CatBoost回帰:分かりやすく解説してください
CatBoost回帰の解説を分かりやすくしてください
CatBoostの内部動作の包括的な(かつ図解された)解説
CatBoost(カテゴリカルブースティング)は、カテゴリカルな特徴量の扱いに優れ、正確な予測を行う強力な機械学習アルゴリズムです。伝統的に、カテゴリカルデータの扱いはかなり難しいものであり、ワンホットエンコーディング、ラベルエンコーディング、または他の前処理技術が必要であり、これらはデータの固有な構造を歪める可能性があります。この問題に対処するために、CatBoostは独自の組み込みエンコーディングシステムである「Ordered Target Encoding」を使用します。
実際にCatBoostがどのように機能するかを見てみましょう。Goodreadsでの平均書籍評価とお気に入りのジャンルに基づいて、誰かが本「Murder, She Texted」をどのように評価するかを予測するモデルを構築します。
6人に「Murder, She Texted」を評価してもらい、それらに関連する他の情報を収集しました。
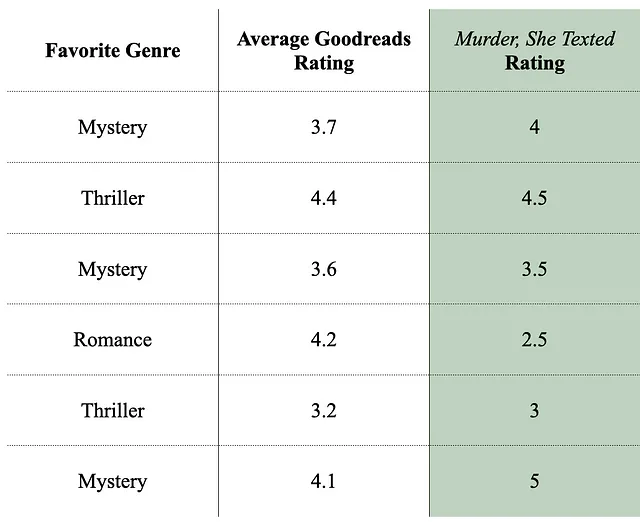
これが現在のトレーニングデータセットであり、データをトレーニングするために使用します。
ステップ1:データセットをシャッフルし、「Ordered Target Encoding」を使用してカテゴリカルデータをエンコードする
カテゴリカルデータを前処理する方法はCatBoostアルゴリズムの中心的な要素です。この場合、カテゴリカルな列は1つだけであり、「お気に入りのジャンル」です。この列はエンコードされ(離散的な整数に変換され)、エンコード方法は回帰問題か分類問題かによって異なります。この場合、予測したい変数「Murder, She Texted Rating」が連続値であるため、回帰問題として扱います。以下の手順に従います。
1 — データセットをシャッフルします:
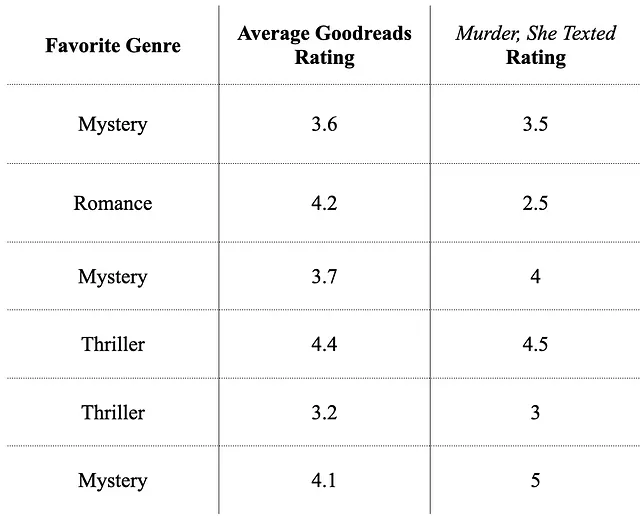
2 — 連続的な目標変数を離散的な「バケット」に入れます:ここではデータが非常に少ないため、同じサイズの2つのバケットを作成して目標変数を分類します(バケットの作成方法の詳細はこちらをご覧ください)。
「Murder, She Texted Rating」の最小値3つをバケット0に入れ、残りをバケット1に入れます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






