CDCデータレプリケーション:技術、トレードオフ、洞察
CDCデータレプリケーション
多くの業界の組織は、データのほとんどがあまり頻繁に変更されないプロダクションデータベースを運営しています。つまり、データの変更や更新は、全体のデータ量に比べて比較的小さな部分しか占めていません。これらの組織こそが、変更データキャプチャ(CDC)データレプリケーションから最も利益を得ることができます。
本記事では、CDCデータレプリケーションを定義し、一般的な使用事例について簡単に説明し、それぞれの一般的な技術とそのトレードオフについて話します。最後に、データ統合会社DataddoのCEO兼創設者として学んだ一般的な実装の洞察をいくつか紹介します。
変更データキャプチャ(CDC)データレプリケーションとは何ですか?
CDCデータレプリケーションは、リアルタイムまたはほぼリアルタイムでデータを2つのデータベース間でコピーする方法であり、新しく追加されたデータまたは変更されたデータのみがコピーされます。
これは、スナップショットレプリケーションの代替手段であり、スナップショットレプリケーションは1つのデータベースの完全なスナップショットを何度も別のデータベースに移動することを含みます。スナップショットレプリケーションは、データの個別のスナップショットを長期間保存する必要がある組織に適しているかもしれませんが、非常に処理負荷が高く、大きな財務的な負担を残します。これを必要としない組織にとっては、CDCは多くの有料処理時間を節約することができます。
データの変更は、リアルタイムまたは小規模のバッチ(例:1時間ごと)でキャプチャされ、新しい宛先に配信されることができます。
CDCは新しいプロセスではありませんが、最近までは大規模な組織にしか実装するためのエンジニアリングリソースがありませんでした。新しくなったのは、そのコストの一部で実現できる管理ツールの選択肢が増えたことです。
最も一般的なCDCの使用事例
CDCデータレプリケーションの使用事例はすべてを網羅するにはスペースがありませんが、以下に最も一般的な3つを紹介します。
ビジネスインテリジェンスおよび分析のためのデータウェアハウジング
プロプライエタリなデータ収集システムを実行している組織は、おそらくこのシステムからの主要情報を保持するプロダクションデータベースを持っています。
プロダクションデータベースは書き込み操作のために設計されているため、データを収益化するための処理はほとんど行いません。したがって、多くの組織はデータをデータウェアハウスにコピーして、分析とビジネスインテリジェンスのための複雑な読み取り操作を実行したいと考えるでしょう。
分析チームがデータをほぼリアルタイムで必要とする場合、CDCは変更を分析用データウェアハウスに素早く配信する良い方法です。
データベース移行
CDCは、1つのデータベース技術から別の技術への移行時に、すべてのデータを利用可能な状態にしておく必要がある場合にも役立ちます。典型的な例は、オンプレミスのデータベースからクラウドデータベースへの移行です。
災害対策
移行の場合と同様に、CDCは効率的でコスト効果の高い方法で、常に複数の物理的な場所ですべてのデータが利用可能であることを保証するために使用されます。
一般的なCDCの技術とそれぞれのトレードオフ
メインのCDC技術には3つあり、それぞれに利点と欠点があります。

クエリベースのCDC
クエリベースのCDCは非常にシンプルです。この技術では、特定のテーブルからデータを選択するための簡単なSELECTクエリを書き、その後に「昨日に更新または追加されたデータのみを選択する」といった条件を指定します。既に2次テーブルのスキーマが設定されている場合、これらのクエリは変更されたデータを取得し、新しい場所に挿入するための新しい2次元テーブルを生成します。
利点
- 高い柔軟性。変更をキャプチャする方法と、キャプチャする変更の定義を行うことができます。これにより、レプリケーションプロセスを非常に細かくカスタマイズすることが容易になります。
- オーバーヘッドの削減。特定の基準を満たす変更のみをキャプチャするため、すべてのデータベースの変更をキャプチャするCDCよりも安価です。
- トラブルシューティングが容易。個々のクエリは簡単に調査および修正することができます。
欠点
- 複雑なメンテナンス。各個別のクエリをメンテナンスする必要があります。たとえば、データベースに数百のテーブルがある場合、おそらく同じ数のクエリが必要になり、それらをすべてメンテナンスすることは悪夢となります。
- 高いレイテンシ。変更をポーリングすることに依存しているため、レプリケーションプロセスに遅延が発生する可能性があります。これは、選択クエリを使用してリアルタイムのレプリケーションを実現することはできないことを意味し、バッチ処理のスケジュールを行う必要があることを意味します。顧客の行動など、長い時間軸で何かを分析する必要がある場合、これはあまり問題ではありません。
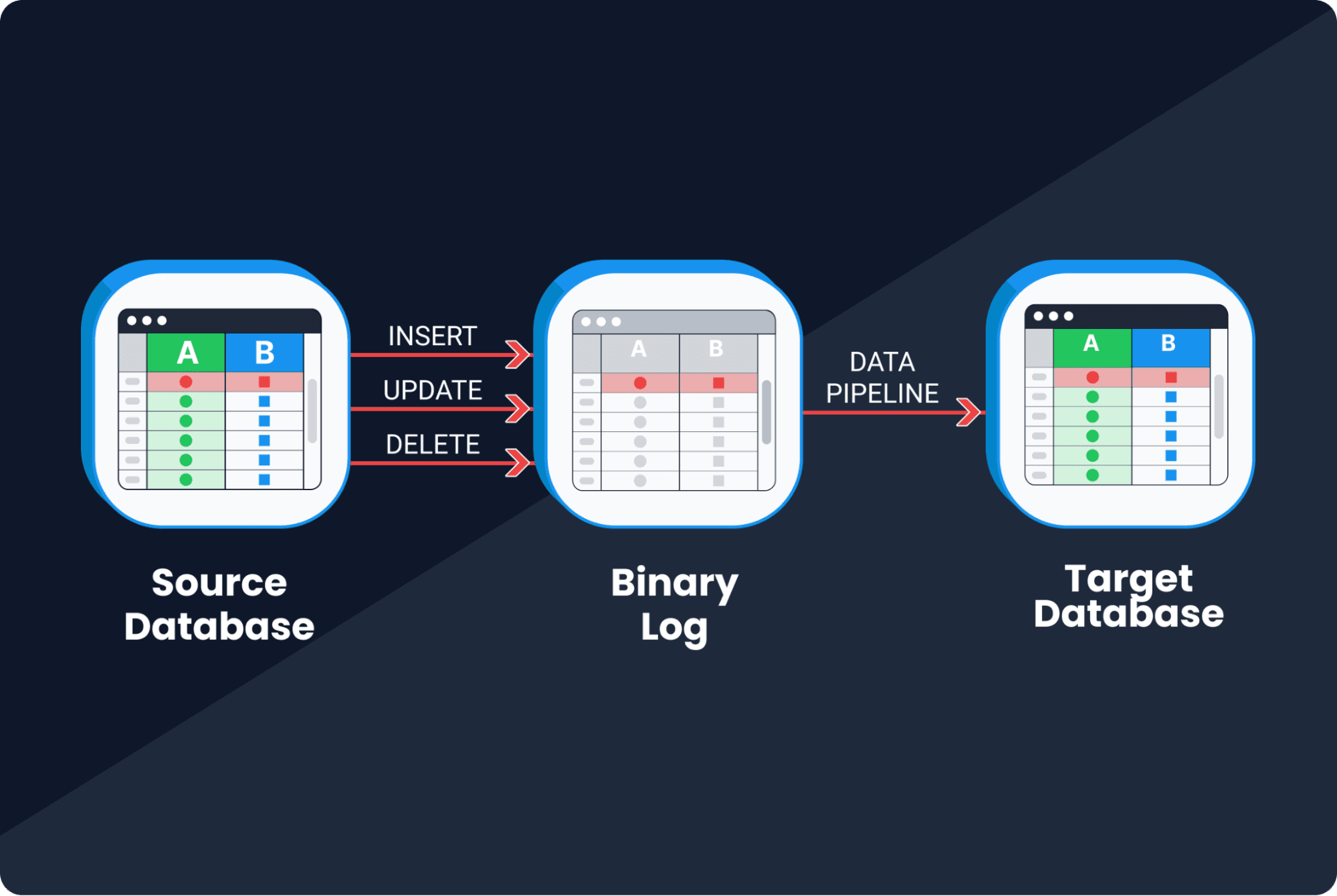
ログベースのCDC
現在使用しているほとんどのデータベース技術はクラスタリングをサポートしており、複数のレプリカを実行して高可用性を実現することができます。これらの技術にはデータベースのすべての変更をキャプチャするバイナリログが必要です。ログベースのCDCでは、変更はデータベース自体ではなくログから読み取り、その後、ターゲットシステムにレプリケートされます。
利点
- 低レイテンシ。データ変更を迅速にダウンストリームシステムにレプリケートすることができます。
- 高い信頼性。ログはデータベースのすべての変更、データ定義言語(DDL)の変更およびデータ操作言語(DML)の変更をキャプチャします。これにより、削除された行を追跡することができます(クエリベースのCDCでは不可能です)。
欠点
- 高いセキュリティリスク。データベースのトランザクションログへの直接アクセスが必要です。これには広範なアクセスレベルが必要となるため、セキュリティ上の懸念が生じる可能性があります。
- 制約のある柔軟性。データベースのすべての変更をキャプチャするため、変更を定義し、レプリケーションプロセスをカスタマイズする柔軟性が制限されます。高度なカスタマイズが必要な場合、ログを大幅に事後処理する必要があります。
一般的に、ログベースのCDCは実装が困難です。詳細については、以下の「インサイト」セクションを参照してください。
トリガーベースのCDC
トリガーベースのCDCは、最初の2つの技術のブレンドと言えます。これは、特定のテーブルの変更をキャプチャするためのトリガーを定義し、それを新しいテーブルに挿入および追跡します。変更はこの新しいテーブルからターゲットシステムにレプリケートされます。
利点
- 柔軟性。クエリベースのCDCと同様に、キャプチャする変更とキャプチャ方法を定義することができます。ログベースのCDCと同様に、削除された行も追跡することができます。
- 低レイテンシ。トリガーが発火するたびに、イベントが発生し、イベントはリアルタイムまたはほぼリアルタイムで処理できます。
欠点
- 非常に複雑なメンテナンス。クエリベースのCDCのクエリと同様に、すべてのトリガーを個別にメンテナンスする必要があります。したがって、データベースに200のテーブルがあり、それらすべての変更をキャプチャする必要がある場合、全体的なメンテナンスコストは非常に高くなります。
実装の洞察
データ統合会社のCEOとして、大規模なスケールと小規模なスケールでCDCを実装する経験があります。以下に、私が過去に学んだいくつかのことを紹介します。
異なるログのための異なる実装
ログベースのCDCは特に複雑です。これは、MySQLのBinLog、PostgresのWAL、OracleのRedo Log、Mongo DBのOplogなど、すべてのログが概念的には同じであるにもかかわらず、異なる実装がされているためです。したがって、選択したデータベースの低レベルパラメータに詳細にアクセスして、動作を確認する必要があります。
データ変更のターゲット宛先への書き込み
ターゲット宛先にデータを挿入、更新、削除する方法を正確に決定する必要があります。
一般的には、挿入は簡単ですが、ボリュームはアプローチを決定する上で重要な役割を果たします。バッチ挿入、データストリーミングを使用するか、ファイルを使用して変更をロードするかを決定するかに関わらず、常に技術的なトレードオフがあります。
適切な更新と不必要な重複を避けるために、テーブルの上に仮想キーを定義する必要があります。これにより、システムに挿入すべきものと更新すべきものが示されます。
適切な削除を保証するためには、悪い実装がターゲットテーブルのデータをすべて削除することを防ぐための何らかの安全装置が必要です。
長時間実行されるジョブの維持
数行のみ転送する場合、非常に簡単ですが、その場合はおそらくCDCは必要ありません。一般的に、CDCジョブは数分または数時間かかることが予想されるため、信頼性のある監視とメンテナンスの仕組みが必要です。
エラー処理
これは別の記事のトピックになる可能性があります。しかし、簡単に言えば、各技術には例外を発生させ、エラーを表示するための異なる方法があります。したがって、接続が失敗した場合にどのように対処するかを定義する戦略を立てる必要があります。リトライするべきですか?すべてをトランザクションにカプセル化するべきですか?
自社内でCDCデータ複製を実装することは非常に複雑で、ケースによって異なります。これが従来人気のある複製ソリューションではなく、実装方法について一般的なアドバイスが難しい理由でもあります。近年では、Dataddo、Informatica、SAP Replication Serverなどの管理ツールが登場し、アクセシビリティの障壁を大幅に下げています。
すべてには向かないが、一部の人にとっては素晴らしい
この記事の冒頭で述べたように、CDCは企業に多くの財務リソースを節約する潜在能力があります。
- 主要なデータベースが頻繁に変更されないデータで主に構成されている場合(つまり、デイリーの変更がデータの比較的小さな部分しか占めていない場合)
- 分析チームがリアルタイムにデータを必要とする場合
- 主要なデータベースの完全なスナップショットを長期保存する必要がない場合
ただし、完璧な技術的な解決策は存在せず、常にトレードオフがあります。CDCデータ複製にも同じことが当てはまります。CDCを実装することを選択する人は、柔軟性、信頼性、遅延、メンテナンス、セキュリティを不均等に優先する必要があります。 Petr Nemethは、クラウドベースのサービス、ダッシュボードアプリケーション、データウェアハウス、データレイクを接続する完全に管理されたノーコードデータ統合プラットフォームであるDataddoの創設者兼CEOです。このプラットフォームは、ETL、ELT、逆向きETL、データベース複製機能(CDCを含む)、および200以上のコネクタの幅広いポートフォリオを提供し、技術的な知識レベルに関係なく、ビジネスプロフェッショナルがほぼすべてのソースから任意の宛先にデータを送信できるようにします。 Dataddoを設立する前、Petrは、インターネット・オブ・シングス、ビッグデータ、ビジネスインテリジェンスに関連する大規模なプロジェクトで、電気通信、IT、メディア企業で開発者、アナリスト、システムアーキテクトとして働いていました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「量子もつれ測定の革命:限られたデータで深層学習が従来の方法を上回る方法」
- 「モンテカルロシミュレーションを通じてA/Bテストのパフォーマンスを理解するための初心者向けガイド」
- 「Langchain Agentsを使用して、独自のデータアナリストアシスタントを作成しましょう」
- 知識グラフ:AIとデータサイエンスのゲームチェンジャー
- 大学フットボールカンファレンスの再編成 – Pythonにおける探索的データ分析
- 『nnU-Netの究極ガイド』
- Google DeepMindの研究者たちは、RT-2という新しいビジョン・言語・行動(VLA)モデルを紹介しましたこのモデルは、ウェブデータとロボットデータの両方から学習し、それを行動に変えます
