ChatGPTにおけるCSVファイルのクエリパフォーマンス向上
ChatGPTのCSVファイルのクエリパフォーマンス向上
LangChainのカスタマイズされたCSVローダーを使用したセルフクエリングによる
ChatGPTなどの高度な言語モデルの登場により、表形式データのクエリングに対する新しい有望なアプローチがもたらされました。しかし、トークンの制限により、APIのようなリトリーバーの支援なしでクエリを直接実行することは困難になります。そのため、クエリの精度はクエリの品質に大きく依存し、必要な情報を正確に返すためには標準のリトリーバーが不足することも珍しくありません。
この記事では、従来のリトリーバーメソッドが特定のユースケースで失敗する原因について詳しく説明します。さらに、メタデータ情報を組み込んだカスタマイズされたCSVデータローダーの革新的な解決策を提案します。LangChainのセルフクエリングAPIと新しいCSVデータローダーを活用することで、性能と精度が大幅に向上した情報を抽出することができます。
この記事で使用された詳細なコードについては、こちらのノートブックをご覧ください。なお、このノートブックは、「LLMを使用して大規模な表形式データをクエリすることで傑出した精度を実現できる可能性」を示しています。
疾患人口データセットの検索
以下の作者によって作成された合成SIRデータセットをクエリしたいと思います。このデータセットでは、簡単なSIRモデルに基づいて、10の都市で90日間の疾患中の3つの異なる人口グループをシミュレーションしています。単純化のために、各都市の人口は5,000から20,000の範囲であり、都市間での人口移動はないものとします。また、元の感染者数として500から2000の間の10個のランダムな整数を生成します。
- 「AWSを基にしたカスケーディングデータパイプラインの構築方法」
- 「Pythonのタイピングに関するデータサイエンティストのガイド:コードの明瞭さを向上させるための手引き」
- 「データサイエンスプロジェクトを変革する:YAMLファイルに変数を保存する利点を見つけよう」
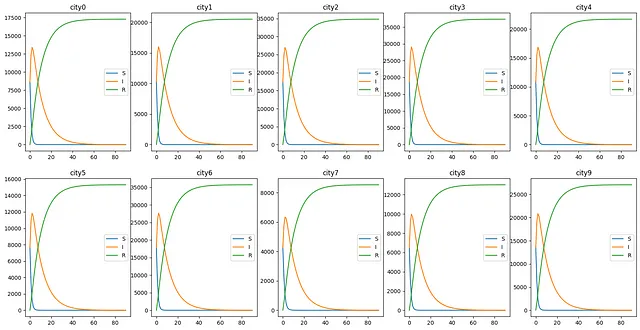
この表形式データには、次のような形式で5つの列があります。「time」は人口が測定された時間を示し、「city」はデータが測定された都市、「susceptible」、「infectious」、「removed」は人口の3つのグループを表します。単純化のため、データはCSVファイルとしてローカルに保存されています。
time susceptible infectious removed city0 2018-01-01 8639 8639 0 city01 2018-01-02 3857 12338 1081 city02 2018-01-03 1458 13414 2405 city03 2018-01-04 545 12983 3749 city04 2018-01-05 214 12046 5017 city0このデータセットに関連するChatGPTの質問をしたいと思います。ChatGPTがこのような表形式データと対話するために、LangChainを使用して以下の標準的な手順に従います:
- CSVLoaderを使用してデータをロードする
- ベクトルストア(ここではChromaを使用)を作成してOpenAIの埋め込みデータを保存する
- リトリーバーを使用して、与えられた非構造化クエリに関連するドキュメントを返す
以下のコードを使用して上記の手順を実現できます。
# ローカルパスからデータをロード
loader = CSVLoader(file_path=LOCAL_PATH)
data = loader.load()
# 埋め込みを作成
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(data, embeddings)
# リトリーバーを作成
retriever = vectorstore.as_retriever(search_kwargs={"k": 20})これでConversationalRetriverChainを定義してSIRデータセットをクエリすることができます。
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
# システムメッセージテンプレートを定義
system_template = """提供された{context}は、10の都市で90日間にわたるSusceptible、Infectious、Removedの人口を含む表形式データセットです。データセットには次の列が含まれています:「time」:人口が測定された時間、「city」:人口が測定された都市、「susceptible」:疾患の感受性人口、「infectious」:疾患の感染人口、「removed」:疾患の除去人口。----------------{context}"""
# チャットプロンプトテンプレートを作成
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template("{question}")
]
qa_prompt = ChatPromptTemplate.from_messages(messages)
# メモリを作成
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# ConversationalRetrievalChainを作成
qa = ConversationalRetrievalChain.from_llm(llm=llm, retriever=vectorstore.as_retriever(), return_source_documents=False, combine_docs_chain_kwargs={"prompt": qa_prompt}, memory=memory, verbose=True)上記のコードでは、前のステップで定義した検索モデルを使用して、SIRデータセット内のクエリの関連情報を検索し、検索した情報に基づいて回答を返す会話チェーンを定義しています。ChatGPTにより明確な指示を与えるために、データセット内のすべての列の定義を説明するプロンプトも追加しました。
さて、簡単な質問をしてみましょう。「2018年2月3日に最も感染者の多い都市はどこですか?」
驚くべきことに、私たちのチャットボットは「提供されたデータセットには2018年2月3日のデータが含まれていません。」と答えました。
それはどうして可能なのでしょうか?
なぜ検索に失敗したのか?
提供されたデータセットの中に答えがあるにもかかわらず、チャットボットが「2018年2月3日に最も感染者の多い都市はどこですか?」という質問に答えることができなかった原因を調査するために、質問に関連するドキュメントを確認しました。以下の行を取得しました:
[Document(page_content=': 31\ntime: 2018-02-01\nsusceptible: 0\ninfectious: 1729\nremoved: 35608\ncity: city3', metadata={'source': 'sir.csv', 'row': 301}), Document(page_content=': 1\ntime: 2018-01-02\nsusceptible: 3109\ninfectious: 9118\nremoved: 804\ncity: city8', metadata={'source': 'sir.csv', 'row': 721}), Document(page_content=': 15\ntime: 2018-01-16\nsusceptible: 1\ninfectious: 2035\nremoved: 6507\ncity: city7', metadata={'source': 'sir.csv', 'row': 645}), Document(page_content=': 1\ntime: 2018-01-02\nsusceptible: 3481\ninfectious: 10873\nremoved: 954\ncity: city5', metadata={'source': 'sir.csv', 'row': 451}), Document(page_content=': 23\ntime: 2018-01-24\nsusceptible: 0\ninfectious: 2828\nremoved: 24231\ncity: city9', metadata={'source': 'sir.csv', 'row': 833}), Document(page_content=': 1\ntime: 2018-01-02\nsusceptible: 8081\ninfectious: 25424\nremoved: 2231\ncity: city6', metadata={'source': 'sir.csv', 'row': 541}), Document(page_content=': 3\ntime: 2018-01-04\nsusceptible: 511\ninfectious: 9733\nremoved: 2787\ncity: city8', metadata={'source': 'sir.csv', 'row': 723}), Document(page_content=': 24\ntime: 2018-01-25\nsusceptible: 0\ninfectious: 3510\nremoved: 33826\ncity: city3', metadata={'source': 'sir.csv', 'row': 294}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 1413\nremoved: 35924\ncity: city3', metadata={'source': 'sir.csv', 'row': 303}), Document(page_content=': 25\ntime: 2018-01-26\nsusceptible: 0\ninfectious: 3173\nremoved: 34164\ncity: city3', metadata={'source': 'sir.csv', 'row': 295}), Document(page_content=': 1\ntime: 2018-01-02\nsusceptible: 3857\ninfectious: 12338\nremoved: 1081\ncity: city0', metadata={'source': 'sir.csv', 'row': 1}), Document(page_content=': 23\ntime: 2018-01-24\nsusceptible: 0\ninfectious: 1365\nremoved: 11666\ncity: city8', metadata={'source': 'sir.csv', 'row': 743}), Document(page_content=': 16\ntime: 2018-01-17\nsusceptible: 0\ninfectious: 2770\nremoved: 10260\ncity: city8', metadata={'source': 'sir.csv', 'row': 736}), Document(page_content=': 3\ntime: 2018-01-04\nsusceptible: 487\ninfectious: 6280\nremoved: 1775\ncity: city7', metadata={'source': 'sir.csv', 'row': 633}), Document(page_content=': 14\ntime: 2018-01-15\nsusceptible: 0\ninfectious: 3391\nremoved: 9639\ncity: city8', metadata={'source': 'sir.csv', 'row': 734}), Document(page_content=': 20\ntime: 2018-01-21\nsusceptible: 0\ninfectious: 1849\nremoved: 11182\ncity: city8', metadata={'source': 'sir.csv', 'row': 740}), Document(page_content=': 28\ntime: 2018-01-29\nsusceptible: 0\ninfectious: 1705\nremoved: 25353\ncity: city9', metadata={'source': 'sir.csv', 'row': 838}), Document(page_content=': 23\ntime: 2018-01-24\nsusceptible: 0\ninfectious: 3884\nremoved: 33453\ncity: city3', metadata={'source': 'sir.csv', 'row': 293}), Document(page_content=': 16\ntime: 2018-01-17\nsusceptible: 1\ninfectious: 1839\nremoved: 6703\ncity: city7', metadata={'source': 'sir.csv', 'row': 646}), Document(page_content=': 15\ntime: 2018-01-16\nsusceptible: 1\ninfectious: 6350\nremoved: 20708\ncity: city9', metadata={'source': 'sir.csv', 'row': 825})]驚くべきことに、2018年02月03日の出来事を知りたいと指定したにもかかわらず、その日付の行は返されませんでした。ChatGPTにその日付の情報が一切送信されていないため、当然ながらそのような質問には答えることができません。
リトリーバーのソースコードを掘り下げてみると、get_relevant_documentsはデフォルトでsimilarity_searchを呼び出していることがわかります。このメソッドは、クエリのベクトルとドキュメントチャンクのベクトルとの「類似度」を測る、0から1までの距離メトリック(デフォルトはコサイン距離)に基づいて、トップnのチャンク(デフォルトでは4ですが、コードでは20に設定しました)を返します。
SIRデータセットに戻ると、各行がほぼ同じストーリーを伝えていることに気付きます:いつ、どの都市で、どのグループとしてマークされた人数がいくつあるか。これらの行を表すベクトルが互いに類似していることは驚くことではありません。類似度スコアのクイックチェックでは、多くの行がスコア0.29前後で終わっていることがわかります。
したがって、類似度スコアはクエリにどのように関連しているかの行を区別するのに十分な強さではありません。これは、行間に著しい違いがない表形式データの場合に常に起こることです。メタデータで動作するより強力なフィルタが必要です。
カスタマイズされたメタデータを持つCSVLoader
チャットボットのパフォーマンスの改善は、大部分がリトリーバーの効率に依存することが明らかです。そのため、メタデータ情報をリトリーバーとやり取りできるようにするカスタマイズされたCSVLoaderを定義して始めます。
以下のコードを書きます:
class MetaDataCSVLoader(BaseLoader): """CSVファイルをドキュメントのリストにロードします。 各ドキュメントはCSVファイルの1行に対応します。各行はキー/値のペアに変換され、ドキュメントのpage_contentの新しい行に出力されます。 csvからロードされる各ドキュメントのソースは、デフォルトでは`file_path`引数の値に設定されます。 `source_column`引数をCSVファイルの列名に設定することで、各ドキュメントのソースは `source_column`で指定された名前の列の値に設定されます。 出力例: .. code-block:: txt column1: value1 column2: value2 column3: value3 """ def __init__( self, file_path: str, source_column: Optional[str] = None, metadata_columns: Optional[List[str]] = None, content_columns: Optional[List[str]] =None , csv_args: Optional[Dict] = None, encoding: Optional[str] = None, ): # 省略 (オリジナルのコードと同じ保存) self.metadata_columns = metadata_columns # < 追加 def load(self) -> List[Document]: """データをドキュメントオブジェクトにロードします。""" docs = [] with open(self.file_path, newline="", encoding=self.encoding) as csvfile: # 省略 (オリジナルのコードと同じ保存) # 追加コード if self.metadata_columns: for k, v in row.items(): if k in self.metadata_columns: metadata[k] = v # 追加コードの終わり doc = Document(page_content=content, metadata=metadata) docs.append(doc) return docsスペースを節約するために、オリジナルのAPIと同じコードは省略して、メタデータに特別な注意が必要な特定の列を追加するために主に使用される追加の数行だけを含めました。実際には、上記の出力データには2つのパートがあることに気付くことができます:ページのコンテンツとメタデータ。標準のCSVLoaderは、テーブルのすべての列をページのコンテンツに書き込み、データリソースと行番号のみをメタデータに書き込みます。定義された「MetaDataCSVLoader」では、他の列をメタデータに書き込むことができます。
上記のセクションと同じ手順で、データローダーに「time」と「city」という2つのメタデータカラムを追加した以外、同じ手順でベクターストアを再作成します。
# データをロードして埋め込みローダーを設定する loader = MetaDataCSVLoader(file_path="sir.csv",metadata_columns=['time','city']) #<= modified data = loader.load()メタデータに基づいたベクターストアでのセルフクエリ
これで、LangChainのセルフクエリAPIを使用する準備が整いました。
LangChainのドキュメントによると、自己クエリリトリーバー(Self-Querying Retriever)とは、その名前が示すように、自身にクエリを発行することができるものです。…これにより、リトリーバーは、ユーザー入力のクエリを格納されたドキュメントの内容との意味的な類似性比較に使用するだけでなく、格納されたドキュメントのメタデータからユーザークエリのフィルタを抽出し、それらのフィルタを実行することもできます。
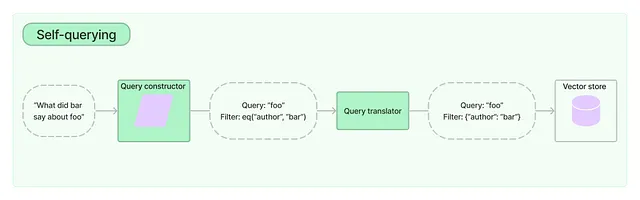
前の章でメタデータを強調した理由が理解できると思います。メタデータは、ChatGPTや他のLLMがデータセットから最も関連性の高い情報を取得するために基づいています。次のコードを使用して、メタデータとドキュメントの内容の説明を記述し、それに基づいて優れたフィルタを構築して正確な情報を抽出する自己クエリリトリーバーを作成します。特に、retrieverにmetadata_field_infoを指定し、リトリーバーがより注意を払う必要のある2つの列のタイプと説明を指定します。
llm=ChatOpenAI(model_name="gpt-4",temperature=0)metadata_field_info=[ AttributeInfo( name="time", description="人口の測定時刻", type="datetime", ), AttributeInfo( name="city", description="人口測定が行われた都市", type="string", ),]document_content_description = "10の都市で90日間の感受性、感染、除去人口"retriever = SelfQueryRetriever.from_llm( llm, vectorstore, document_content_description, metadata_field_info, search_kwargs={"k": 20},verbose=True)今度はSelfQueryRetrieverを使用してSIRデータセットをクエリするための同様のConversationalRetrieverChainを定義できます。同じ質問「2018-02-03において最も感染者の多い都市はどこですか?」をすると、今回はどうなるか見てみましょう。
チャットボットは次のように言いました:「2018-02-03において最も感染者の多い都市はcity3で、感染者は1413人です。」
皆さん、正しいです!チャットボットはより優れたリトリーバーでその役割を果たしています!
今回リトリーバーが返す関連文書を見ることには何の問題もありません。以下のような結果が得られます:
[Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 1413\nremoved: 35924\ncity: city3', metadata={'source': 'sir.csv', 'row': 303, 'time': '2018-02-03', 'city': 'city3'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 822\nremoved: 20895\ncity: city4', metadata={'source': 'sir.csv', 'row': 393, 'time': '2018-02-03', 'city': 'city4'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 581\nremoved: 14728\ncity: city5', metadata={'source': 'sir.csv', 'row': 483, 'time': '2018-02-03', 'city': 'city5'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 1355\nremoved: 34382\ncity: city6', metadata={'source': 'sir.csv', 'row': 573, 'time': '2018-02-03', 'city': 'city6'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 496\nremoved: 12535\ncity: city8', metadata={'source': 'sir.csv', 'row': 753, 'time': '2018-02-03', 'city': 'city8'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 1028\nremoved: 26030\ncity: city9', metadata={'source': 'sir.csv', 'row': 843, 'time': '2018-02-03', 'city': 'city9'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 330\nremoved: 8213\ncity: city7', metadata={'source': 'sir.csv', 'row': 663, 'time': '2018-02-03', 'city': 'city7'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 1320\nremoved: 33505\ncity: city2', metadata={'source': 'sir.csv', 'row': 213, 'time': '2018-02-03', 'city': 'city2'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 776\nremoved: 19753\ncity: city1', metadata={'source': 'sir.csv', 'row': 123, 'time': '2018-02-03', 'city': 'city1'}), Document(page_content=': 33\ntime: 2018-02-03\nsusceptible: 0\ninfectious: 654\nremoved: 16623\ncity: city0', metadata={'source': 'sir.csv', 'row': 33, 'time': '2018-02-03', 'city': 'city0'})]今回取得したドキュメントの「メタデータ」には、「時間」と「都市」が含まれていることに気づくかもしれません。
結論
このブログ投稿では、CSV形式のデータセットをクエリする際のChatGPTの制限について、例として10都市の90日間のSIRデータセットを使用して探求しました。これらの制限に対処するために、新しいアプローチを提案しました:メタデータに注意を払ったCSVデータローダーを使用することで、自己クエリAPIを活用し、Chatbotの精度とパフォーマンスを大幅に向上させることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
