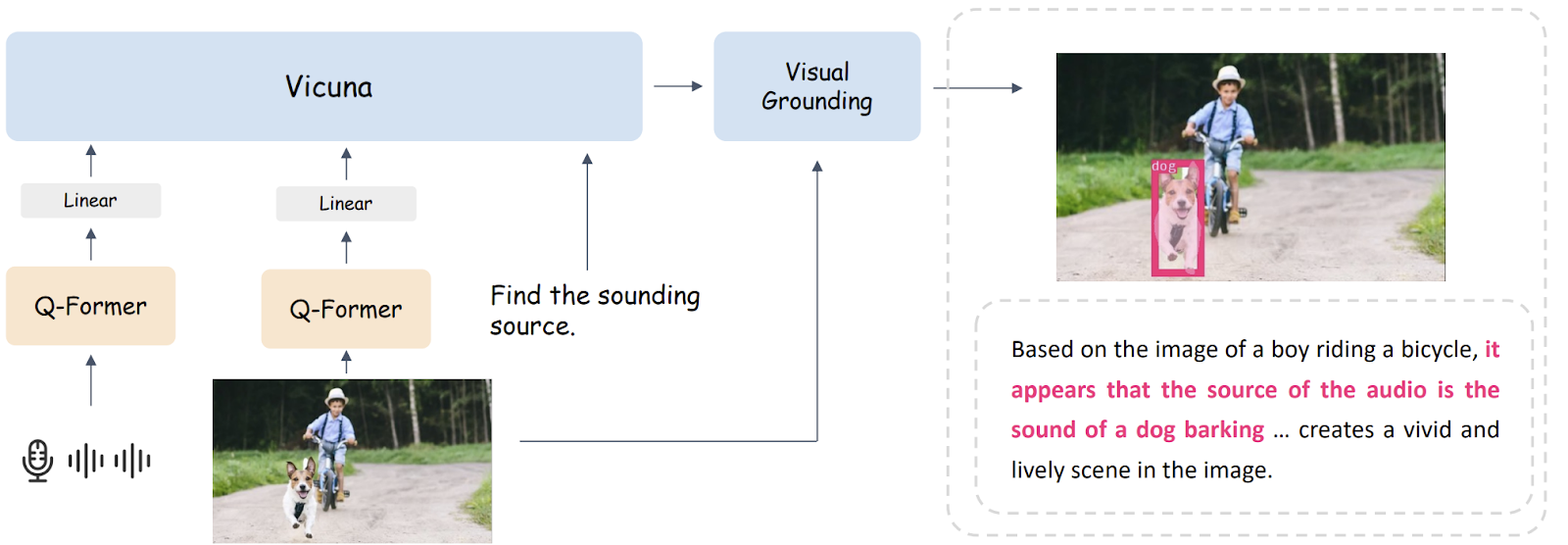
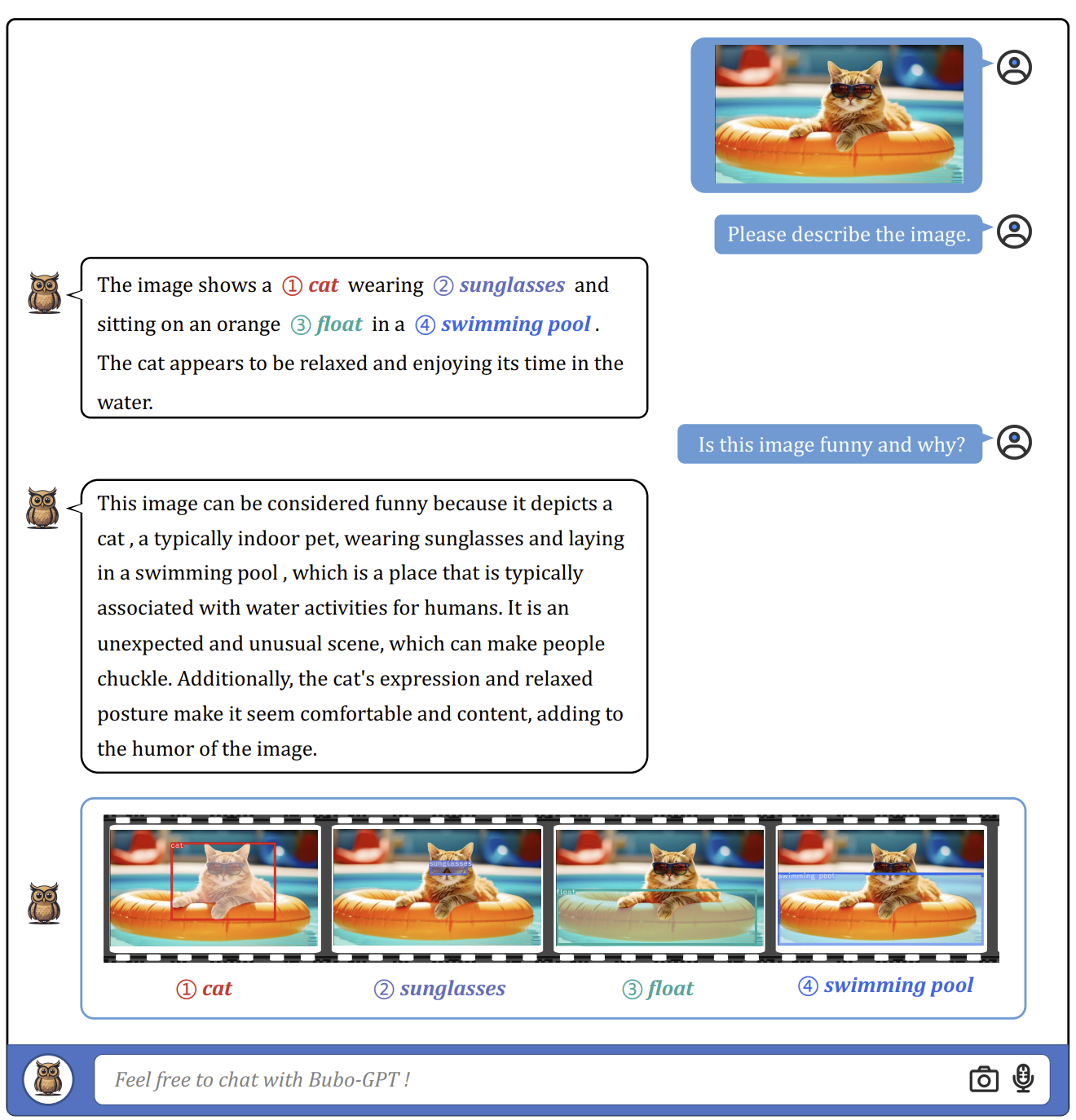
視覚的な基礎付けは容易な課題ではないため、それがBuboGPTのパイプラインの重要な部分を担っています。このメカニズムは、視覚オブジェクトとモダリティとの間の細かい関係を確立します。
パイプラインには、タギングモジュール、グラウンディングモジュール、エンティティマッチングモジュールの3つのモジュールが含まれています。タギングモジュールは、入力画像の関連するテキストタグ/ラベルを生成し、グラウンディングモジュールは各タグに対して意味的なマスクまたはボックスをローカライズし、エンティティマッチングモジュールはタグと画像の説明から一致するエンティティをLLMの推論に使用します。視覚オブジェクトと他のモダリティを言語を介して接続することで、BuboGPTはマルチモーダル入力の理解を向上させます。
任意の入力の複数モーダル理解を可能にするために、BuboGPTはMini-GPT4に似た2段階のトレーニングスキームを採用しています。最初の段階では、音声エンコーダとしてImageBind、視覚エンコーダとしてBLIP-2、および言語とビジョンまたは音声の特徴を整列させるQ-formerを学習するためのLLMとしてVicunaを使用します。2番目の段階では、高品質な指示に従うデータセットでマルチモーダルな指示の調整を行います。
このデータセットの構築は、LLMが提供されたモダリティを認識し、入力が適切にマッチしているかどうかを認識するために重要です。したがって、BuboGPTは、ビジョン指示、音声指示、正の画像・音声ペアを使用した音の位置づけ、および意味推論のための負のペアを使用した画像・音声キャプショニングのためのサブセットを持つ、新しい高品質なデータセットを構築しています。負の画像・音声ペアを導入することで、BuboGPTはより良いマルチモーダルな整合性を学び、より強力な共同理解能力を示すことができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






