ChatGPTのTokenizerを解放する
ChatGPTのTokenizerを解放する
ハンズオン!ChatGPTがトークンを管理する方法

ChatGPTの背後にある主要なコンポーネントは気になったことはありますか?
私たちは皆同じことを言われているはずです:ChatGPTは次の単語を予測する。しかし実際には、この表明には少し嘘があります。ChatGPTは次のトークンを予測するのです。
トークン?はい、トークンは大規模言語モデル(LLM)のテキスト単位です。
実際には、ChatGPTがプロンプトを処理する際に行う最初のステップの一つは、ユーザーの入力をトークンに分割することです。そして、それがいわゆるトークナイザーの役割です。
この記事では、OpenAIが使用するオリジナルのライブラリであるtiktokenライブラリを使って、ChatGPTのトークナイザーがどのように機能するかを解明します。
TikTok…面白いですね 🙂
さあ、トークナイザーによって実際に実行される手順と、その振る舞いがChatGPTの出力の品質にどのように影響するかを深く探求しましょう。
トークナイザーの動作
記事「ChatGPTのマスタリング:LLMを用いた効果的な要約」では、ChatGPTのトークナイザーの一部の謎をすでに見ましたが、最初から説明しましょう。
トークナイザーは、テキスト生成のプロセスの最初のステップで登場します。ChatGPTに入力するテキストの一部を個々の要素であるトークンに分割する責任を持っており、これらのトークンはその後、言語モデルによって処理されて新しいテキストを生成するために使用されます。
トークナイザーがテキストをトークンに分割する際には、対象言語の意味のある単位を識別するために設計された一連のルールに基づいて行います。
たとえば、与えられた文に現れる単語が非常に一般的な単語である場合、各トークンが1つの単語に対応する可能性が高いです。しかし、「Prompting as powerful developer tool」という文のように、使用される単語があまり一般的でないプロンプトを使用する場合、1対1のマッピングは得られないかもしれません。この場合、「prompting」はまだ英語であまり一般的ではないため、実際には次の3つのトークンに分割されます。「’prom」、「pt」、および「ing」、なぜならこれらの3つはよく出現する文字のシーケンスだからです。
別の例を見てみましょう!
次の文を考えてみてください。「I want to eat a peanut butter sandwich」。トークナイザーがスペースと句読点に基づいてトークンを分割するように設定されている場合、この文は以下のトークンに分割され、単語数は8、トークン数も8になります。
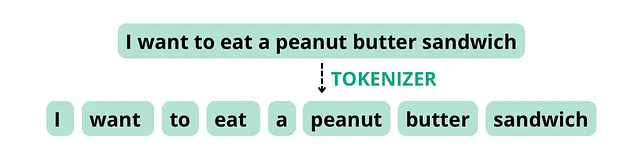
しかし、「peanut butter」を1つの単語として扱うようなトークナイザーは、その構成要素が頻繁に一緒に現れることから、この文を以下のトークンに分割するかもしれません。単語数は8のままで、トークン数は7になります。
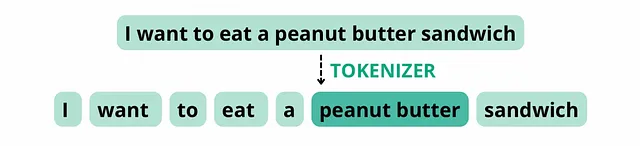
ChatGPTとトークンの管理の文脈において、「エンコーディング」と「デコーディング」という用語は、テキストをモデルが理解できるトークンに変換するプロセス(エンコーディング)と、モデルの補完を人が読めるテキストに変換するプロセス(デコーディング)を指します。
Tiktokenライブラリ
ChatGPTのトークナイザーの理論を理解することは必要ですが、この記事ではハンズオンの実践にも焦点を当てたいと思います。
ChatGPTの実装では、トークンの管理にtiktokenライブラリを使用しています。他のPythonライブラリと同様に、次のように使用することができます:
pip install --upgrade tiktokenインストールが完了したら、ChatGPTが使用するエンコーディングモデルを簡単に取得することができます。なぜなら、encoding_for_model()メソッドが存在するからです。このメソッドは、与えられたモデル名に対して正しいエンコーディングを自動的にロードします。
指定されたモデルに対して初めて実行される場合、エンコーディングモデルをダウンロードするためにインターネット接続が必要です。以降の実行では、エンコーディングが事前にキャッシュされているため、インターネット接続は不要です。
一般的に使用されるgpt-3.5-turboモデルに対しては、次のように単純に実行することができます:
import tiktokenencoding = tiktoken.encoding_for_model("gpt-3.5-turbo")出力のencodingは、実際にChatGPTがプロンプトをどのように認識しているかを可視化するために使用できるトークナイザーオブジェクトです。
より具体的には、tiktoken.encoding_for_model関数は、gpt-3.5-turboモデルに特化したトークナイゼーションパイプラインを初期化します。このパイプラインはテキストのトークナイズとエンコーディングを処理し、モデルが使用できる形式に整形します。
考慮する重要な側面の1つは、トークンが数値の表現であるということです。例えば、「Prompting as powerful developer tool」の例では、単語”prompting”に関連するトークンは”’prom”、”pt”、”ing”ですが、モデルが実際に受け取るのはこれらのシーケンスの数値表現です。
心配しないでください!実際の動作については、ハンズオンセクションで見ていきます。
エンコーディングの種類
tiktokenライブラリは複数のエンコーディングタイプをサポートしています。実際に、異なるgptモデルは異なるエンコーディングを使用しています。以下は最も一般的なものを含む表です:

エンコーディング — ハンズオン!
さあ、次に進んで最初のプロンプトをエンコードしてみましょう。プロンプトとして「tiktoken is great!」とすでにロードされたencodingを与えると、メソッドencoding.encodeを使用してプロンプトをトークンに分割し、その数値表現を可視化することができます:
prompt = "tiktoken is great!"encoded_prompt = encoding.encode(prompt)print(encoded_prompt)# 出力: [83, 1609, 5963, 374, 2294, 0]はい、その通りです。出力の[83, 1609, 5963, 374, 2294, 0]はあまり意味がなさそうですが、実際には一目で推測できる要素があります。
わかりましたか?
長さです!プロンプト「tiktoken is great!」が6つのトークンに分割されていることがすぐにわかります。この場合、ChatGPTはこのサンプルプロンプトを空白文字ではなく、最も頻度の高い文字列で分割しています。
この例では、出力リストの各座標は、トークン化されたシーケンス内の特定のトークンであるトークンIDに対応しています。トークンIDは、モデルが使用するボキャブラリーに基づいて各トークンを一意に識別するための整数です。IDは通常、ボキャブラリー内の単語やサブワードユニットにマッピングされます。
では、座標のリストをデコードして元のプロンプトに一致するか確認してみましょう:
encoding.decode(encoded_prompt)# 出力: 'tiktoken is great!'.decode()メソッドは、トークンの整数リストを文字列に変換します。単一のトークンに.decode()メソッドを適用できますが、utf-8の境界にないトークンに対しては情報の損失が生じる可能性があることに注意してください。
そして、個々のトークンを見る方法はあるのでしょうか?
やってみましょう!
単一のトークンに対しては、.decode_single_token_bytes()メソッドを使用して単一の整数トークンを安全にバイトに変換できます。サンプルプロンプトの場合は:
[encoding.decode_single_token_bytes(token) for token in encoded_prompt]# 出力: [b't', b'ik', b'token', b' is', b' great', b'!']文字列の前にある b は、文字列がバイト文字列であることを示しています。英語の場合、1つのトークンは平均して約4文字または約3/4の単語に対応します。
テキストがどのようにトークンに分割されるかを知ることは役立ちます。なぜなら、GPTモデルはテキストをトークンの形式で見るからです。テキスト文字列に含まれるトークンの数を知ることは、テキストモデルが処理するには長すぎるかどうかや、OpenAI APIの呼び出しにかかるトークン数に応じた利用料金など、有用な情報を提供することができます。
エンコーディングモデルの比較
先ほど見たように、異なるモデルは異なるエンコーディング方式を使用します。時には、モデル間でトークンの管理方法に大きな違いがあることもあります。
異なるエンコーディングは、単語の分割方法、スペースのグループ化方法、非英語文字の処理方法などに違いがあります。上記の方法を使用して、いくつかの例の文字列に対して、いくつかのgptモデルでの異なるエンコーディングを比較することができます。
以下の関数を使用して、上記のテーブルのエンコーディング(gpt2、p50k_base、cl100k_base)を比較してみましょう。この関数には、これまで見てきたさまざまなエンコーディングの情報、トークンの数、トークンの整数、およびトークンのバイトなどが含まれています。
いくつかの例を試してみましょう!

この最初の例では、gpt2 モデルと p50k_base モデルは、数学記号を空白と結合してエンコーディングすることで一致していますが、cl100k_base のエンコーディングではそれらを別々の要素として扱っています。
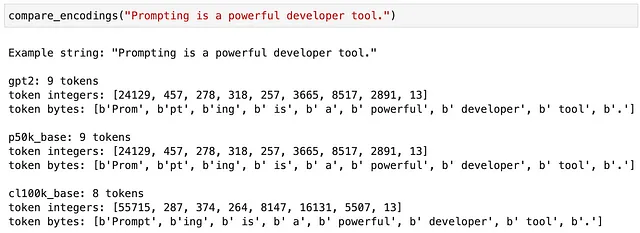
この例では、単語 “Prompting” のトークン化方法も選択したエンコーディングに依存します。
トークナイザの制限

入力プロンプトのトークン化方法は、時にはChatGPTの完了エラーの原因となることがあります。たとえば、「lollipop」という単語を逆順で書くようChatGPTに要求すると、間違った結果が返ってきます。
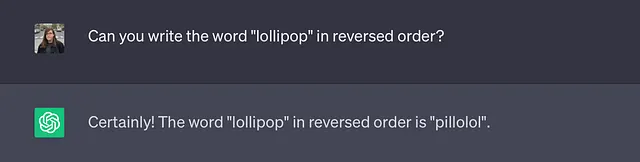
ここで起こっていることは、トークナイザが与えられた単語を3つのトークンに分割していることです。「l」、「oll」、「ipop」という3つのトークンを見てしまうため、ChatGPTは個々の文字を見ていないため、これらの3つのトークンを逆順で正しく出力することがより困難になります。
制限を認識することで、回避策を見つけることができるかもしれません。この場合、各文字の間にダッシュを追加することで、トークナイザにテキストをそれらの記号で分割させることができます。入力プロンプトをわずかに変更することで、より良い結果を得ることができます:

ダッシュを使用することで、モデルは個々の文字をより見やすくし、逆の順番で表示できます。だから、それを念頭に置いてください:もしChatGPTを使ってWordやScrabbleのようなワードゲームをプレイしたり、それらの原則を基にアプリケーションを構築したりする場合は、この便利なトリックを使うと、モデルは単語の個々の文字をより良く見ることができます。
ChatGPTのトークナイザーが非常に単純なタスクでモデルの失敗を引き起こす例です。 他にも似たようなケースはありましたか?
概要
この記事では、ChatGPTがユーザープロンプトを見て処理し、学習時に大量の言語データから学んだ統計的なパターンに基づいて完了出力を生成する方法を探求しました。
tiktokenライブラリを使用することで、ChatGPTに入力する前にどのプロンプトでも評価できるようになりました。これにより、ChatGPTのエラーをデバッグすることができます。少しプロンプトを変更することで、ChatGPTがタスクをより良く完了するようになることがあります。
さらに、重要なメッセージもあります:将来的には技術的な負債になることもあるいくつかの設計上の決定があります。シンプルなロリポップの例で見たように、モデルは驚異的なタスクに成功していますが、簡単な演習は完了できません。その理由は、モデルの能力ではなく、最初のトークナイズのステップにあります!
以上です!読んでいただき、ありがとうございました!
この記事がChatGPTアプリケーションの構築に役立つことを願っています!
新しいコンテンツについては、ニュースレターを購読することもできます。特に、ChatGPTに関する記事に興味がある場合は:
ChatGPTのマスタリング:LLMsを使った効果的な要約
高品質な要約を得るためのChatGPTのプロンプト方法
towardsdatascience.com
OpenAIによるプロンプトエンジニアリングコース:推論、変換、ChatGPTでの拡張
カスタムアプリケーションでChatGPTの潜在能力を最大限に活用する
VoAGI.com
ChatGPTの新たな次元を開く:テキストから音声への統合
ChatGPTとのインタラクションのユーザーエクスペリエンスの向上
towardsdatascience.com
質問があればお気軽にお問い合わせください:[email protected] 🙂
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






