「LangchainとOpenAIを使用したGoogleドキュメントのためのチャットボット」
Chatbot for Google Docs using Langchain and OpenAI
イントロダクション
この記事では、OpenAIとLangchainを使用してGoogleドキュメント用のチャットボットを作成します。では、なぜ最初にこれを行う必要があるのでしょうか?Googleドキュメントの内容をOpenAIにコピー&ペーストするのは手間がかかります。OpenAIには文字トークンの制限があり、特定の情報しか追加できません。したがって、スケールで実行するか、プログラムで実行する場合は、ライブラリのヘルプが必要です。そこで、Langchainが登場します。LangchainをGoogleドライブとOpenAIと接続することで、製品ドキュメント、研究ドキュメント、または会社が使用している内部の知識ベースなど、ドキュメントを要約し関連する質問をすることでビジネスへの影響を創出することができます。
学習目標
- Langchainを使用してGoogleドキュメントのコンテンツを取得する方法を学ぶことができます。
- GoogleドキュメントのコンテンツをOpenAI LLMと統合する方法を学ぶことができます。
- ドキュメントのコンテンツを要約し、関連する質問をする方法を学ぶことができます。
- ドキュメントに基づいて質問に答えるチャットボットを作成する方法を学ぶことができます。
この記事は、Data Science Blogathonの一部として公開されました。
ドキュメントの読み込み
始める前に、Googleドライブにドキュメントを設定する必要があります。ここで重要なのは、Langchainが提供するドキュメントローダーであるGoogleDriveLoaderです。これを使用して、このクラスを初期化し、ドキュメントIDのリストを渡すことができます。
from langchain.document_loaders import GoogleDriveLoader
import os
loader = GoogleDriveLoader(document_ids=["あなたのドキュメントID"],
credentials_path="credentials.jsonファイルへのパス")
docs = loader.load()ドキュメントIDはドキュメントリンクから見つけることができます。リンクの/d/の後ろのスラッシュの間にIDがあります。
たとえば、ドキュメントリンクが https://docs.google.com/document/d/1zqC3_bYM8Jw4NgF の場合、ドキュメントIDは「1zqC3_bYM8Jw4NgF」です。
これらのドキュメントIDのリストをdocument_idsパラメータに渡すことができます。また、この素晴らしいところは、ドキュメントを含むGoogleドライブフォルダーIDも渡すことができることです。フォルダーリンクが https://drive.google.com/drive/u/0/folders/OuKkeghlPiGgWZdM の場合、フォルダーIDは「OuKkeghlPiGgWZdM1TzuzM」です。
Googleドライブの認証
ステップ1:
GoogleDrive APIを有効にするには、このリンク(https://console.cloud.google.com/flows/enableapi?apiid=drive.googleapis.com)を使用してください。ドキュメントがドライブに保存されているGmailアカウントでログインしていることを確認してください。
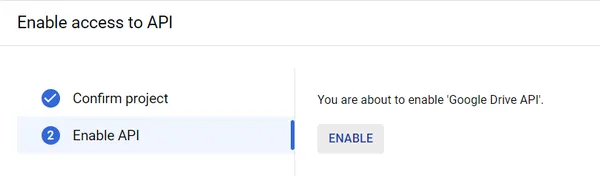
ステップ2: このリンクをクリックしてGoogle Cloudコンソールに移動します。[OAuthクライアントID]を選択します。アプリケーションのタイプは[デスクトップアプリ]とします。
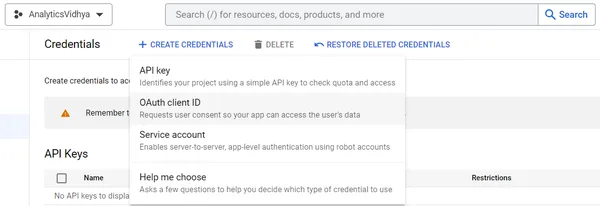
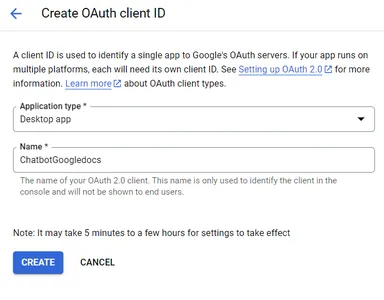
ステップ3: OAuthクライアントを作成した後、「JSONをダウンロード」をクリックしてシークレットファイルをダウンロードします。クレデンシャルファイルの作成中に疑問がある場合は、Googleの手順に従ってください。
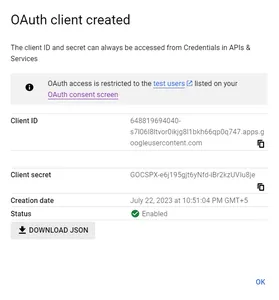
ステップ4: 以下のpipコマンドを実行してGoogle API Pythonクライアントをアップグレードします
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib次に、jsonファイルのパスをGoogleDriveLoaderに渡す必要があります。
ドキュメントの要約
OpenAIのAPIキーを利用できるようにしてください。利用できない場合は、以下の手順に従ってください:
1. ’https://openai.com/’にアクセスし、アカウントを作成してください。
2. アカウントにログインし、ダッシュボードで「API」を選択してください。
3. そして、プロフィールアイコンをクリックし、「APIキーの表示」を選択します。
4. 「新しいシークレットキーを作成」を選択し、コピーして保存してください。
次に、OpenAI LLMを読み込む必要があります。OpenAIを使用して読み込まれたドキュメントを要約しましょう。以下のコードでは、langchainが提供するsummarize_chainという要約アルゴリズムを使用して、入力ドキュメントを取り入れ、map_reduceアプローチを使用して簡潔な要約を生成するsummarizationプロセスを作成し、chainという変数に保存しています。以下のコードでAPIキーを置き換えてください。
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
llm = OpenAI(temperature=0, openai_api_key=os.environ['OPENAI_API_KEY'])
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=False)
chain.run(docs)このコードを実行すると、ドキュメントの要約が得られます。LangChainが内部で行っている処理を確認したい場合は、verboseをTrueに変更すると、LangChainの使用方法と思考プロセスを確認できます。LangChainは自動的に要約するためのクエリを挿入し、クエリ+ドキュメントの内容全体がOpenAIに渡されます。そしてOpenAIが要約を生成します。
以下は、製品SecondaryEquityHubに関連するGoogleドライブのドキュメントを送信し、map_reduceチェーンタイプとload_summarize_chain()関数を使用してドキュメントを要約した使用例です。内部のLangchainの動作を確認するためにverbose=Trueに設定しています。
from langchain.document_loaders import GoogleDriveLoader
import os
loader = GoogleDriveLoader(document_ids=["ceHbuZXVTJKe1BT5apJMTUvG9_59-yyknQsz9ZNIEwQ8"],
credentials_path="../../desktop_credetnaisl.json")
docs = loader.load()
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
llm = OpenAI(temperature=0, openai_api_key=os.environ['OPENAI_API_KEY'])
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
chain.run(docs)出力:
Langchainが与えられたドキュメントの要約を生成するためのプロンプトを挿入したことがわかります。

OpenAI LLMを使用してLangchainが生成したドキュメントの簡潔な要約と製品の特徴が表示されます。
その他のユースケース
1. 研究: 研究を行う際に、研究論文全体を徹底的に読む代わりに、要約機能を使用して論文の概要を素早く把握することができます。
2. 教育: 教育機関は、大量のデータ、学術書、論文から選りすぐられた教科書の要約を取得することができます。
3. ビジネスインテリジェンス: データアナリストは、文書から洞察を抽出するために大量の文書を処理する必要があります。この機能を使用することで、膨大な作業量を削減することができます。
4. 法的事例分析: 法律実務の専門家は、過去の類似のケース文書の大量の中から重要な議論を迅速に抽出するために、この機能を使用することができます。
ドキュメントに関連する質問をする
あるドキュメントの内容に関する質問をしたい場合、load_qa_chainという別のチェーンを読み込む必要があります。次に、このチェーンをchain_typeパラメータで初期化します。この場合、chain_typeとして「stuff」と使用しました。これはシンプルなチェーンタイプであり、すべてのコンテンツを連結してLLMに渡します。
他のchain_types:
- map_reduce: モデルは最初に個々のドキュメントを個別に調査してその洞察を保存し、最後にこれらの洞察を組み合わせて再度見直し、最終的な回答を得ます。
- refine: モデルはドキュメントIDリストで与えられた各ドキュメントを反復的に調査し、進行するにつれてドキュメントで見つかった最新の情報で回答を洗練します。
- Map re-rank: モデル は個々のドキュメントを個別に調査し、洞察にスコアを割り当てます。最終的には最も高いスコアを持つものを返します。
次に、入力ドキュメントとクエリを渡してチェーンを実行します。
from langchain.chains.question_answering import load_qa_chain
query = "Who is founder of analytics vidhya?"
chain = load_qa_chain(llm, chain_type="stuff")
chain.run(input_documents=docs, question=query)このコードを実行すると、langchainは自動的にドキュメントの内容と共にプロンプトを挿入し、これをOpenAI LLMに送信します。裏では、langchainは最適化されたプロンプトを提供して、ドキュメントから必要なコンテンツを抽出するためのプロンプトエンジニアリングをサポートしています。内部で使用しているプロンプトを確認したい場合は、verbose=Trueに設定するだけで、出力でプロンプトを確認できます。
from langchain.chains.question_answering import load_qa_chain
query = "Who is founder of analytics vidhya?"
chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
chain.run(input_documents=docs, question=query)Chatbotの作成
次に、このモデルを質問応答のChatbotにする方法を見つける必要があります。主にChatbotを作成するためには、以下の3つのことに従う必要があります。
1. Chatbotは、進行中の会話に関する文脈を理解するために、チャット履歴を記憶する必要があります。
2. ユーザーがボットに対してプロンプトを行うたびに、チャット履歴を更新する必要があります。
2. ユーザーが会話を終了するまで、Chatbotは動作する必要があります。
from langchain.chains.question_answering import load_qa_chain
# Langchainの質問応答チェーンをロードするための関数
def load_langchain_qa():
llm = OpenAI(temperature=0, openai_api_key=os.environ['OPENAI_API_KEY'])
chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
return chain
# ユーザーの入力を処理し、応答を生成するための関数
def chatbot():
print("Chatbot: Hi! I'm your friendly chatbot. Ask me anything or type 'exit' to end the conversation.")
from langchain.document_loaders import GoogleDriveLoader
loader = GoogleDriveLoader(document_ids=["YOUR DOCUMENT ID's'"],
credentials_path="PATH TO credentials.json FILE")
docs = loader
# Langchainの質問応答チェーンを初期化する
chain = load_langchain_qa()
# チャット履歴を格納するためのリスト
chat_history = []
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
print("Chatbot: Goodbye! Have a great day.")
break
# ユーザーの質問をチャット履歴に追加する
chat_history.append(user_input)
# 質問応答チェーンを使用してユーザーの質問を処理する
response = chain.run(input_documents=chat_history, question=user_input)
# 応答から回答を抽出する
answer = response['answers'][0]['answer'] if response['answers'] else "I couldn't find an answer to your question."
# チャットボットの応答をチャット履歴に追加する
chat_history.append("Chatbot: " + answer)
# チャットボットの応答を表示する
print("Chatbot:", answer)
if __name__ == "__main__":
chatbot()GoogleドライブのドキュメントとOpenAI LLMを初期化しました。次に、チャット履歴を格納するためのリストを作成し、各プロンプトの後にリストを更新しました。そして、ユーザーが「exit」と入力すると、停止する無限のwhileループを作成しました。
結論
この記事では、Googleドキュメントの内容についての洞察を提供するChatbotを作成する方法を見ました。Langchain、OpenAI、およびGoogleドライブを統合することは、医療、研究、産業、エンジニアリングなど、どの分野でも非常に有益なユースケースの一つです。データ全体を読み込んでデータを分析し、洞察を得るために多くの人間の労力と時間がかかる代わりに、この技術を実装してデータファイルからの説明、要約、分析、洞察の自動化を行うことができます。
キーポイント
- Googleドキュメントは、PythonのGoogleDriveLoaderクラスとGoogle Drive APIの資格情報を使用してPythonに取り込むことができます。
- OpenAI LLMとLangchainを統合することで、ドキュメントの要約を作成し、ドキュメントに関連する質問をすることができます。
- map_reduce、stuff、refine、map rerankなどの適切なチェーンタイプを選択することで、複数のドキュメントから洞察を得ることができます。
よくある質問
この記事に表示されるメディアはAnalytics Vidhyaの所有物ではなく、著者の裁量により使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






