BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段
BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段' can be condensed to 'BYOL(Bootstrap Your Own Latent)— 自己教示学習の代替手段
論文分析―Bootstrap Your Own Latent: 自己教育学習への新たなアプローチ
本日の論文分析では、BYOL(Bootstrap Your Own Latent)についての論文に詳しく目を通していきます。この論文は、対照的な自己教育学習技術に代わる表現学習の手法を提供し、大量のネガティブサンプルや巨大なバッチサイズの必要性をなくします。さらに、これはDINOファミリー(DINOv2やGroundingDINOを含む)など、現代の最先端の基礎モデルを理解するための画期的な論文です。
対照的な自己教育学習フレームワークはまだ直感的に感じることが多いですが、BYOLは最初は混乱し、威圧的に感じるかもしれません。そのため、一緒に分析するには素晴らしい論文です。さあ、それを掘り下げて、その核となるアイデアを明らかにしてみましょう!
論文: Bootstrap your own latent: 自己教育学習への新たなアプローチ
コード: https://github.com/deepmind/deepmind-research/tree/master/byol
- 「生成AIにおけるLLMエージェントのデコーディングの機会と課題」
- 「AIとMLが高い需要になる10の理由」 1. ビッグデータの増加による需要の増加:ビッグデータの処理と分析にはAIとMLが必要です 2. 自動化の需要の増加:AIとMLは、自動化されたプロセスとタスクの実行に不可欠です 3. 予測能力の向上:AIとMLは、予測分析において非常に効果的です 4. パーソナライズされたエクスペリエンスの需要:AIとMLは、ユーザーの行動と嗜好を理解し、パーソナライズされたエクスペリエンスを提供するのに役立ちます 5. 自動運転技術の需要の増加:自動運転技術の発展にはAIとMLが不可欠です 6. セキュリティの需要の増加:AIとMLは、セキュリティ分野で新たな挑戦に対処するために使用されます 7. ヘルスケアの需要の増加:AIとMLは、病気の早期検出や治療計画の最適化など、医療分野で重要な役割を果たします 8. クラウドコンピューティングの需要の増加:AIとMLは、クラウドコンピューティングのパフォーマンスと効率を向上させるのに役立ちます 9. ロボティクスの需要の増加:AIとMLは、ロボットの自律性と学習能力を高めるのに使用されます 10. インターネットオブシングス(IoT)の需要の増加:AIとMLは、IoTデバイスのデータ分析と制御に重要な役割を果たします
- 「ChatGPTを再び視覚させる:このAIアプローチは、リンクコンテキスト学習を探求してマルチモーダル学習を可能にします」
初出版: 2020年6月13日
著者: Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko
カテゴリー: 類似性学習、表現学習、コンピュータビジョン、基礎モデル
アウトライン
- コンテキスト&背景
- 主張された貢献
- 手法
- 実験
- 結論
- さらなる読み物&リソース
コンテキスト&背景
BYOLは、類似性学習を介した自己教育表現学習のカテゴリーに属します。自己教育学習とは、明示的な正解ラベルが提供されないが、未ラベルのデータから監督信号を構築することができる手法のことを指します。表現学習とは、モデルが入力を低次元かつ意味的に豊かな表現空間にエンコードすることを学ぶことです。そして、類似性学習では、類似している特徴が潜在表現空間で近くにマップされ、類似していない特徴はより離れた場所にマップされます。これらの表現は、新しいデータの生成、分類、セグメンテーション、単眼の深度推定など、これらの表現に基づいて構築された多くのディープラーニングのタスクにおいて重要です。
CLIP、GLIP、MoCo、SimCLRなど、多くの成功した手法は、対照的な学習アプローチを使用しています。対照的学習では、データのペアの一致スコアが最大化され、非一致データのスコアが最小化されます。このプロセスは、トレーニング中に提供されるバッチサイズとネガティブサンプルの数に大きく依存します。この依存性は、データの収集とトレーニングをより困難にします。
BYOLの目標は次のとおりです。
- 対照的学習に必要なネガティブサンプルと大規模なバッチサイズの必要性をなくすこと。
- ドメイン固有の拡張に依存せず、他のドメイン(言語や画像など)に適用可能にすること。
論文で多くの参照がされている中で、BYOLはmean teacher、momentum encoder、bootstrapped latentsの予測との類似点を強調しています。
主張された貢献(著者による)
- BYOL(Bootstrap your own latent)の導入。これは、対照的学習のようにネガティブペアを必要としない自己教育表現学習手法です。
- BYOLの表現は、最先端の手法(論文発行時点での)を上回ることが示されています。
- BYOLは、バッチサイズや使用される画像拡張に対する依存性が、対照的な手法と比較してより強固であることが示されています。
手法
BYOLが解決しようとする問題を見てきたので、これがどのように実現されているのかを理解しましょう。まず、図1に示されているアーキテクチャを観察しましょう。
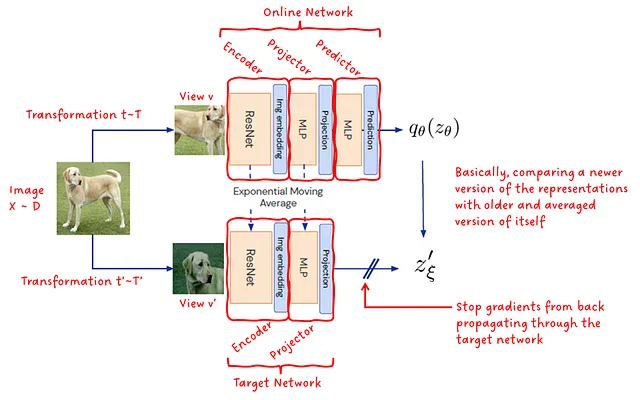
BYOLは、オンラインネットワークとターゲットネットワークの2つのネットワークで構成されています。オンラインネットワークは、エンコーダ、プロジェクタ、およびプレディクタの3つのサブモジュールで構成されています。ターゲットネットワークは、エンコーダとプロジェクタの2つのサブモジュールで構成されています。両方のネットワークのエンコーダとプレディクタは、完全に同じアーキテクチャを共有しており、モデルの重みのみが異なります。オンラインネットワークはトレーニング中に最適化される一方、ターゲットネットワークは自身とオンラインネットワークの指数移動平均によって重みが更新されます。
エンコーダ — エンコーダはResNet畳み込みニューラルネットワークで構成されています。入力画像を潜在表現に変換します。
プロジェクタ — 多層パーセプトロンネットワーク(MLP)を介して、4096次元空間から256次元空間への潜在空間の射影を行います。プロジェクタはフレームワークの動作には重要ではないと思われますが、256は表現学習の分野でよく使用される便利な出力次元です。
プレディクタ — オンラインネットワークの射影された潜在空間からターゲットネットワークの射影された潜在空間を予測することを目指しています。表現の崩壊を回避するために重要です。
トレーニング中、入力画像には2つの異なるランダムに選択された変換が適用され、その画像の2つの異なるビューが構築されます。1つのビューはオンラインモデルに供給され、もう1つのビューはターゲットモデルに供給されます。これらの変換には、サイズ変更、反転、トリミング、カラーの歪み、グレースケール変換、ガウシアンブラー、彩度などが含まれます。トレーニング目標は、両ネットワークの出力間の二乗L2距離を最小化することです。トレーニング後、オンラインネットワークのエンコーダのみが最終モデルとして保持されます!
以上です。簡単ですね? 😜 まあ、論文を読んだ後、私の顔はもっとこうなっていました: 😵 フレームワークの処理をキーコンポーネントに分解すると、比較的簡単に理解できる場合でも、直感を得るためにはかなりの時間がかかりました。
実際になぜBYOLが機能するのかを理解しようとする前に、提示された方程式を簡略化し、謎を解き明かしましょう。
数学の解説
BYOLのアーキテクチャとトレーニング方法の概要を把握したので、方程式を詳しく見てみましょう。論文で提示された数学的なパートは必要以上に複雑です。場合によっては複雑過ぎる表現があり、他の場合は明確さに欠けており、解釈の余地があり、混乱を引き起こします。
何が起こっているかを理解するために重要だと思われる方程式に焦点を当てます。なぜなら、なぜそうなるのかを解析するのも面白いからです 😜
まず、トレーニング中のモデルのパラメータの更新について話しましょう。オンラインモデルとターゲットモデルの2つのモデルがあることを思い出してください。オンラインモデルは、LARSオプティマイザを使用して損失関数を最適化することでパラメータを更新します。

上記の方程式は単に「現在のパラメータ、パラメータに関する損失関数の勾配、および学習率etaに基づいて、オプティマイザ関数を呼び出してモデルのパラメータthetaを更新する」と言っています。
一方、ターゲットモデルは最適化による更新ではなく、オンラインモデルから重みをコピーし、コピーされた更新された重みとターゲットネットワークの現在の重みに対して指数移動平均を適用することで更新されます。

上記の方程式は単に「現在の重みxiとオンラインモデルの更新された重みを、減衰率tauでの指数移動平均を計算してモデルのパラメータxiを更新する」と言っています。tauはトレーニング全体でオンラインモデルの寄与を減少させるためにコサインスケジュールに従います。
さて、オンラインモデルを更新するために使用される損失関数を見てみましょう。この損失関数は、他の2つの損失関数の合計として定義されています。これらの損失は後で見るように同じ方程式を共有していますが、ネットワークの2つの異なる入力に対して計算されます。図1から、イメージxから異なる変換を適用して2つの異なるビュー(vとv’)が生成されることを思い出してください。1つのビューはオンラインモデルに入力され、もう1つはターゲットモデルに入力されます。トレーニング中には、損失を計算する前に2つのフォワードパスが実行され、ネットワークへの入力が交換されます。オンラインモデルへの画像入力はターゲットモデルに入力され、その逆も同様です。
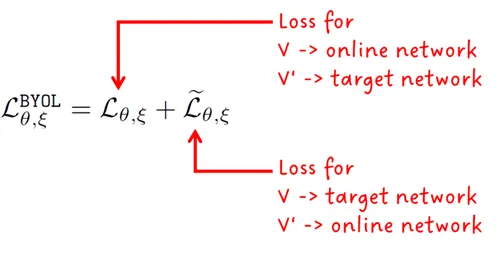
個々のフォワードパスの損失は、オンラインモデルとターゲットモデルのL2正規化された出力の二乗L2距離です。論文から対応する方程式を詳しく見てみましょう:
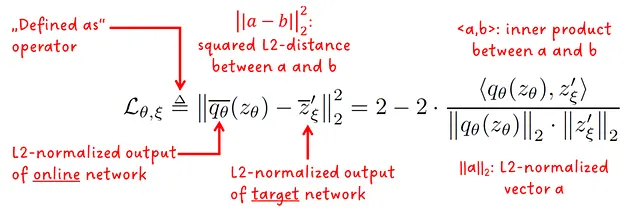
注:論文ではこれを平均二乗誤差と述べていますが、実際には正しくありません。L2距離は要素数で割りません。おそらく、バッチ全体で平均を計算することと混同したのだと思います。
BYOLの直感
フレームワークと方程式の主要なメッセージの理解を持っている今、いくつかの直感を得てみましょう。著者の意見を紹介し、それに自分なりの直感を加えてみますが、正確であるとは限りません🤡。
BYOLはどのように表現を学習するのですか? – モデルは、同じオブジェクト/シーンの2つの異なるビューを表す2つの入力の同じ潜在表現を生成するように促されます。猫は、ぼやけているか、グレースケールになっているか、反転しているかに関係なく、猫のままです。実際には、重い変換がここで重要です。モデルに対して、「これらは同じものの異なる変化です。したがって、オブジェクト/シーンの表現を抽出する際にこれらの変化を無視し、等しいと考えてください!」と伝えるのです。
なぜ表現は崩壊しないのですか? – BYOLは、先ほど言ったように類似性学習のカテゴリに属しています。最も類似性を高めるためにネットワークが単に潜在空間ですべてを同じ点にマッピングするのは、最も簡単な方法ではないでしょうか?実際、これは類似性学習の主な困難の1つであり、「崩壊した解」と呼ばれています。コントラスティブ学習アプローチは、類似した特徴を近くの位置にマップし、類似していない特徴を遠くにマップすることでこの問題を解決します。BYOLは、オンラインネットワークとターゲットネットワークの間に予測サブモジュールに非対称性を導入し、指数移動平均に基づくターゲットネットワークパラメータの更新規則を用いて、トレーニング中に予測子の近い最適性を確保することで、この問題を解決します。
実験
BYOLの著者は、自身の手法の有効性を示すために実験と削減を行いました。
バッチサイズによる削減
コントラスティブ表現学習方法(例:CLIPとGLIP)からは、トレーニング中のバッチサイズに大きく依存することがわかっています。たとえば、CLIPは32,768のバッチサイズでトレーニングされており、これは多モーダルな言語-画像モデルであることを考慮すると、驚くべきことです。
著者は、BYOLはネガティブサンプルを必要としないため、低いバッチサイズに対して敏感ではないと主張しており、その主張は図2に示されている以下の実験で支持されています。
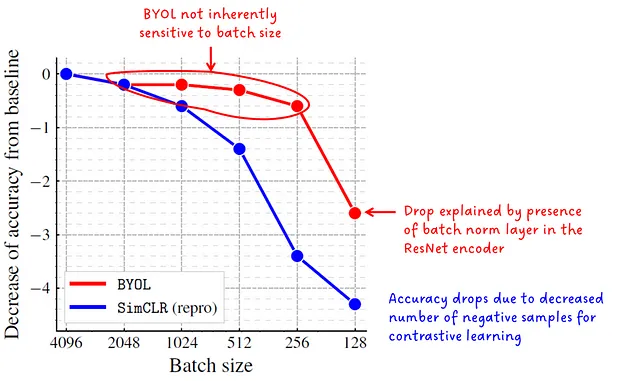
残念ながら、これは私のプライベートラップトップにとってもまだ大きすぎるかもしれません 😅
画像拡張の頑健性に関する消去法
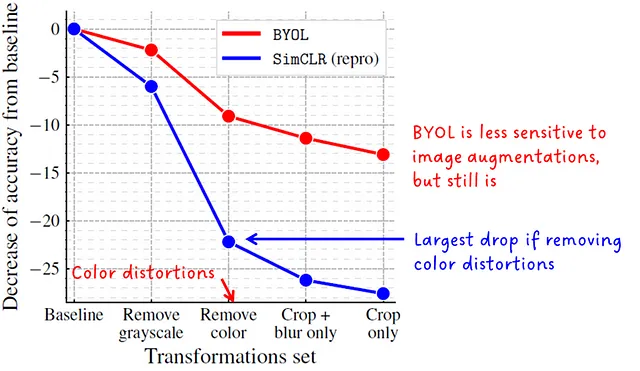
SimCLRの論文では、対比的なビジョン手法が画像拡張の選択に敏感であり、特に色のヒストグラムに影響を与えるものです。同じ画像の切り抜きは似たような色のヒストグラムを共有しますが、負のペアの切り抜きはそうではありません。モデルは訓練中にショートカットを取り、意味的な特徴ではなく色のヒストグラムの差異に焦点を当てることができます。
著者らは、オンラインネットワークとターゲットネットワークの更新方法のため、BYOLは画像拡張の選択に対してより頑健であると主張しています。この仮説は実験によって裏付けられていますが、依然として強い依存関係があり、したがって性能が低下します。
ImageNetでの線形評価
表現学習の分野では、モデルの特徴を意味的に豊かな特徴に変換し、類似した特徴をクラスタリングし、非類似な特徴を分離する能力が重要な特徴です。一般的なテストは、モデルを凍結し(BYOLの場合はオンラインモデルのエンコーダーのみ)、表現の上に線形分類器をトレーニングすることです。
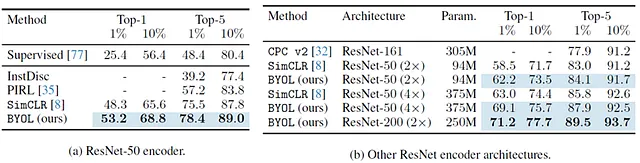
BYOLの線形評価はImageNetで行われ、他の多くのモデルと比較され、当時の従来の最先端モデルを上回っています。
多くの論文で、ResNet-50エンコーダーとその他のResNetのバリエーションの区別がされています。ただし、ResNet-50はパフォーマンス評価の標準ネットワークとして浮上してきたというだけです。

分類のための半教師付き微調整
表現学習におけるもう1つの非常に典型的な実験設定は、特定の下流タスクとデータセットに微調整されたモデルの性能です。
Table 2は、1%または全体のImageNet訓練セットの10%を使用して分類タスクでBYOLを微調整した場合のメトリックを示しています。
他のビジョンタスクへの転移
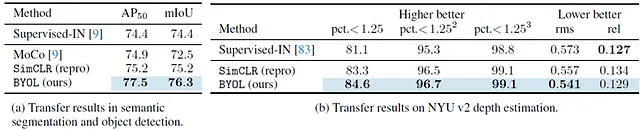
著者らは、BYOLをセマンティックセグメンテーションタスクと単眼深度推定タスクに転移学習させた実験も紹介しています。これはコンピュータビジョンのもう2つの重要な分野です。
以前のアプローチとの違いはわずかですが、ここでの主要なメッセージは「同じようにうまく機能する異なるアプローチを持っています」ということです。
結論
BYOLは自己教師あり表現学習の代替手法を提案しています。BYOLは、対比的な学習アプローチに必要な負のトレーニングサンプルの必要性なしに、類似性学習を実行する2つのネットワークを実装することでトレーニングできます。崩壊する解決策を避けるために、ターゲットネットワークはオンラインネットワークからの指数移動平均(EMA)を介して更新され、オンラインネットワークの上に追加の予測サブモジュールが構築されます。
さらなる読み物とリソース
ここまで来たら、おめでとうございます🎉、そしてありがとうございます😉!このトピックに非常に興味をお持ちのようですので、以下にいくつかの追加リソースをご紹介します:
以下はBYOLに基づいた論文のリストです:
- DINO:自己教師付きビジョン変換の新たな特性
- DINOv2:教師なしで堅牢な視覚特徴を学習する
- Grounding DINO:オープンセット物体検出のためのGrounded Pre-Trainingとの結合
以下は自己教師付き表現学習のコントラスティブ学習手法CLIPとGLIPに関する私の2つの記事です:
CLIP Foundationモデル
論文概要:自然言語教示から転移可能な視覚モデルの学習
towardsdatascience.com
GLIP:言語画像プリトレーニングを物体検出に導入する
論文概要:グラウンデッド言語画像プリトレーニング
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles