ChatGPT コードインタプリター 数分でデータサイエンスを実行する
ChatGPTコードインタプリターでデータサイエンスを数分で実行

データサイエンティストとして、データを使って効率を最大化し、ビジネス価値を向上させる方法を常に探しています。
だから、ChatGPTが最新の強力な機能の一つであるコードインタプリタープラグインをリリースしたときには、私はそれを試してワークフローに組み込むことを決めました。
ChatGPTコードインタプリターとは何ですか?
もしまだCode Interpreterについて聞いたことがないなら、これはChatGPTのインタフェース内でコードをアップロードし、プログラムを実行し、データを分析する新機能です。
過去1年間、コードのデバッグやドキュメントの分析をするたびに、私は自分の作業をコピーしてChatGPTに貼り付けて応答を得る必要がありました。
これは時間のかかる作業であり、ChatGPTのインタフェースには文字数制限があり、データの分析や機械学習のワークフローの実行能力が制限されました。
コードインタプリターは、これらすべての問題を解決するために、ChatGPTインタフェースに独自のデータセットをアップロードできるようにすることで対処しています。
そして、「コードインタプリター」と呼ばれていますが、この機能はプログラマーに限定されるものではありません。テキストファイルの分析、PDFドキュメントの要約、データの可視化、および希望の比率に従って画像をトリミングするのにもこのプラグインは役立ちます。
コードインタプリターにアクセスする方法は?
アプリケーションに入る前に、Code Interpreterプラグインの使用方法について簡単に説明します。
このプラグインにアクセスするには、現在月額$20のChatGPT Plusの有料サブスクリプションが必要です。
残念ながら、Code InterpreterはChatGPT Plusに登録していないユーザーには利用できません。
有料サブスクリプションを取得したら、ChatGPTに移動し、インタフェースの左下にある三点リーダーをクリックします。
次に、設定を選択します:
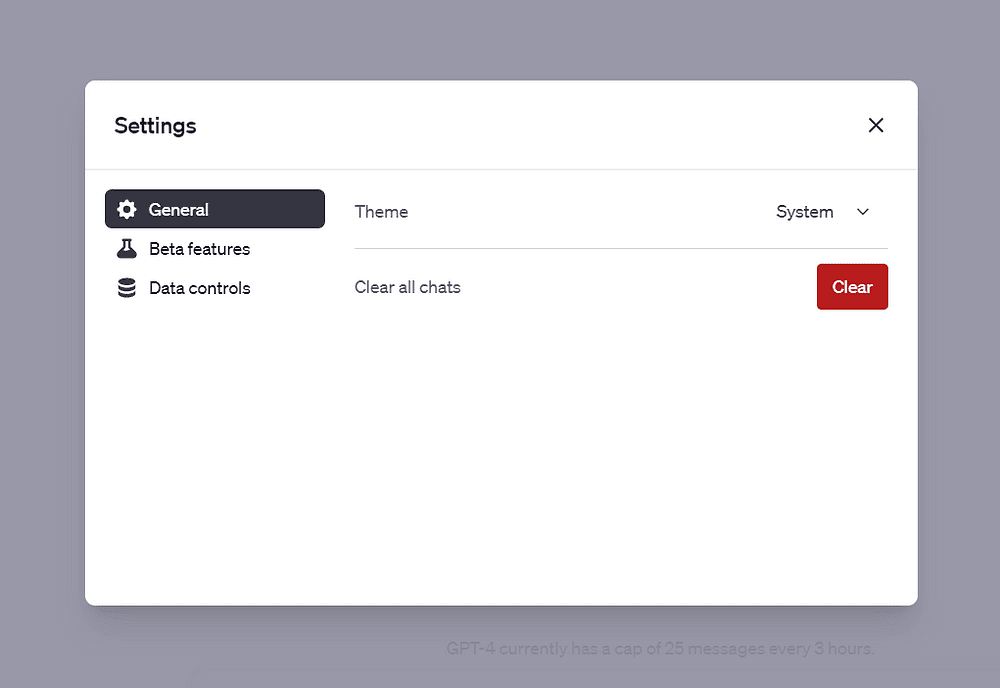
「ベータ機能」をクリックし、Code Interpreterと書かれたスライダーを有効にします:
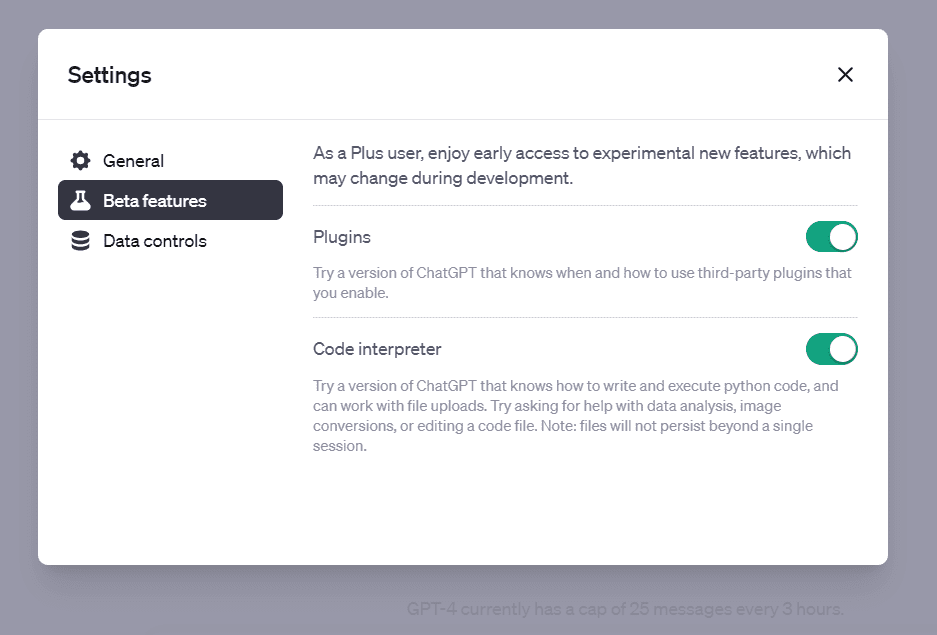
最後に、「新しいチャット」をクリックし、「GPT-4」オプションを選択し、表示されるドロップダウンから「コードインタプリター」を選択します:
テキストボックスの近くに「+」のシンボルが表示される画面が表示されます:

素晴らしい!これでChatGPTコードインタプリターを正常に有効にしました。
この記事では、Code Interpreterを使用してデータサイエンスのワークフローを自動化する5つの方法を紹介します。
1. データの要約
データサイエンティストとして、データセットに含まれる異なる変数を理解しようとするためにたくさんの時間を費やしています。
Code Interpreterは、各データポイントを分解するのに非常に役立ちます。
以下は、モデルにデータの要約を手伝ってもらう方法です:
この例では、KaggleのTitanic Survival Predictionデータセットを使用します。私は「train.csv」ファイルを使用します。
データセットをダウンロードし、Code Interpreterに移動します:
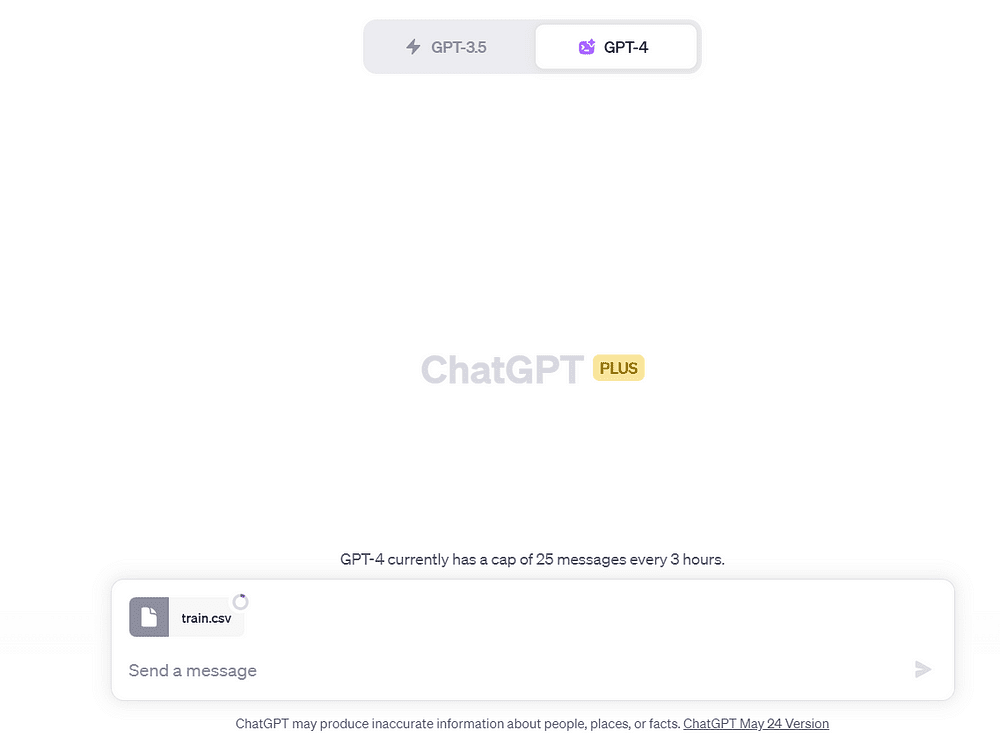
「+」のシンボルをクリックして、要約したいファイルをアップロードします。
そして、ChatGPTにこのファイルのすべての変数を簡単な言葉で説明するように依頼します:
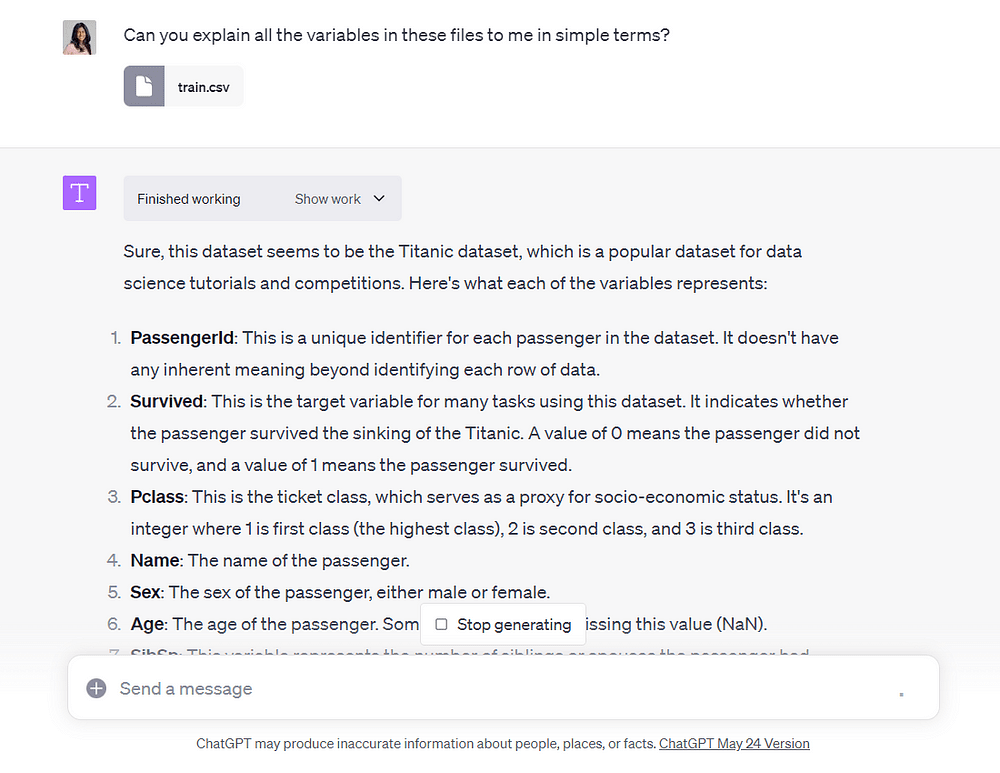
ボイラ!
Code Interpreterは、データセット内の各変数の簡単な説明を提供してくれました。
2. 探索的データ分析
データセットの異なる変数についての理解が得られたので、Code Interpreterに一歩進んでEDAを実行してもらいましょう。
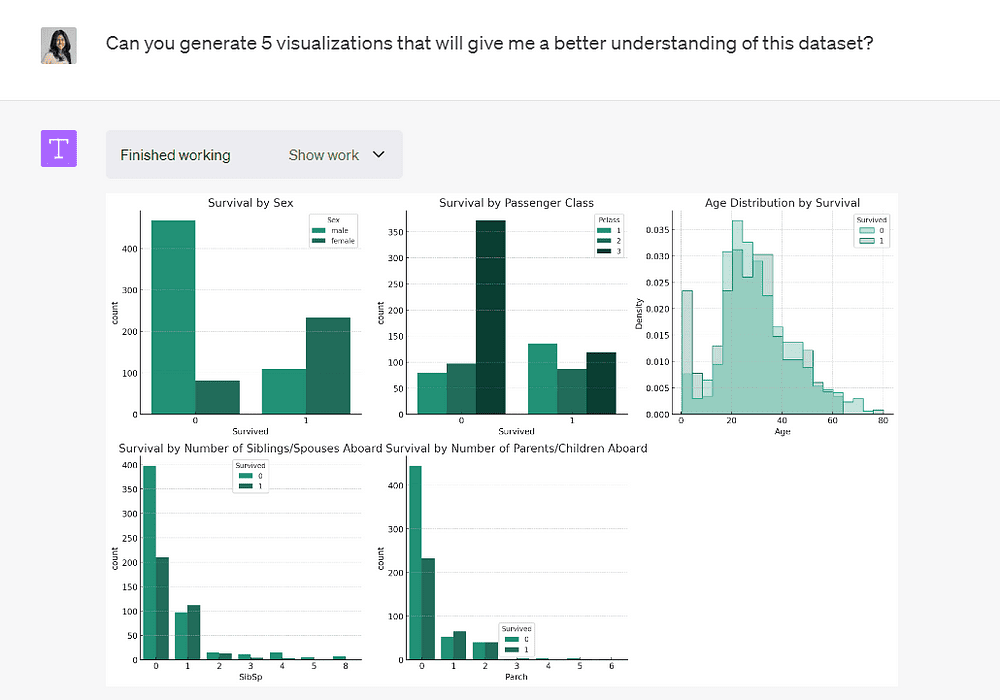
このモデルは、このデータセットの異なる変数をより理解するための5つのプロットを生成しました。
「作業を表示」のドロップダウンをクリックすると、Code Interpreterが最終結果を達成するためにPythonコードを書き、実行したことがわかります。
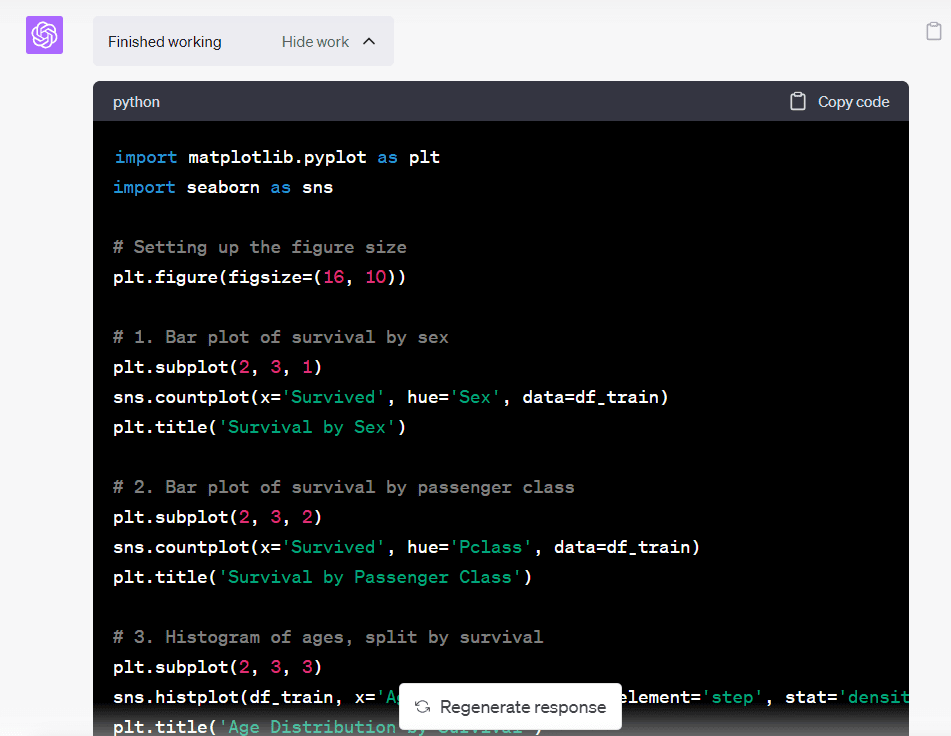 Image by Author
Image by Author
さらなる分析を行いたい場合は、いつでもこのコードを自分のJupyter Notebookにコピー&ペーストすることができます。
ChatGPTは、生成された視覚化に基づいてデータセットに関する洞察も提供してくれました:
 Image by Author
Image by Author
女性、一等席の乗客、および若い乗客の生存率が高かったことを示しています。
これらは手作業で導き出すのに時間がかかる洞察であり、特にPythonやMatplotlibなどのデータ可視化ライブラリに詳しくない場合は時間がかかります。
Code Interpreterはたった数秒でこれらを生成し、EDAの実行にかかる時間を大幅に削減しました。
3. データの前処理
私はデータセットのクリーニングとモデリングプロセスの準備に多くの時間を費やしています。
このデータセットの前処理を手伝ってもらうために、Code Interpreterにお願いしましょう:
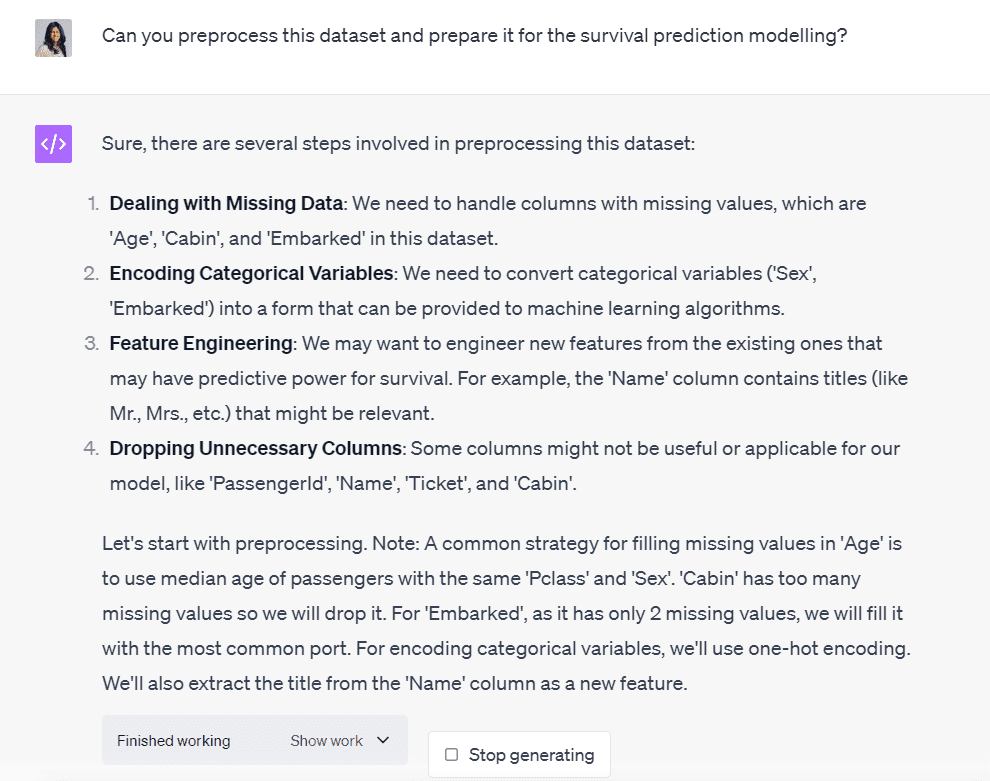 Image by Author
Image by Author
Code Interpreterは、このデータセットのクリーニングプロセスに関与するすべてのステップを示しています。
欠損値を持つ3つの列を処理し、2つのカテゴリ変数をエンコードし、特徴エンジニアリングを行い、モデリングプロセスに関連しない列を削除する必要があると教えてくれました。
その後、数秒で前処理を行うPythonプログラムを作成しました。
データクリーニングの手順を理解したい場合は、「作業を表示」をクリックすることができます:
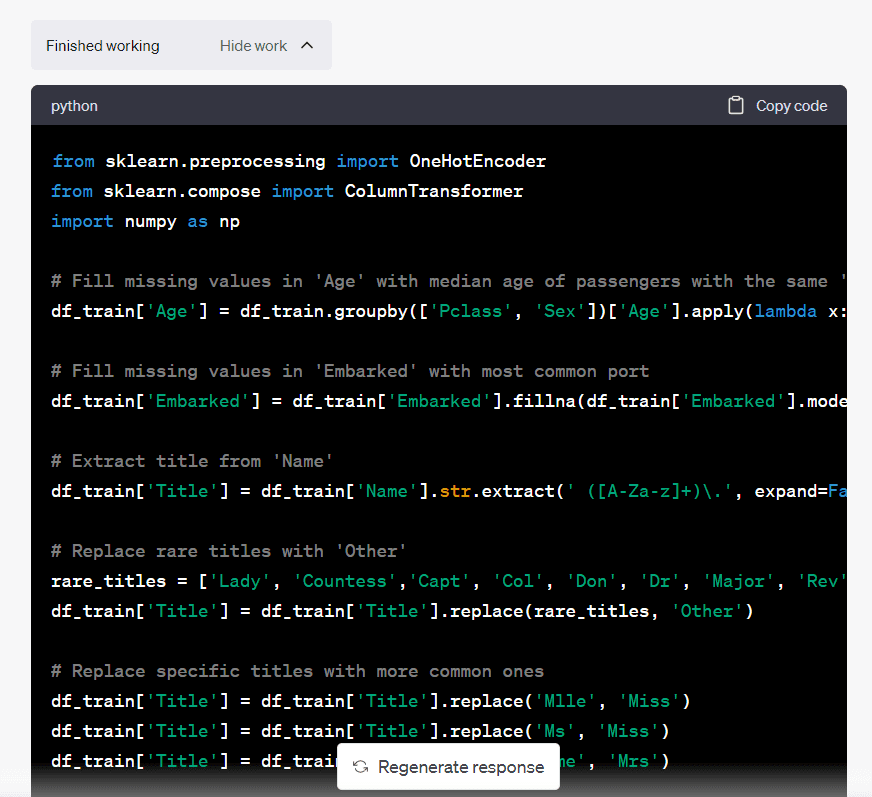 Image by Author
Image by Author
その後、出力ファイルを保存する方法をChatGPTに尋ねたところ、ダウンロード可能なCSVファイルが提供されました:
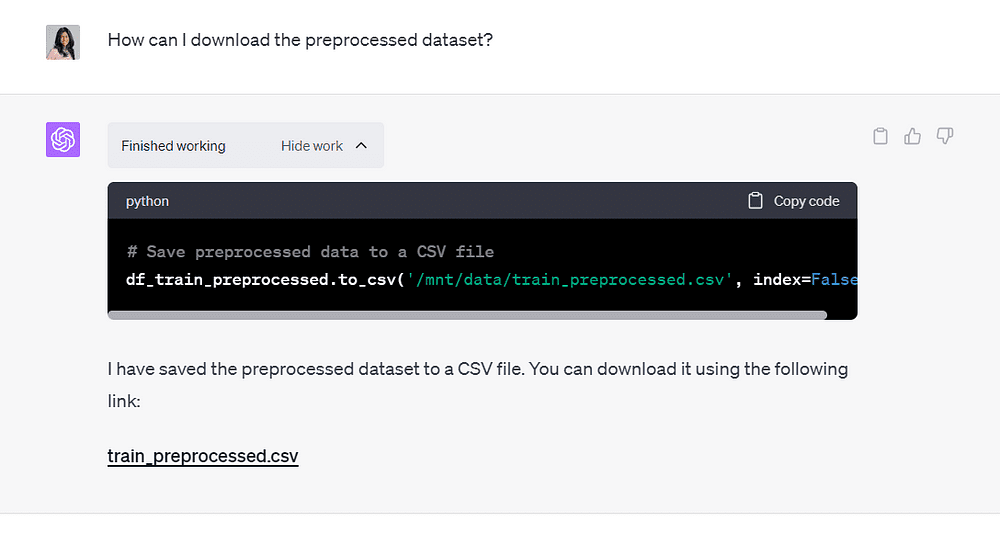 Image by Author
Image by Author
このプロセス全体で1行のコードも実行する必要がなかったことに注意してください。
Code Interpreterは、私のファイルを取り込み、インターフェース内でコードを実行し、短時間で出力を提供することができました。
4. 機械学習モデルの構築
最後に、前処理されたファイルを使用して、Titanicの難破事故での生存を予測するための機械学習モデルを作成するようにCode Interpreterにお願いしました:
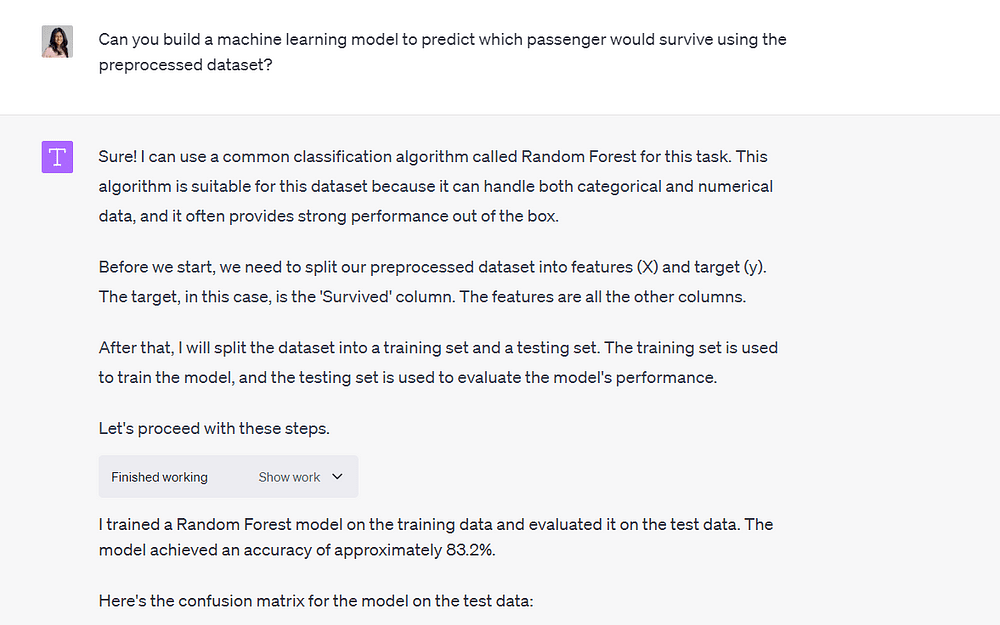 Image by Author
Image by Author
モデルは1分以内に構築され、精度は83.2%に達しました。
また、モデルのパフォーマンスを要約した混同行列と分類レポート、およびすべての指標の説明も提供してくれました:
 Image by Author
Image by Author
モデルの予測と乗客データをマッピングする出力ファイルをChatGPTに提供するようにお願いしました。
また、将来の微調整やトレーニングのために、作成された機械学習モデルのダウンロード可能なファイルも欲しいと思いました:
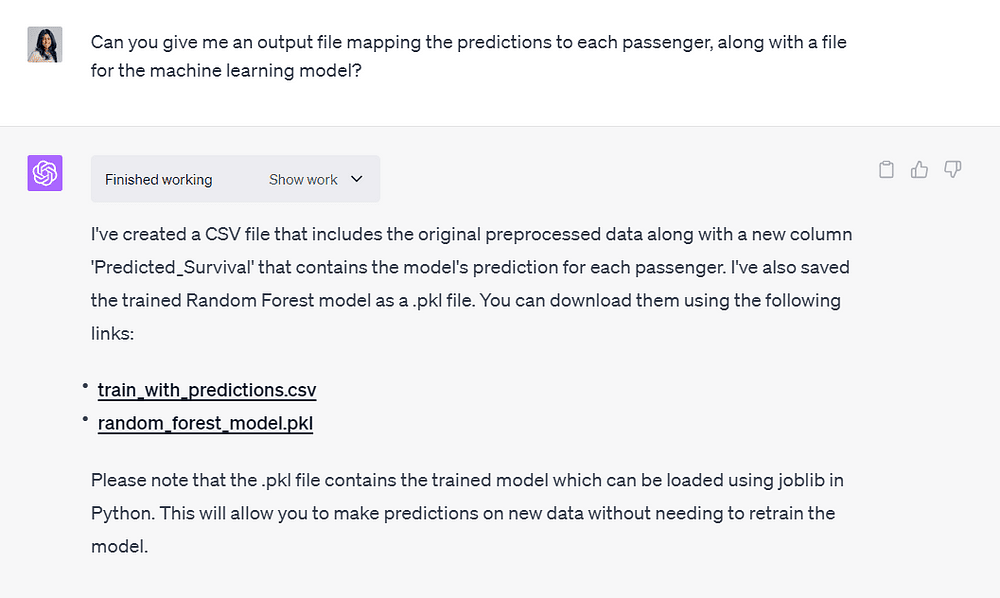 作者による画像
作者による画像
5. コードの説明
Code Interpreterのもう一つの応用例は、コードの説明を作成する能力です。
先日、感情分析モデルに取り組んでいて、GitHubで自分のユースケースに関連するコードを見つけました。
著者が私が馴染みのないライブラリをインポートしていたため、コード全体を理解することができませんでした。
Code Interpreterを使用すれば、コードファイルを簡単にアップロードして、各行を明確に説明するように依頼できます。
また、コードのデバッグやパフォーマンスの最適化を依頼することもできます。
以下は例です – 私は数年前に作成したPythonダッシュボードを構築するためのコードを含むファイルをアップロードしました:
 作者による画像
作者による画像
Code Interpreterは私のコードを分解し、各セクションで行われたことを明確に説明しました。
 作者による画像
作者による画像
また、コードの可読性を向上させるためにコードのリファクタリングを提案し、新しいセクションを含める場所を説明しました。
これを自分で行う代わりに、私は単にCode Interpreterにコードのリファクタリングと改善版を提供するように依頼しました:
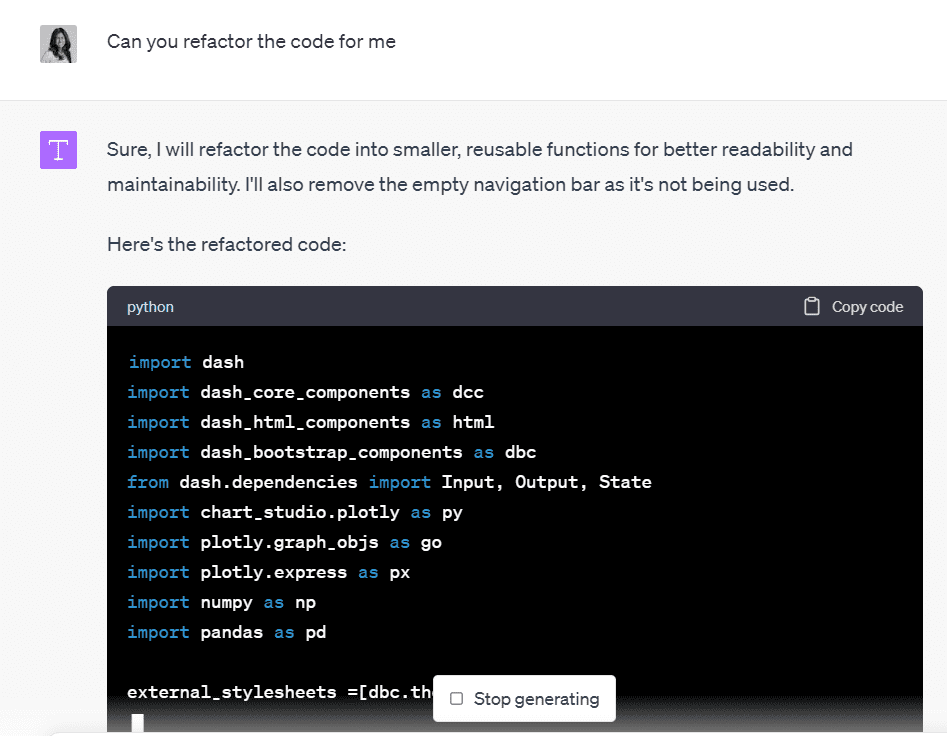 作者による画像
作者による画像
Code Interpreterは私のコードを書き直して、各可視化を別々の関数にカプセル化し、理解と更新が容易になるようにしました。
ChatGPTのコードインタープリターはデータサイエンティストにとって何を意味するのでしょうか?
現在、Code Interpreterについては非常に話題になっています。これは、コードを取り込み、自然言語を理解し、エンドツーエンドのデータサイエンスワークフローを実行できるツールを初めて目の当たりにしているからです。
ただし、これはデータサイエンスを効率的に行うための別のツールに過ぎないことを念頭に置くことが重要です。
今のところ、敏感な企業情報をChatGPTインターフェースにアップロードすることは許可されていませんので、ダミーデータを使用してベースラインモデルを構築するために使用しています。
さらに、Code Interpreterにはドメイン固有の知識がありません。通常、生成された予測をベースラインの予測として使用します – 生成された出力を組織のユースケースに合わせるために調整する必要がしばしばあります。
企業の内部構造を把握していないアルゴリズムによって生成された数値を提示することはできません。
最後に、私はすべてのプロジェクトでCode Interpreterを使用しているわけではありません。私が扱うデータの一部は数百万行であり、SQLデータベースに格納されています。
これは、クエリの実行、データの抽出、変換の大部分を自分で行う必要があることを意味します。
エントリーレベルのデータサイエンティストであるか、そのようなデータサイエンティストを目指している場合、Code Interpreterなどのツールを活用して、仕事の単調な部分を効率的に行う方法を学ぶことをお勧めします。
この記事は以上です。お読みいただきありがとうございます! Natassha Selvaraj は自己学習のデータサイエンティストであり、執筆に情熱を持っています。LinkedInで彼女とつながることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
