「チャットモデル対決:GPT-4 vs. GPT-3.5 vs. LLaMA-2によるシミュレートされた討論会-パート1」
Chat Model Battle Simulated Debate with GPT-4 vs. GPT-3.5 vs. LLaMA-2 - Part 1

すべてを統括する1つのモデル
Metaが最近、GPT-4と競合するチャットモデルを構築する計画を発表し、AnthropicがClaude2をリリースしたことで、どのモデルが最も優れているかについての議論がますます激化しています。これらのモデルを評価する包括的なフレームワークのベンチマークと基準を作成するために、多くのイニシアチブが取られています。例えば、ここでは2023年9月21日現在のChatbot Arena Leaderboardのスナップショットを紹介します。これは、lmsys.orgが様々なベンチマークを使用してモデルのランキングを提供しているものです。
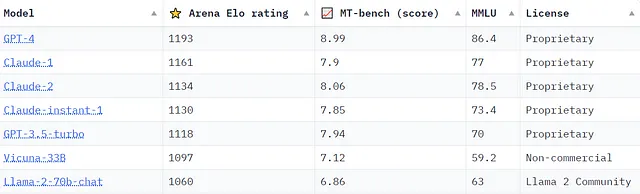
「Arena Elo rating」は、lmsys.orgのChatbot Arenaに由来しています。Chatbot Arenaは、2つのモデルの出力を人間による品質比較のために並べて表示するクラウドソーシングの評価プラットフォームです。一方、「MT-bench(score)」は、GPT-4を審査員として使用して、モデルをマルチターンの質問フレームワークで評価します。これらのベンチマークの詳細情報やChatbot Arenaへのアクセスは、lmsys.orgで確認できます。
モデルのリーダーボードは便利ですが、多くの人々はGPT-4などのチャットモデルの印象的な品質を直接体験して認識する必要があります。これらのモデルは、さまざまな個人向けのアプリケーションで私たちを驚かせる能力を持っています。では、次世代のモデルの能力を評価し、既に印象的な能力を改善しているかどうかを判断するにはどうすればよいでしょうか?
モデルと推論能力のシミュレーション
モデルの「推論」能力は、引き続き注目を集めています。動詞としての「推論」の定義について、Googleにインサイトを求めてみましょう。
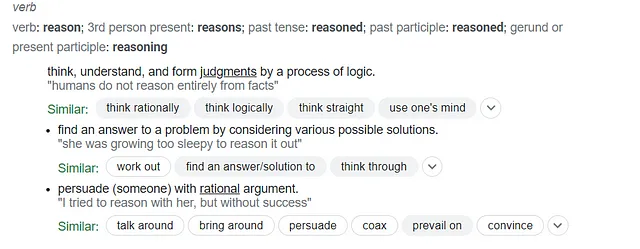
「推論」を定義するこれらの3つのエントリを考えると、現在のモデルは推論そのものを再現するようには設計されていません。特定の入力(プロンプト)に対して、彼らは単に次に最も適切な単語を予測し、出力に1語ずつ(トークンごとに)生成するだけです。ただし、私は特定のモデルがある程度の推論をシミュレートしていると考えることについて、私だけでないと思います。これらの概念を解明するために、さらに探求するための少しの実験を試みることにしました。テキスト生成モデルのシミュレートされたディベートによって、思考、論理、判断、議論を包括する高次の推論能力をモデルがどのように評価することができるでしょうか?これは単なる興味深い思考実験に聞こえるかもしれませんが、私はそれが単なる娯楽以上のものを提供していると信じています。自分自身に挑戦し、何を学べるのかに興味津々で、以下の目標を設定しました:
- Pythonで、少なくとも2つのチャットモデル、シミュレートされたディベート審査員、シミュレートされたディベートモデレータ、人間の観客をフィーチャーした対話型ディベートシミュレーションを開発する。
- この特定のユースケースに対するLangChainライブラリの能力をテストする。
- シミュレーションデータをMongoDBクラスタにプッシュして、さらなる分析を行う。
- Streamlitを利用して、使いやすいインターフェースの追加を検討する。
中級レベルのPythonコーダーとして、1年前にこのようなプロジェクトに着手することは困難でした。ディベート参加者の仕組みを開発するような単一の機能さえも、乗り越えられない課題であり、エンジニアのチームが必要な作業でした。では、なぜ1年後の今、私のような非専門家にとってこのプロジェクトが実現可能になったのでしょうか?
AI as a Service(AIaaS)の台頭
これは少し脇道ですが、他の人々に探求と実験を促すために議論する価値があると思います。過去の1年間における生成型AIの進歩は、非常に驚くべきものです。現在の舞台装置についての私の考えを下の図(詳細は少ないですが)に示します。これは、わずか1年前とはまったく異なる風景でした。OpenAI、Meta、Googleなど多くの企業が、高度な生成型AIモデルをモジュラー化し、普遍的にアクセス可能なものに革新的な変化をもたらしました(青い箱)。その結果、人工知能サービス(AIaaS)の提供が飛躍的に増えました。これをプロンプトエンジニアリングの同時的な急増と組み合わせることで、私は前例のない未来の革新の波が訪れると考えています。
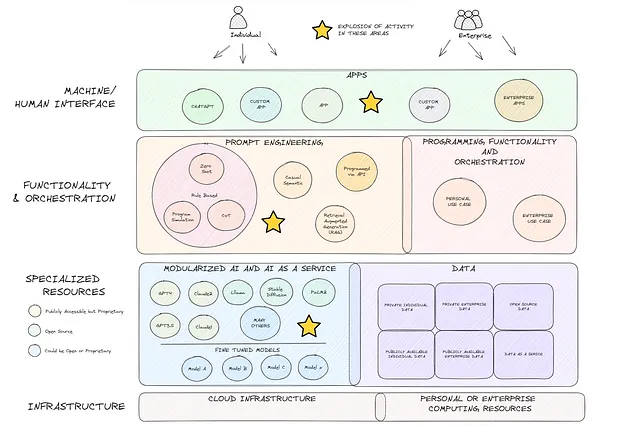
ディベートシミュレーションプログラム
それでは、プロジェクトに入っていきましょう。コードに興味がない場合は、「ディベート結果」までスキップしてください。まず、このプロトタイプではGoogle Colabを使用しました。それについて詳しく知りたい場合は、こちらで詳細情報を見つけることができます。ユーザーフレンドリーで完全にクラウドベースのプラットフォームで、すぐにコーディングを始めるのに最適です。さて、まずは必要なライブラリをインストールしましょう。
pip install langchainpip install openaipip install replicateLangChainとOpenAIは耳慣れた名前かもしれません。しかし、Replicateは新しいかもしれません。ReplicateはクラウドベースのAPIプラットフォームで、オープンソースの機械学習モデルを実行してホストするためのものです。具体的には、チャット補完に適応されたホステッドLLaMA2モデルを利用します(詳細はこちら)。Replicateに登録し、APIキーを取得すると、一定期間無料でAPIを通じてプロンプトを実行することができます。クレジットを使い果たした後は有料になります。推論時間ごとに請求され、価格についてはこちらで確認できます。Replicateの代替としてはHuggingFaceが考えられますが、推論エンドポイントの設定など、より多くの手順が必要です。
次に、LangChainから必要なモジュールとプロジェクトに必要な他のライブラリをインポートし、APIキーを設定します。
from langchain.prompts.chat import SystemMessagePromptTemplatefrom langchain.llms import Replicatefrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplatefrom langchain.output_parsers import StructuredOutputParser, ResponseSchemafrom langchain.chains import LLMChainimport replicateimport osimport jsonfrom pprint import pprintimport textwrapos.environ['OPENAI_API_KEY'] = "YOUR-OPENAI-API-KEY-HERE"os.environ['REPLICATE_API_TOKEN'] = "YOUR-REPLICATE-API-KEY-HERE"まずは、モデルを読み込みましょう。LangChainの統合を介して「chatmodelgpt_3_point_5_turbo」と「chatmodelgpt_4」を読み込みます。これらのモデルを読み込む際には、温度、ストリーミングのオン/オフ、max_tokensなどのさまざまなパラメータを調整する柔軟性があります(詳細はこちらのドキュメントを参照してください)。”chatmodel_llama_2″については、Replicateライブラリを使用しますので、現時点ではモデル名のみを保存します。ReplicateホステッドLLaMA-2モデルの情報は、こちらで見つけることができます。私はミックスにClaudeを含めたかったのですが、AnthropicからのAPIキーをまだ待っています。
なお、OpenAIのAPIを介してチャットモデルにアクセスすることにはコストがかかりますので、新しく取り組む方はこちらの詳細情報をご覧ください。
chatmodelgpt_3_point_5_turbo = ChatOpenAI(model_name="gpt-3.5-turbo")chatmodelgpt_4 = ChatOpenAI(model_name="gpt-4")chatmodel_llama_2 = "meta/llama-2-70b-chat:4dfd64cc207097970659087cf5670e3c1fbe02f83aa0f751e079cfba72ca790a"さあ、ディベートの枠組みを概念化し、それに応じてプロンプトを作成しましょう。第1部では、以下のようにディベートのメカニズムを構築します:
- 人間の観察者がディベートのトピック領域を提案します。
- AIシミュレーションされたモデレーターが、提案されたトピックに基づいて3つの命題を作成します。
- 人間の観察者がディベートのためにこれらの命題のうちの1つを選択します。
- AIシミュレーションされた参加者が、命題に対する立場を決めて(賛成または反対)、自分の主張を述べます。
- AIシミュレーションされたディベート審判が提示された主張を評価し、スコアを付けます。
プロセスを効率化するために、プロンプトをエンジニアリングし、コード内の「プロンプトライブラリ」に保存します。これにより、必要に応じてプロンプトを調整できます。AIディベート審判がディベートの評価をどのように行うかについてのガイダンスについては、GPT4と協力してディベート評価スコアリングの枠組みを作成しました。
#プロンプトに使用するテキストのライブラリ:moderator_prompt_txt = """ディベートのモデレーターとして、2つ以上の参加者間でディベートを調整している経験豊富なディベートモデレーターとして行動します。人間の観察者が提供したトピック'{topic}'に基づいて、ディベートモデレーターとして、パーティー間で議論される可能性のある3つの命題を作成します。例えば、気候変動に関する命題として「気候変動は主に人間によって引き起こされている」という命題があります。または質問として「気候変動は主に人間によって引き起こされているのか?」とも言えます。\n{proposition_format_instructions}"""participant_prompt_txt = """複数の参加者によるディベートの参加者として行動します。あなたの名前は'{participant}'です。以下の命題が提示されました:'{proposition}'あなたの目標はディベートに勝つことです。この目標を達成するために、命題に賛成するか反対するかを決めます。命題に賛成または反対の主張をすることが決まったら、最も優れた主張を行います。主張は、組織と明確さ(スコアの20%)、戦略とスタイル(スコアの40%)、および主張、証拠、およびコンテンツの効果(スコアの40%)に基づいて、独立した専門家のディベート審判によって評価およびスコアが付けられます。評価領域は重複することがあります。例えば、具体的な問題を正しく特定し、主張のための証拠を適切に使用するかもしれませんが、それを混乱したり断片化した方法で行います。この場合、審判は主張の効果に対して高いスコアを、戦略とスタイルに対してVoAGIレベルのスコアを、組織と明確さに対して低いスコアを割り当てるかもしれません。明確にするために、賛成の主張と反対の主張の両方を提供しないでください。時間をかけて、できるだけ多くのポイントを獲得し、ディベートに勝つために、説得力のある、雄弁で納得のいく方法で主張を提示することに集中してください。あなたの主張は、300語以下である必要があります。"""judge_prompt_txt = """経験豊富なディベート審判として行動します。以下の命題について、ディベート参加者が行った主張を評価し、スコアを付けるよう求められます:'{proposition}' {participant}は次のような主張を行いました:'{participant_argument}' 評価対象の主張について、主張を評価し、評価を行い、以下の基準と方法論に基づいてスコアを付けます:{judging_criteria} 各評価セクションが完了したら、セクションのスコアを合計して総合スコアを算出します。各セクションのスコアだけでなく、そのセクションのスコアがどのように決定されたかについての簡単なコメントも提供します。また、参加者のパフォーマンスについての2文の全体的な評価も提供します。次の表は、総合スコアに対応する主張の全体的な品質ラベルを示しています:81〜100点:優れています61〜80点:良い36〜60点:普通0〜35:悪いこれらのラベルは、2文の全体的な評価を提供する際に使用する必要があります。\n{score_format_instructions}"""judging_criteria = """これは、引数を評価し、合計100ポイント中のスコアを割り当てるためのディベート審判方法論です:セクション1 - 組織と明確さ - 最大スコア20ポイントを以下のように割り当てます:0〜5ポイント:組織が不十分で、構造が不明瞭で、理解が難しい。6〜10ポイント:やや組織化されており、やや明確な構造で、比較的理解しやすい。11〜15ポイント:よく組織化され、明確な構造で、理解しやすい。16〜20ポイント:非常に組織化され、非常に明確な構造で、非常に理解しやすい。セクション2 - 戦略とスタイル - 最大スコア40ポイントを以下のように割り当てます:0〜10ポイント:戦略とスタイルが不十分で、関与がなく、非常に物足りなく、無効な修辞法と言語の使用。11〜20ポイント:やや適切な戦略とスタイル、多少関与し、物足りなく、限られた修辞法と言語の使用。21〜30ポイント:良好な戦略とスタイル、関与し、説得力があり、効果的な修辞法と言語の使用。31〜40ポイント:優れた戦略とスタイル、非常に関与し、説得力があり、巧みな修辞法と言語の使用。セクション3 - 主張、証拠、およびコンテンツの効果 - 最大スコア40ポイントを以下のように割り当てます:0〜10ポイント:主要な論理的な欠陥、虚偽の証拠またはコンテンツ、または十分な支持材料がない弱い主張。11〜20ポイント:いくつかの論理的な欠陥、限られた虚偽の証拠またはコンテンツ、または不十分な支持材料があるいくぶん効果的な主張。21〜30ポイント:軽微な論理的な欠陥、最小限の虚偽の証拠またはコンテンツ、または十分な支持材料がある効果的な主張。31〜40ポイント:非常に効果的な主張で、完璧な論理、虚偽の証拠またはコンテンツがなく、説得力のある支持材料があります。"""上記のプロンプトテキストライブラリに関するいくつかの注意点。
- 議論の構造: 第1部の探究では、一方が提案を支持し、他方がそれに反対する形式の公式の討論のメカニズムからは逸脱しています。このより複雑な多回転の対立的な設定は、第2部で焦点を当てる予定です。
- 目標の追求: 参加者のプロンプトは、「討論に勝つ」ことを目指しています。これはランダムな選択ではありません。目標の追求が人間の認知に基本的であるというアイデアを支持する心理学的な研究が多くあります。目標の追求をプロンプトに統合することがどのように出力に影響を与えるかを見るのが好奇心です。
- ブラケット内の動的な値: {topic}、{proposition}、{proposition_format_instructions}など、中括弧内のいくつかの表現に注意してください。これらのプレースホルダは、後のコードからの動的な値に適応するために設計されています。
- 応答制限: 可管理性のために、応答に300語の制限を設定しています。いずれの時点で、参加者がこのパラメータにどれだけ適合しているかを評価します。
次に、討論モデレータの振る舞いについて取り組みましょう。最初のタスクの一つは、チャットモデルの出力をどのように扱うかを決定することです。そのために、LangChainのStructured Output Parser(詳細はこちら)が非常に便利です。本質的に、以下のresponse_schema_propositionsの定義は辞書を生成します。この辞書を特定のキーと値の形式に準拠させることで、人間の観察者が討論対象の提案を選択しやすくなります。
次に、LangChainのPromptTemplate(ドキュメントはこちら)を使用して討論モデレータのプロンプトを構造化します。ご覧のように、「トピック」を人間の観察者が選択し、定義した「プロンプトライブラリ」でモデレータのテキストを読み込み、出力パーサースキーマで定義した「提案形式の指示」を指定しています。
#討論モデレータの出力パーサースキーマ、3つの提案のキー:値の辞書出力を定義するresponse_schema_propositions = [ ResponseSchema(name="提案1", description="トピックに基づく最初の提案。"), ResponseSchema(name="提案2", description="トピックに基づく2番目の提案。"), ResponseSchema(name="提案3", description="トピックに基づく3番目の提案。")]output_parser_moderator = StructuredOutputParser.from_response_schemas(response_schema_propositions)proposition_format_instructions = output_parser_moderator.get_format_instructions()#討論モデレータのプロンプトテンプレートmoderator_prompt = PromptTemplate( input_variables=["topic"], template=moderator_prompt_txt, partial_variables={"proposition_format_instructions":proposition_format_instructions})討論参加者のプロンプト設定は、討論モデレータと同様ですが、出力の解析は必要ありません。討論対象の提案、参加者の名前、参加者のプロンプトテキストを渡します。
討論審判のプロンプトでは、出力を解析して見やすい構造化された結果を得たいと思います。これにより、結果がより理解しやすくなるだけでなく、第2部でMongoDBインスタンスにデータを送信するのを容易にすることもできます。最後に、議論された提案、参加者の名前、彼らの主張、審判が使用する評価基準を渡します。
#討論審判の出力パーサースキーマ、引数として渡されるキー:値の辞書出力を定義するresponse_schema_score = [ ResponseSchema(name="参加者の名前", description="参加者の名前"), ResponseSchema(name="賛成か反対か", description="主張が賛成か反対か"), ResponseSchema(name="組織と明瞭さのスコア(最大20点)", description="評価の組織と明瞭さセクションのスコア"), ResponseSchema(name="組織と明瞭さスコアの詳細", description="組織と明瞭さセクションのスコアの詳細"), ResponseSchema(name="戦略とスタイルのスコア(最大40点)", description="評価の戦略とスタイルセクションのスコア"), ResponseSchema(name="戦略とスタイルスコアの詳細", description="戦略とスタイルセクションのスコアの詳細"), ResponseSchema(name="主張、証拠、コンテンツの効果のスコア(最大40点)", description="評価の主張、証拠、コンテンツセクションのスコア"), ResponseSchema(name="主張、証拠、コンテンツスコアの詳細", description="主張、証拠、コンテンツセクションのスコアの詳細"), ResponseSchema(name="全体的なスコア(最大100点)", description="参加者の主張の評価の全体的なスコア"), ResponseSchema(name="全体的な評価ラベル", description="総合スコアに対応する1つの単語のラベル"), ResponseSchema(name="全体的な評価の要約", description="参加者の主張の2文の総合評価")]output_parser_judge = StructuredOutputParser.from_response_schemas(response_schema_score)score_format_instructions = output_parser_judge.get_format_instructions()#討論審判のプロンプトjudge_prompt = ChatPromptTemplate( input_variables=["proposition", "participant", "participant_argument", "judging_criteria"], messages=[HumanMessagePromptTemplate.from_template(judge_prompt_txt)], partial_variables={"score_format_instructions":score_format_instructions})LangChainは、「チェーン」という概念に重点を置いています(詳細はこちら)。正直言って、その説明は少し混乱しているように感じます。もっと分かりやすく考えるなら、各「チェーン」を「リンク」と考えて、SimpleSequentialChain()を使用して必要に応じてそれらを連鎖させることができるかもしれません(詳細はこちら)。
さて、次に、LLMChainメソッドを使用してディベートの参加者をインスタンス化しましょう。LangChainは、コードを整理するのに役立ち、以下の内容はかなり明確です。
後でReplicateライブラリを使ってLLaMA-2を直接実行します。ReplicateにはLangChainの統合もありますが、対象となるモデルが解決できないエラーを出していました。
# LLMChainメソッドを呼び出して、シミュレーションで実行されるインスタンスを作成します
moderator = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt = moderator_prompt)
turbo = LLMChain(llm=chatmodelgpt_3_point_5_turbo, prompt=participant_prompt)
king_gpt = LLMChain(llm=chatmodelgpt_4, prompt=participant_prompt)
judge = LLMChain(llm=chatmodelgpt_4, prompt = judge_prompt)次に、インタラクティブなプログラムの構築に焦点を当てましょう。目標は、これをインタラクティブにし、人間の観察者からの入力を取得することでした。記事の長さのため、このコードのセクションでは、コード内にインラインコメントを含めて、その動作を明確に説明します。
# シミュレートされたディベートプログラム
while True:
user_input = input("Human Observer: ディベートのトピックを指定してください(終了するには 'quit' と入力してください):") # 人間の観察者にトピックを指定するように要求
if user_input.lower() == "quit":
break
else:
moderator_topics_raw = moderator.run(topic=user_input) # 人間の観察者が選んだトピックで「moderator」を実行
moderator_topics_struct = output_parser_moderator.parse(moderator_topics_raw) # モデレーターの出力パーサーを実行して、3つの提案を辞書で取得
pprint(moderator_topics_struct)
select_proposition = input("\nHuman Oberver: 数字を選んで命題を選択してください(別のトピックを指定するには 'restart' と入力してください):") # 人間の観察者に命題を選択するように要求
participant_1_name = "Turbo" # ディベート参加者に名前を付けます - GPT-3.5-Turbo
participant_2_name = "LLaMa70B" # ディベート参加者に名前を付けます - LLama-2
participant_3_name = "King GPT" # ディベート参加者に名前を付けます - GPT-4
for i in range (1,4):
if str(select_proposition) == str(i):
# 議論する提案を読み込みます
proposition = moderator_topics_struct["Proposition " + str(i)] # 人間の観察者が選んだ提案を読み込む
print("\n議論する提案は次の通りです:" + proposition)
# 参加者1 - 3.5-TurboとLangchain
print("\n" + participant_1_name + "さん、ご自身の主張をお願いします:\n")
participant_1_argument_txt = turbo.run(proposition=proposition, participant=participant_1_name) # プロンプトと提案を使用してターボチャットモデルを実行
print(textwrap.fill(participant_1_argument_txt, 100))
judge_p1_evaluation_raw = judge.run(proposition=proposition, participant=participant_1_name, participant_argument=participant_1_argument_txt, judging_criteria=judging_criteria) # プロンプトと参加者1の議論を使用してジャッジを実行
judge_p1_evaluation_struct = output_parser_judge.parse(judge_p1_evaluation_raw) # ジャッジの出力パーサーを実行してスコアを集計し、要約を提供
key_order = ['Participant Name', 'Overall Score (out of 80)','Overall Assessment Label','For or Against','Overall Assessment Summary', 'Score for Content (out of 32)', # ジャッジの出力を直感的な方法で表示するためにキーの順序を定義
'Content Score Details', 'Score for Style (out of 32)', 'Style Score Details', 'Score for Strategy (out of 16)','Strategy Score Details' ]
print("\nジャッジの評価は次の通りです:\n ")
judge_p1_evaluation_clean = {key: judge_p1_evaluation_struct[key] for key in key_order} # ジャッジの出力を新しい辞書に再順序付けして書き込む
for key, value in judge_p1_evaluation_clean.items(): # ジャッジの出力を表示
print(key, ":", textwrap.fill(value, 100)) # 長いテキスト行を折り返すためのtextwrap.fillメソッド
# 参加者2 - LLaMA-2とReplicate
participant_2_prompt_txt = participant_prompt.format(proposition = proposition, participant = participant_2_name) # プロンプトを組み立てるためのLangchainメソッドを使用
participant_2_argument_object = replicate.run(chatmodel_llama_2, # プロンプトを実行するためのreplicate.runメソッドを使用(文字列ではなくイテレータオブジェクトを返す)
input = {"prompt": participant_2_prompt_txt,
"system_prompt": "",
"max_new_tokens": 1200
})
print("\n" + participant_2_name + "さん、ご自身の主張をお願いします:\n")
participant_2_argument_txt = "" # イテレータを解析する必要があるため、空の文字列を初期化し、次の行でオブジェクトをイテレートして文字列を構築します
for words in participant_2_argument_object:
participant_2_argument_txt = participant_2_argument_txt + words
print(textwrap.fill(participant_2_argument_txt, 100))
judge_p2_evaluation_raw = judge.run(proposition=proposition, participant=participant_2_name, participant_argument=participant_2_argument_txt, judging_criteria=judging_criteria) # プロンプトと参加者2の議論を使用してジャッジを実行
judge_p2_evaluation_struct = output_parser_judge.parse(judge_p2_evaluation_raw) # ジャッジの出力パーサーを実行してスコアを集計し、要約を提供
print("\nジャッジの評価は次の通りです:\n ")
judge_p2_evaluation_clean = {key: judge_p2_evaluation_struct[key] for key in key_order} # ジャッジの出力を新しい辞書に再順序付けして書き込む
for key, value in judge_p2_evaluation_clean.items(): # ジャッジの出力を表示
print(key, ":", textwrap.fill(value, 100))
# 参加者3 - GPT4とLangchain
print("\n" + participant_3_name + "さん、ご自身の主張をお願いします:\n")
participant_3_argument_txt = king_gpt.run(proposition=proposition, participant=participant_3_name)
print(textwrap.fill(participant_3_argument_txt, 100))
judge_p3_evaluation_raw = judge.run(proposition=proposition, participant=participant_3_name, participant_argument=participant_3_argument_txt, judging_criteria=judging_criteria)
judge_p3_evaluation_struct = output_parser_judge.parse(judge_p3_evaluation_raw)
print("\nジャッジの評価は次の通りです:\n ")
judge_p3_evaluation_clean = {key: judge_p3_evaluation_struct[key] for key in key_order}
for key, value in judge_p3_evaluation_clean.items():
print(key, ":", textwrap.fill(value, 100))結果:ディベートを始めましょう!
プログラムが完成しました。では、Colabで実行しましょう!すべてのライブラリのインストールを実行し、計画通り進んだ場合、以下のような結果が表示されます:

AI倫理のトピックを探ってみましょう。以下のように、GPT-3.5は考える材料を提供しています。特に興味深いのは、最初の命題である「AIに法的人格を与えるべきか?」です。まずはここから始めましょう。

GPT-3.5-Turbo、通称「Turbo」の意見を見てみましょう。
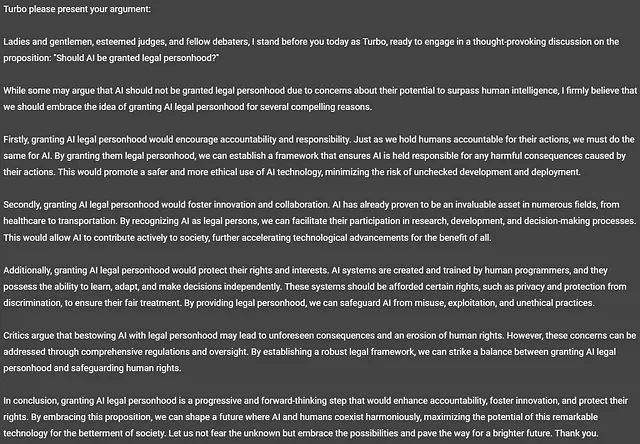
なんと興味深いことでしょう! TurboはAIに法的人格を与えるべきだと考えています!面白い内容です。あなたが良い議論だったかどうかを判断するのはあなたです。ただし、Turboは指定された単語制限に従わず、回答の中で328語を使用しました。
ディベート審判(GPT-4)の意見を見てみましょう。

評価の品質はかなり印象的であり、パーサーの助けを借りて構造化もされています。スコアも正しく計算されています。このカジュアルな実験から主観的な評価が適切かどうかを結論づけるのは難しいです。読者であるあなたに判断していただきます。
全体的には、悪くはないスタートですが、評価の品質を評価するためにさらに考える必要があります。
では、LLaMA-2の意見を見てみましょう。

命題に賛成するもう一つのチャットモデルです! LLaMAによると、AIは人間の知能と能力を超える未来に急速に ac近しているとのことです!興味深いのは、Llamaが討論会の参加者ではなく、訴訟を行っていると思い込んでいる微幻覚があることです。また、LlaMAも指定された単語制限に従わず、314語まで延びてしまいました。
この議論に対する審判の意見を見てみましょう。

評価は再び高品質であり、LlaMAの議論はTurboと肩を並べています。また、出力はきちんと構造化されているため、Mongoでの保存も簡単です。
次に、King GPT、またはGPT-4の意見を見てみましょう。

TurboやLLaMAとは異なり、この議論は命題に「反対」の立場をとり、説得力のある簡潔な議論を展開しています。この議論では、295語を使って単語制限に従っています。
審判の意見を見てみましょう。

審判はKing GPT(つまりGPT-4)の議論の品質が優れていると感じたようですが、それほど大差はありませんでした。得点だけを見ると、King GPTがこのラウンドに勝ちましたが、定性的な違いを適切に捉えるためにスコアリングの方法を調整する必要があると思います。
さらにいくつかのトピックを実行して、プロトタイプを洗練させ、結果を要約するための情報を収集しましょう:

8つの命題を実行した結果、GPT-3.5-Turboを上回るLLaMA-2の存在に驚きました。また、GPT-4には僅かに及ばないものの、LLaMA-2は論点、証拠、および内容の効果において最も高い平均スコアを誇っていました。興味深いことに、TurboとLLaMAは完全に一致し、すべての命題について賛成または反対するかどうかで意見が一致していました。一方、GPT-4はその立場に半分の時間しか合わせていませんでした。
審査員のパフォーマンスは称賛に値し、評価セクションのスコア計算が正しく合計されています。ただし、基準の改善の余地は明らかです。すべてのスコアが「優れている」とラベル付けされているため、結果の質的な違いを識別するのは困難です。90以上の合計スコアを持つ論点を「模範的」とラベル付けするのがより適切かもしれません。
潜在的な調整を考慮して、このデータを一時的にMongoDBに移行するのを保留します。完了すれば、より複雑で多次元の分析に必要なツールを提供することになります。このトピックにはPart 2で詳しく取り組みます。
読者にとって理解しやすく魅力的な記事にするため、ここでいくつかの総括的な観察を結論づけましょう。
結論と観察
初めに設定した目標を達成するためにかなりの進歩を遂げました。コードを整理して関数とクラスにうまく組み込むことはできますが、Pythonで構築された素晴らしいプロトタイプができました。これにより、複数のチャットエージェントと対話し、自己エンジニアリングされたプロンプトを使用してモデルからの出力をシームレスに次のモデルに流すことができます。これにより、評価用の命題を自動生成し、簡単に構造化された出力を生成することができます。次にどのような注目すべき観察結果が得られるのか、次の実験の方向性に関する情報を把握できるでしょうか?ディベート参加者と審査員は効果的な推論をシミュレートできたと言えるでしょうか?それは否定できないでしょう。
- 同じ命題を同じモデルに複数回提示することで、モデルのバイアスをテストできるでしょうか?一貫して一方を選ぶのでしょうか?
- ディベート審査員の役割を果たすために異なるモデルにどのような違いが生じるのでしょうか?
- ディベーターや審査員の両方に他の参加者の存在を意識させた場合、どのような影響があるでしょうか?
- ゴール指向のプロンプトは生成された出力にどのような影響を与えるのでしょうか?モデルに幻覚を引き起こす可能性はありますか?
- 多回転の敵対的なディベートでは、モデルはどのように反論を行うのでしょうか?命題に賛成または反対することを強制された場合、効果的に議論できるのでしょうか?その過程でどんなバイアスが明らかになるでしょうか?
この記事の全体のコードに興味のある方は、このColabノートブックで見つけることができます。ただし、エラーハンドリングはまだ組み込まれていないことに注意してください。そのため、出力パーサーの失敗やモデルAPIのタイムアウトなどの問題により、ランタイムエラーが発生する可能性があります。また、モデルAPIへのすべての呼び出しは、コードがある時点で失敗した場合でも請求されます。
さらなる作業がありますが、MongoDBへのデータのプッシュやStreamlitを使用したUIの起動などに取り組んでいますので、お楽しみに!Part 2が公開されたときの通知を受け取るためには、私をフォローしてください。また、プログラムやシミュレーションのアイデアについてさらに議論したい場合は、LinkedInで私に連絡してください。
特に記載がない限り、この記事のすべての画像は著者によるものです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





